云原生場景下如何利用Ray快速構(gòu)建分布式系統(tǒng)

一、分布式系統(tǒng)復(fù)雜性
1、一個AutoML的case
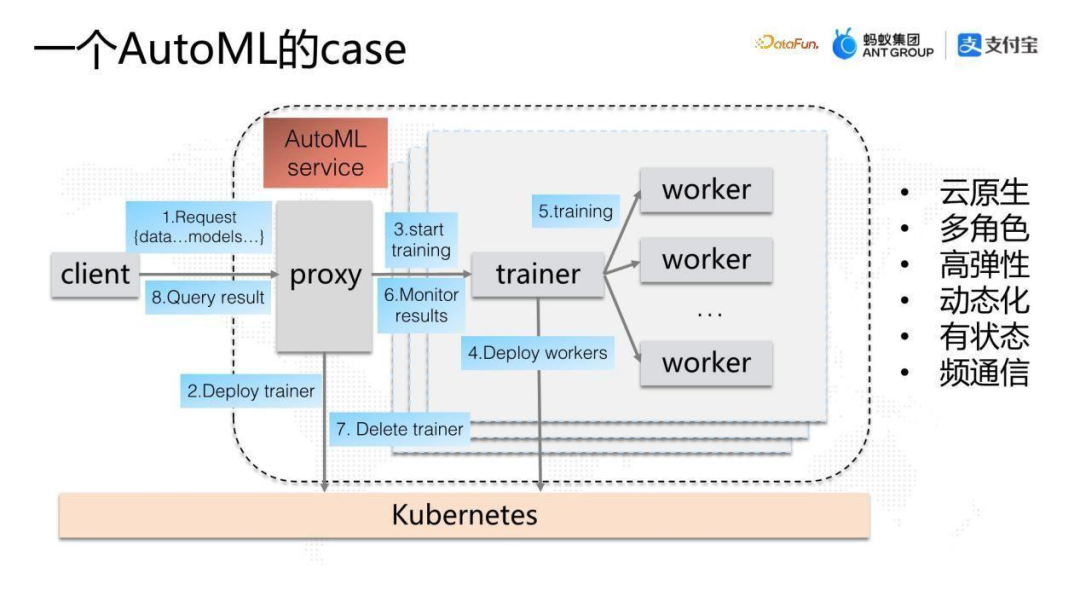
首先從一個實例開始,上圖是我們最近構(gòu)建的AutoML的例子,搭建自動分布式機器學習的服務(wù)。
圖中虛線框起來的就是這個自動機器學習的服務(wù),服務(wù)中有如下幾個角色:proxy是一個常駐服務(wù),在整個AutoML集群中負責提供服務(wù)的入口,會根據(jù)不同的AutoML的任務(wù)創(chuàng)建小方框的訓練集群;小方框中又有兩個角色,trainer和worker,trainer 是類似協(xié)調(diào)器的角色,協(xié)調(diào)一個完整的AutoML任務(wù),在協(xié)調(diào)過程中不斷地創(chuàng)建worker來完成整個AutoML的計算。
集群外部通過client接入AutoML服務(wù),將AutoML需要的models和data組合發(fā)到proxy,proxy根據(jù)用戶請求創(chuàng)建trainer,當然在這個過程當中需要通過K8S管理資源來創(chuàng)建trainer的Pod或者process,trainer會通過解析client 端的這個models和data計算需要多少個worker,同樣通過K8S創(chuàng)建出對應(yīng)的worker,開啟整個訓練任務(wù)。
每個worker訓練完成后,trainer收集結(jié)果,檢測整個AutoML任務(wù)是否完成,最后把結(jié)果返回給proxy,返回結(jié)果后,trainer和worker會被銷毀。

這是一個比較完整的AutoML Service服務(wù),可以看到其特點為:云原生、多角色、高彈性、動態(tài)化、有狀態(tài)、頻通信。高彈性主要體現(xiàn)在proxy和trainer兩個角色中,他們都會在runtime的過程中不斷地去申請資源。
2、技術(shù)棧分析

接下來探討一下如果在云原生環(huán)境實現(xiàn)這個case,需要考慮哪些事情?下面從兩個方面進行分析。
從技術(shù)棧角度,假設(shè)當前是AI應(yīng)用場景,主要編程語言是Python。首先需要開發(fā)單體應(yīng)用,包括proxy、trainer、worker幾個角色。在單體應(yīng)用的編寫中:
- 調(diào)度方面,選擇協(xié)程asyncio管理進程的event loop來構(gòu)建整個單體應(yīng)用。
- 通信方面,選擇使用protobuf 定義各個組件的之間的通信協(xié)議,如 proxy、trainer和worker 之間需要傳遞哪些字段,通過 gRPC 完成整個通信過程。
- 存儲方面,需要考慮應(yīng)用以及業(yè)務(wù)邏輯設(shè)計角色的內(nèi)存結(jié)構(gòu),如果業(yè)務(wù)邏輯比較復(fù)雜還需要引入本地存儲如RocksDB,更復(fù)雜的情況還需要引入遠程分布式存儲如HDFS。
- 部署方面,為了部署分布式系統(tǒng),需要考慮Docker,需要定制各個組件的運行時環(huán)境,需要了解Kubernetes,知道如何在 Kubernetes 環(huán)境創(chuàng)建這些應(yīng)用的實例。更復(fù)雜的情況下,如果中間需要一些彈性的過程,需要開發(fā)K8s標準的 operator來輔助完成整個分布式系統(tǒng)的構(gòu)建。
- 監(jiān)控方面,系統(tǒng)運行以后,需要接入監(jiān)控系統(tǒng),常規(guī)選擇Grafana+Prometheus的組合來實現(xiàn)系統(tǒng)的可監(jiān)控性、可運維性,達到生產(chǎn)要求。
3、編程語言分析
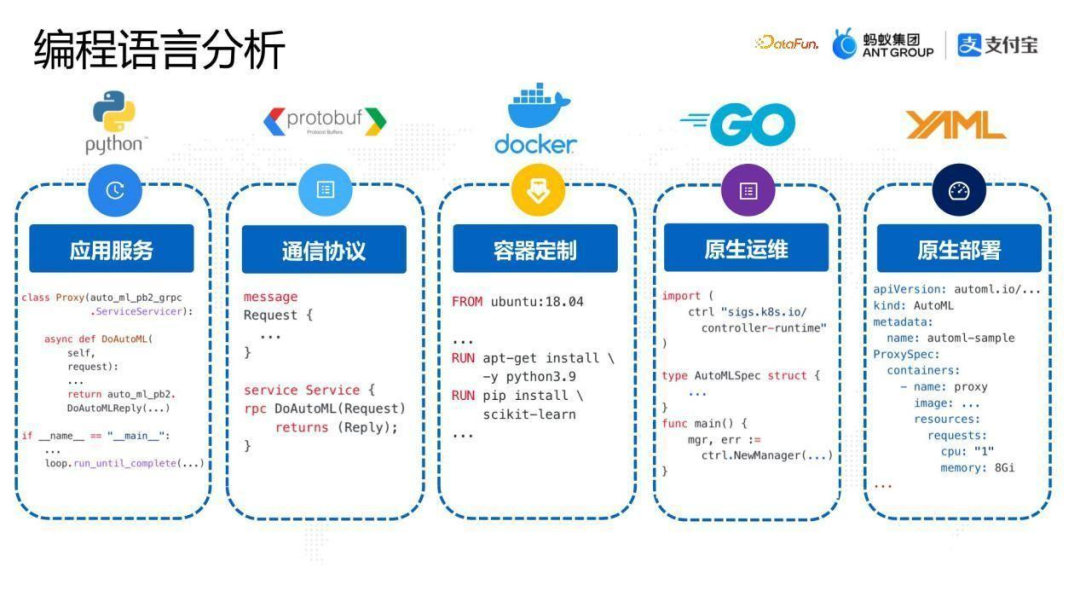
從編程語言角度,為了實現(xiàn)上面的分布式系統(tǒng),需要應(yīng)用下面的編程語言:
- Python,是必不可少的,用于實現(xiàn)應(yīng)用的內(nèi)部邏輯。
- Protobuf,通過proto語言定義應(yīng)用的通信協(xié)議,通過codegen的方式生成各種語言的SDK library,實現(xiàn)通信 gRPC 的接入。
- Docker,通過Dockerfile定義應(yīng)用中的每個組件的差異化需求,比如worker可能需要一個可以跑GPU 的Python 環(huán)境,可能需要定制Python環(huán)境的版本以及依賴包,還可能需要定制更加native 的環(huán)境,比如library 或者操作系統(tǒng)版本的定制。
- Go,對于比較復(fù)雜的分布式系統(tǒng),原生運維方面的開發(fā)也是比較重的,比如我們的case中,需要開發(fā)一個K8s operator,operator的業(yè)務(wù)邏輯需要用 go 語言編寫。
- YAML,原生部署中,YAML代碼的使用是非常多的。系統(tǒng)中最終部署的參數(shù),比如container 的規(guī)格、pod 的規(guī)格、其他一些 label 都需要通過 YAML 的形式定制。
以上就是常規(guī)思路實現(xiàn)分布式系統(tǒng)需要考慮的技術(shù)棧以及編程語言。
4、分布式系統(tǒng)通用能力

我們可以看到整個云原生環(huán)境下分布式系統(tǒng)的構(gòu)建是非常復(fù)雜的。但是經(jīng)過分析可以看到,很多需要研發(fā)和維護的邏輯是通用的分布式系統(tǒng)的邏輯,跟實際的業(yè)務(wù)邏輯沒有直接的關(guān)系。比如上面提到的AutoML的case,業(yè)務(wù)或者系統(tǒng)的開發(fā)同學更關(guān)注AutoML本身的邏輯。那么,是否有一個系統(tǒng),能夠?qū)⒎植际较到y(tǒng)的通用能力全部解決,使得系統(tǒng)或者業(yè)務(wù)的研發(fā)團隊能夠?qū)W⒂跇I(yè)務(wù)邏輯本身呢?Ray的出現(xiàn)就是為了解決這個問題。
二、Ray簡介
在正式分享如何利用Ray來構(gòu)建分布式系統(tǒng)之前,先對Ray做一個簡要的介紹。
1、About Ray

首先從Ray在github上star數(shù)的發(fā)展來看,從2016年中開源到現(xiàn)在經(jīng)歷了兩個里程碑,左上圖中紅線是Ray的star數(shù)歷史數(shù)據(jù),在2021年Ray的star 數(shù)已經(jīng)超過了Flink,2023年5月迎來了另一個里程碑:超過了Kafka,目前距離Spark 的star數(shù)還有一定的距離,從star數(shù)的角度看,Ray的發(fā)展非常迅速。
右上是一張 Google 的PATHWAYS論文的截圖,PATHWAYS在 Google 內(nèi)部實際被看作是下一代 AI 的基礎(chǔ)架構(gòu),在這篇論文中多次提到了Ray,認為Ray實際上非常有可能成為該基礎(chǔ)架構(gòu)中的分布式計算框架。
右中是最近被大家熟知的大語言模型公司OpenAI的信息,OpenAI在今年公開了GPT3.5和GPT4的分布式訓練的部分細節(jié),底層也是通過Ray來構(gòu)建整個分布式系統(tǒng)的。
左下是2022年Ray社區(qū)做的偏向大數(shù)據(jù)領(lǐng)域的一項工作,利用云上的資源做數(shù)據(jù)排序,應(yīng)用shuffle的能力,這套排序系統(tǒng)打破了世界記錄,首次達到每TB 小于$1的成本(0.97$)。
右下是Ray社區(qū)近期在離線推理Batch Inference方面的一項工作,對比了Ray 和其他現(xiàn)有的方案,通過Ray進行數(shù)據(jù)處理,實現(xiàn)一個pipeline流程給訓練系統(tǒng)提供數(shù)據(jù),相比Spark,在Throughput方面有兩到三倍的提升。
通過上面的信息,大家可以對Ray有一個high level的認知。
2、Ray是什么

Ray 是由加州大學伯克利分校RISELab實驗室發(fā)起的一個開源項目,RISELab實驗室在業(yè)界非常知名,Spark 也發(fā)源于這個實驗室。
Ray是一個通用的分布式計算引擎,由于Ray的通用性,很可能會成為新一代的計算技術(shù)設(shè)施。在分布式領(lǐng)域,由于Ray的整個生態(tài),在 AI 領(lǐng)域更是可能成為統(tǒng)一的編程框架,這部分會在后面的開源生態(tài)部分做進一步介紹。
3、通用分布式編程API

Ray 的通用性體現(xiàn)在哪里呢?實際上通過查閱Ray Core的API,可以看出Ray的設(shè)計思想是不綁定任何計算模式,把單機編程中的基本概念分布式化。
從API 的設(shè)計可以看出,Ray并不是一個大數(shù)據(jù)系統(tǒng),尤其是Ray Core這一層沒有任何大數(shù)據(jù)相關(guān)的算子,而是從單機編程的基本概念進行分布式化的。

具體如何分布式化?我們在單機編程中經(jīng)常用到兩個非常核心的概念,一個叫Function,一個叫Class,在面性對象的編程語言里面,基本上大家會圍繞這兩個概念進行代碼開發(fā),在Ray中會將這兩個基本概念進行分布式化,對應(yīng)到分布式系統(tǒng)就叫Task和Actor。
4、通用分布式編程API:無狀態(tài)計算單元Task
首先解釋一下Task。Task是對單機編程中的Function進行分布式化,是一個無狀態(tài)的計算單元。
上圖是一個例子,有一個叫 heavy_compute的Function,它是一個CPU 密集型的運算,在單機內(nèi),如果要對它進行1萬次運算,比如在單核里面會有左邊的代碼,一個簡單的for loop;如果需要用到多核的能力,就需要用到多線程或者多進程。而在Ray里面,如果想利用多機的能力,要將function 進行分布式化,整個流程非常簡單,只需要三步, 如右圖所示。
- 首先給單機的function加一個decorator(@ray.remote),標注該function是可以遠程執(zhí)行的。
- 然后在調(diào)用該function 時,同樣加一個.remote以及需要的參數(shù),這樣該function就會被調(diào)度到遠程節(jié)點的某個進程中執(zhí)行。
- 最后可以通過ray.get獲取最終的運算結(jié)果。
可以看出,整個分布式的過程非常簡單,而且編程的整個框架和流程也沒有打破單機編程的習慣,這也是Ray整個核心 API 的一個核心能力,給編程者提供最大的便利性。
5、通用分布式編程API:分布式object

下面看一下Ray中object的概念。講object的原因是想讓大家理解一下為什么Ray可以把heavy_compute Function運行到另外一個節(jié)點并且可以把結(jié)果拿回來,這依賴于Ray底層的分布式object store。整體流程如上圖左側(cè)所示。
我們在Node 1運行heavy_compute function,這個 function 會使用remote通過Ray底層的調(diào)度系統(tǒng)調(diào)度到Node 2, Node 2會執(zhí)行這個function,執(zhí)行完成后,把結(jié)果put到本地的object store中,object store 是Ray中的一個核心組件,最終結(jié)果返回到Caller端是通過Ray底層的 object store之間的object傳輸,把結(jié)果返回來給Caller端。
從整個的流程看, heavy_compute.remote 返回的是一個ObjectRef,并不是最終的結(jié)果。ObjectRef類似于單機編程中的future,只不過它是分布式的future,可以通過ray.get獲取最終結(jié)果。
Ray的分布式 object store是非常核心的組件,完美支撐了Ray整套分布式API 的設(shè)計,其特點如下:
- 可以實現(xiàn)多節(jié)點之間object 傳輸。
- 同節(jié)點內(nèi)是基于shared memory的設(shè)計,在此基礎(chǔ)上,分布式系統(tǒng)的online傳輸,如果發(fā)生在單機兩個進程之間的話,理論上可以達到 Zero Copy 的效果。
- Ray object store 有一套比較完整的自動垃圾回收機制,可以保證分布式系統(tǒng)運算過程中一旦有ObjectRef在系統(tǒng)中沒有引用的時候,會觸發(fā)對該object 進行GC。
- Object store有object spilling 的功能,可以自動將內(nèi)存中的object spill到磁盤上,從而達到擴容整個分布式系統(tǒng)存儲的目的。
6、通用分布式編程API:有狀態(tài)計算單元Actor
上面講解了Task 和object,接下來介紹一下Actor。Actor 也是非常簡單的,是將單機編程的Class概念進行分布式化。
左圖有一個Counter 類,是一個有狀態(tài)計算單元,將它進行分布式化,如右圖所示。
- 首先加一個decorator,把它變成可以在遠程部署的Actor;
- 通過.remote,把該Actor進行調(diào)度部署,在另外一臺機器的另外一個節(jié)點上面去實例化這個class;
- 調(diào)用時與Task一致,可以直接調(diào)用這個Actor的某個方法,通過.remote實現(xiàn)遠程調(diào)用。
三、利用Ray快速構(gòu)建分布式系統(tǒng)
以上介紹了Ray的幾個核心概念,接下來看一下剛剛講的case,怎么利用Ray來構(gòu)建這個分布式系統(tǒng)。
1、AutoML Service——部署Ray集群

Ray 是一個集群化服務(wù),有兩種部署方式。
- 第一種是一鍵云上部署,通過ray up命令,填入一些配置,在任何一個主流云廠商或者標準的Kubernetes環(huán)境或者Hadoop Yarn環(huán)境都可以進行一鍵部署。部署完成后還可以自動對云上資源進行彈性調(diào)度,根據(jù)計算的runtime的情況做Autoscaling,盡可能利用云上資源完成整個分布式系統(tǒng)的計算。
- 第二種是自定義部署,如果是非標環(huán)境,則需要自定義部署,可以使用 ray start 命令分別啟動head節(jié)點和worker節(jié)點,完成手動的組網(wǎng)。
2、AutoML Service

有了Ray集群以后,我們回到之前AutoML的架構(gòu)圖,這里已經(jīng)加入了Ray系統(tǒng),利用Kubernetes+Ray,如何實現(xiàn)這個分布式系統(tǒng)呢?
在用戶看來,實際上已經(jīng)看不到K8s這層資源了,通過剛才的介紹大家很容易想到實現(xiàn)的思路,就是利用Ray的Actor 和Task去分析一下整個系統(tǒng)哪些是有狀態(tài)計算單元,哪些是無狀態(tài)計算單元,然后對它進行分布式化。
- proxy和 trainer 是兩個有狀態(tài)的計算單元,需要用Ray的Actor 進行實現(xiàn)。
- worker在跑完一個任務(wù)之后就退出了,所以沒有狀態(tài),使用Ray的Task進行實現(xiàn)。
- client由于在Ray集群之外,可以使用Ray的client 工具接入整個 Ray的集群服務(wù)。
下面簡要講解一下,上面架構(gòu)圖從右到左整個Service系統(tǒng)是怎么實現(xiàn)的。
3、AutoML Service—worker (Ray Task)

worker是一個Task,所以需要封裝一個function。function train_and_evaluate的主要邏輯是拿到model、訓練數(shù)據(jù)集和測試數(shù)據(jù)集,完成單機的訓練和評估,上面是已經(jīng)抽象成單機的計算。然后通過ray.remote 把它變成一個Task。
4、AutoML Service—Trainer (Ray Actor)

Trainer需要對多個 worker進行調(diào)度,通過把不同任務(wù)調(diào)到不同 worker 上面并收集結(jié)果完成單個AutoML請求的計算過程。
首先有一個Trainer 類封裝整個Trainer的業(yè)務(wù)邏輯。然后通過ray.remote 把它變成一個Actor,Trainer的train的方法通過兩層loop實現(xiàn)對多個worker的調(diào)度,實際上是對上面實現(xiàn)的worker的train_and_evaluate function的remote 執(zhí)行,這樣就能在分布式系統(tǒng)中實現(xiàn)并發(fā)計算,并發(fā)計算完成后,Trainer收集結(jié)果并返回給proxy。
5、AutoML Service—Proxy (Ray Actor)

proxy是對外服務(wù)的入口,定義兩個function:
- 一個是do_auto_ml,用戶的請求調(diào)度到該function上會觸發(fā)部署一個Trainer的Actor,然后再調(diào)用該Actor 的 train方法來觸發(fā)整個AutoML的計算。
- 另一個是 get_result,可以方便客戶端Ray Client查詢計算結(jié)果。
這里值得注意的是,在部署 proxy 的時候需要設(shè)置一個name,用于服務(wù)發(fā)現(xiàn)。
6、AutoML Service—Client

用Ray Client 接入的時候,任何一個AutoML用戶拿到Client,先通過ray.get_actor傳入上面的actor name就可以獲得proxy的句柄,然后可以通過proxy的句柄調(diào)用proxy方法從而實現(xiàn)AutoML的接入,最后通過調(diào)用proxy 的get_result拿到最終的運算結(jié)果。
7、AutoML Service—定制資源

接下來介紹一些細節(jié)。
第一個細節(jié)是資源定制。
在純云原生的實現(xiàn)思路中,如果沒有Ray,資源定制是寫到 yaml 里邊的。比如說訓練需要多少GPU 或者計算節(jié)點需要多少CPU,都是在 yaml 中定制 container 的規(guī)格。
Ray提供了另外一個選擇,完全無感知的代碼化的配置,用戶可以在 runtime 的時候,或者在Ray的Task 或 Actor 的decorator 中加一個參數(shù),就可以通過Ray系統(tǒng)的調(diào)度能力分配相應(yīng)的資源,達到整個分布式系統(tǒng)資源定制的目的。
Ray的資源定制除了支持GPU、CPU、Memory 之外,還可以插入自定義資源。然后Ray的調(diào)度還有一些高級功能,比如資源組,或者親和性和反親和性的調(diào)度,目前都是支持的。
8、AutoML Service—運行時環(huán)境

第二個細節(jié)是運行時環(huán)境。
在分布式系統(tǒng)中,往往不同分布式系統(tǒng)的組件對環(huán)境的要求是不一樣的。如果使用常規(guī)思路,就需要把環(huán)境固化到image里面,通過 Dockerfile 去定制環(huán)境。
Ray實現(xiàn)了更靈活的選擇,也是代碼化的,可以在runtime創(chuàng)建Task或Actor之前的任意時刻定制指定計算單元的運行時環(huán)境。上圖中給worker 的 Task 設(shè)定一個runtime_env,定制一個專屬的Python版本,并在該版本里面裝入一些pip包,完成面向Python的隔離環(huán)境的定制。這時Ray集群內(nèi)部會在創(chuàng)建這個Task之前去準備該環(huán)境,然后將該Task調(diào)度到該環(huán)境執(zhí)行。
Ray的運行時環(huán)境是插件化的設(shè)計,用戶可以根據(jù)自己的需求實現(xiàn)不同的插件,在Ray中原生支持了一些插件如Pip、Conda、Container等,只要是跟環(huán)境相關(guān),不只是代碼依賴,也可以是數(shù)據(jù)依賴,都可以通過插件去實現(xiàn)。
右下圖從運行時環(huán)境這個角度看,以Python為例,隔離性的支持力度有如下幾個維度,一個是 Process 級別的隔離,第二是 Virtual env 級別的隔離,第三是 Conda 級別的隔離,最后是 Container級別隔離。
從隔離性來說,從右到左是由弱到強的,Process 的隔離性是非常弱的,Container 隔離性是更強的。
從用戶體驗來說,環(huán)境定制上 Container 是更重的而Process 是更輕的。
所以在Ray中用戶可以根據(jù)自己的環(huán)境定制的需求選擇需要定制的環(huán)境的粒度。有些人需要完全的Container 級別的隔離,有些人Process 級別的隔離就足夠了,可以根據(jù)自己的需求進行選擇。
9、AutoML Service—運維與監(jiān)控
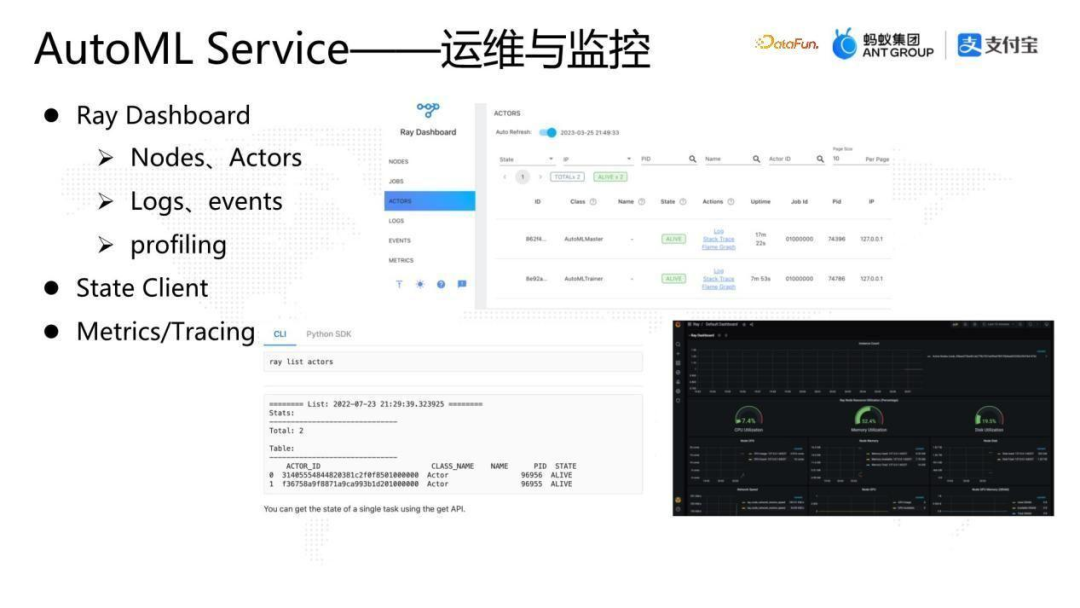
第三個細節(jié)是運維與監(jiān)控。
Ray提供了 Ray Dashboard。Ray dashboard實現(xiàn)了整個Ray集群包括Ray Nodes、Ray Actors等各種維度信息的透出;另外,還有集群內(nèi)的Logs和events,比如某個Actor的某個方法執(zhí)行異常,Ray會把堆棧通過 event收集到dashboard中,方便迅速定位問題;除此之外還有profiling 工具,Ray dashboard 可以支火焰圖,還可以一鍵看到任意一個Actor或Task的進程狀態(tài)或者堆棧。
除了Ray dashboard,Ray還提供了黑屏化的Ray State Client,同樣可以通過 Ray State Client 去 query 整個集群的狀態(tài)。
在監(jiān)控方面Ray集成了Metrics的框架,用戶可以直接調(diào)用Ray的metrics 的接口寫入metric,然后在Ray dashboard中通過iframe的形式嵌入了Grafana來做一些簡單的監(jiān)控。
10、Ray的架構(gòu)

下面介紹一下Ray的架構(gòu)。Ray在架構(gòu)上與很多大數(shù)據(jù)系統(tǒng)類似,有一個主節(jié)點head節(jié)點,其他是 worker 節(jié)點。
在主節(jié)點里有GCS角色(Global Control Service),GCS主要負責整個集群的資源調(diào)度和節(jié)點管理,類似于Hadoop架構(gòu)中Yarn里邊的 Resource Manager。
Ray的worker節(jié)點主要有Raylet角色。除了做單機的進程管理和調(diào)度之外,比較關(guān)鍵的還有剛剛講過的分布式的object store,是集成到Raylet進程里面的。
11、小結(jié)

上圖是我們做的一個實驗,除了Ray+云原生的實現(xiàn)方式,我們也寫了一套代碼以云原生的方式來實現(xiàn)相同邏輯。代碼已經(jīng)放在上圖下方GitHub 的repo上面,大家有興趣可以查閱。
這里介紹一下實驗評估結(jié)果:
- 從研發(fā)效率看,基于純云原生方式與Ray+云原生相比從15 人天降到了2人天;
- 從代碼來看,云原生方式需要寫5種編程語言代碼,并且隨著業(yè)務(wù)復(fù)雜性的增大,代碼量會越來越大;通過Ray,用260行純Python代碼就實現(xiàn)了這個case,可以證明利用Ray開發(fā)分布式系統(tǒng)是非常快速且高效的。
- 從系統(tǒng)特點看,Ray是單語言即可實現(xiàn),只有一個main函數(shù),整個的編程相當于應(yīng)用中心化編程的思想,整個分布式系統(tǒng)只有一個入口,其他角色的實現(xiàn)都是通過Ray Actor和Task,應(yīng)用、運維部署、配置融為一體;云原生方式則需要多語言實現(xiàn),多編程入口,應(yīng)用、運維部署、配置解耦。
四、Ray開源生態(tài)
最后來介紹一下Ray的開源現(xiàn)狀。
1、活躍度

從Ray的活躍度來看,Ray從 2016 年開源至今,活躍度持續(xù)穩(wěn)定增長。目前社區(qū)有超過 800個Contributor,Star數(shù)超過26K。
2、Ray中文社區(qū)

Ray在中國有由螞蟻長期維護的中文社區(qū)。
- 中文社區(qū)的公眾號,可以掃描上圖的二維碼,公眾號會經(jīng)常發(fā)表中文社區(qū)同學寫的基礎(chǔ)文章或者活動。
- 中文社區(qū)的論壇中有一些問答和技術(shù)分享。
- 中文社區(qū)的交流群可以方便大家圍繞Ray系統(tǒng)上的應(yīng)用進行溝通。
3、Ray forward 2023

Ray forward已經(jīng)在國內(nèi)舉辦了五屆,2023年7月2日螞蟻剛剛舉辦了最新一屆的Ray forward。從五屆Ray forward可以感受到一個趨勢,在最開始的兩年,大部分的talk都是螞蟻和加州大學伯克利分校RISELab實驗室的人員分享,而近兩年已經(jīng)有越來越多的國內(nèi)公司來Ray forward分享他們自己的議題,今年是議題最多的一次。
4、Ray 2.0—Ray AIR

剛剛講的從Ray的概念還有整個case來看,實際上是Ray底層Core的核心能力。
Ray的生態(tài)花費了非常大的精力在 AI 領(lǐng)域,上圖是Ray 2.0的核心概念,叫Ray AIR(Ray AI Runtime)。Ray AIR的設(shè)計思想是在AI pipeline 的各個處理流程中去集成各種各樣主流的工具,比如數(shù)據(jù)處理、訓練、Tune、Serve等。
如果利用 Ray去構(gòu)建一個AI的pipeline,在數(shù)據(jù)處理方面可以選擇Spark,也可以選用Mars或Dask等Python的科學計算工具,也可以選擇Ray原生的Ray Dataset;在訓練方面,可以根據(jù)業(yè)務(wù)需求選擇PyTorch, TensorFlow 等訓練框架。
Ray AIR定位是一個可擴展的統(tǒng)一的機器學習工具集,最終可以幫助用戶實現(xiàn)一個腳本就能夠?qū)⒄麄€AI的pipeline構(gòu)建起來,這是一種融合計算的思路。
在沒有Ray之前,整個pipeline會有多個系統(tǒng)串聯(lián)起來,有了Ray之后,底層會有統(tǒng)一的 runtime 來完成編排和調(diào)度。
5、生態(tài)系統(tǒng)

上圖是一張比較老的圖,主要是為了展示Ray的生態(tài)。主要分為兩部分library,一個是Ray的Native Libraries,一個是Third Party Libraries。
- Native Libraries中包括Ray的強化學習庫RLlib,還有應(yīng)用比較廣泛的Ray Serve等。
- Third Party Libraries中包括剛剛提到的在 AI 處理流程中比較常用的引擎。
6、企業(yè)應(yīng)用

Ray的企業(yè)應(yīng)用是比較廣泛的。
除了剛剛講到的大語言模型場景下的OpenAI之外,上圖列出了已經(jīng)集成Ray很長時間的一些企業(yè)。整體來看,目前國外的發(fā)展更多一點,國內(nèi)相對少一點,國外的很多大廠,包括一些傳統(tǒng)企業(yè),都在利用Ray來構(gòu)建他們底層的分布式系統(tǒng)。
7、大模型訓練

上圖匯總了目前做大模型訓練的一些已經(jīng)集成了Ray的開源框架。
- 第一個項目是Alpa,是 Google 和UC Berkeley大學共同研發(fā)的面向大模型并行訓練和服務(wù)的框架,框架利用Ray Core進行GPU的管理與運行時編排。
- 第二個項目是Colossal-AI,也是比較火的分布式訓練框架,框架將Ray Core的 能力集成到RLHF流程中,就是基于人類反饋的強化學習中。
- 第三個項目是trlX,目前也集成了Ray的能力,將Ray Train和Ray Tune集成到RLHF流程中。
8、大模型訓練——Alpa on Ray

上圖是Alpa的詳細架構(gòu),可以看到Ray主要在中間層。Alpha 項目可以自動做到層間和層內(nèi)兩個角度并行化,從整個創(chuàng)新角度看是比較領(lǐng)先的分布訓練框架。
9、其他開源項目集成

上圖是除了 AI 以外的集成了Ray的能力的開源框架。
- 第一個項目是GeaFlow也就是TuGraph,TuGraph的流圖計算引擎底層集成了Ray Core進行動態(tài)資源調(diào)度。
- 第二個項目是隱語,是螞蟻開源的一個隱私計算框架,隱語深度應(yīng)用了Ray Core的能力,目前還用到了在Ray project 中的另外一個項目Ray Fed。Ray Fed可以完成在隱私計算領(lǐng)域多個 party不同的集群之間的數(shù)據(jù)傳輸與調(diào)度。
- 第三個項目是Mars,Mars是阿里開源的一個科學計算框架,可以實現(xiàn)分布式pandas、分布式scikit-learn的能力。在這個項目中不僅集成了Ray Core的能力,還深度集成了Ray Object Store的能力,從性能上看有不錯的結(jié)果。
五、答疑
A1:Ray 目前使用場景有哪些?支持實時流計算場景嗎?
Q:Ray的使用場景其實還是蠻多的,尤其在螞蟻內(nèi)部基于Ray構(gòu)建了很多框架,比如剛剛提到的GeaFlow,一個流圖計算框架,是一個比較大的方向;另外剛剛提到的隱私計算是另外一個方向。那除此之外,螞蟻內(nèi)部還有類似于函數(shù)計算系統(tǒng),函數(shù)計算也可以是基于Ray來構(gòu)建,從Ray的API可以看出Ray做函數(shù)計算還是非常方便的;除此之外還有科學計算、在線機器學習,最近我們也在探索搜推引擎能不能基于Ray來構(gòu)建。
AI 方面在螞蟻內(nèi)部用得比較多的是AI在線服務(wù),怎么應(yīng)用一個或多個模型或大模型提供推理服務(wù),整個從外圍的資源編排調(diào)度,包括failover都可以利用Ray Serve做在線服務(wù)的支持。Ray在AI 方面的應(yīng)用比較廣泛,包括剛剛提到的Ray AIR涉及到的從 AI 的數(shù)據(jù)處理、到訓練、到Ray Tune,以及最近的大模型場景,都是利用Ray來完成底層分布式底盤的。
A2:Ray支持存算分離么?Node 2 計算完成,把結(jié)果存到本地的 object store等待其他節(jié)點獲取結(jié)果,它要等到結(jié)果被獲取完才能釋放嗎?
Q:是的,如果是基于Ray原生的object store,需要把結(jié)果 put 到Node 2 里面,在 put 完之后,Node 2 異常退出了,那數(shù)據(jù)就可能丟了。當然用戶可以通過Ray原生的血緣的能力,或者用戶自己實現(xiàn)的failover能力去進行恢復(fù),如果需要保證不丟數(shù)據(jù),則需要實現(xiàn)高可用,對object store做一個擴展。目前來說,Ray object store的面向場景是做計算引擎中間結(jié)果的存儲,它并不需要做持久化存儲。
A3:是否在大部分場景下Ray都可以直接替代 Spark 使用,還是說兩者互不沖突?
Q:我覺得是互不沖突,從Ray的設(shè)計思想來看,不對標任何一個大數(shù)據(jù)系統(tǒng)。剛剛也提到在Ray的整個生態(tài)中,用戶也可以把 Spark跑在Ray上面,甚至還有一些項目在做Ray on Spark。在數(shù)據(jù)處理領(lǐng)域Spark有它的非常核心的能力。如果想在訓練之前做簡單的數(shù)據(jù)預(yù)處理,不需要牽扯到復(fù)雜的算子,這種情況下可以直接用Ray,但是如果計算場景比較復(fù)雜,比較偏向于大數(shù)據(jù)處理,并且用到比較復(fù)雜的shuffle邏輯或者比較復(fù)雜的算子,還是可以利用 Spark進行處理,然后再對接 Ray生態(tài),用戶根據(jù)自己的計算場景來進行技術(shù)選型。
A4:同為 Actor model,可以對比一下Ray和Akka分布式計算框架嗎?
Q:我對Akka的API是什么樣子印象不是很深了,我理解它應(yīng)該跟Ray的API 還是有很大區(qū)別的。Ray主要是從編程的角度出發(fā),有Task和Actor,Ray中的Actor model 跟傳統(tǒng)的Actor model 的概念還是有一點區(qū)別的。Ray的Actor更偏分布式,目前沒有面向單機線程間交互的場景。
A5:Ray是如何容錯的?
Q:我們認為容錯有兩個維度。
第一個維度是粗粒度進程級別的容錯,因為Ray交付的是一個進程,無論是Task還是Actor。Task/Actor的failover,首先是Task/Actor所在進程的一個探活,識別其是否異常退出,這是分布式系統(tǒng)基礎(chǔ)能力,在Ray里面是完全由Ray來實現(xiàn)的;其次是進程維度的failover,當Task尤其是Actor異常退出后,把異常退出實體重新調(diào)度起來進行新的實例化,也是由Ray負責的。也就是說,粗粒度的恢復(fù)是可以完全由Ray來負責。
第二個維度是細粒度,主要是進程的狀態(tài),因為Ray實際上是不去規(guī)定內(nèi)部計算邏輯的,內(nèi)部可以跑流批計算、可以跑AI 訓練、可以跑任何的一個function ,Ray并不知道內(nèi)部代碼在做什么事情,所以狀態(tài)恢復(fù)方面,目前Ray主流的用法還是把狀態(tài)恢復(fù)交給用戶的業(yè)務(wù)代碼自己負責。當然用戶可以通過Ray接口知道當前是否被重啟了,已經(jīng)重啟了多少次?用戶之前狀態(tài)需要自己做一些checkpoint,可以存到存儲里面或者存到 Ray底層的object store 里面。
用戶可以根據(jù)不同的failover的可靠性要求做具體方案。但總體來說,一般的用法是粗粒度的failover由Ray托管,細粒度的狀態(tài)恢復(fù)是由Ray上的應(yīng)用自己來做恢復(fù)。