螞蟻集團基于 Ray 構建的分布式 AI Agent 框架

相信很多人都了解 Ray,它是 OpenAI 用于大模型訓練的底層分布式框架。螞蟻集團早在很久之前就加入了 Ray,且今年 Ray 的 CEO 在夏季發布會上也提到,螞蟻是第一個正式使用并協作開發 Ray 的團隊。我們貢獻了超過 26% 的 Ray 核心代碼,是全球第二大貢獻團隊。目前,螞蟻集團在線上運營著超過 150 萬 CPU 核心,規模已相當龐大,同時我們也在運營 Ray 在中國的社區。

簡單介紹一下 Ray 在螞蟻內部的發展情況。我們在 2017 年成立了 Ray 團隊,并于 2018 年推出了首個業務場景流圖計算引擎 Geaflow。在 2018 年至 2022 年間的大數據時代,我們基于 Ray 開發了多個計算引擎,如用于流計算和機器學習訓練的 Realtime、Mobius 開源引擎,以及在線推理和科學計算引擎 Mars。同時,我們也貢獻了 Multi-Tenant 架構,Ray 社區今年才開始考慮這種架構,而螞蟻因線上集群規模龐大,早已開始考慮多租戶。
在 2023 到 2024 年大模型時代,我們在美國完成了一項工作 Unified AI Serving,將離線、在線與 AI 推理、AI 部署整合為一個框架,這是我們 150 萬內核業務的核心場景之一。接下來將介紹我們的最新工作,基于 Ray 構建的 AI Agent 框架,主要分為三個部分:背景、動因,以及設計與實現。
一、Background

首先來看一下基于大語言模型的 Agent(LLM-based Agent)通常需要哪些模塊。
- 第一個是 Profile 模塊,它定義了 Agent 的個性,即扮演怎樣的角色,比如它可以是一個溫和的旅游助手,執行旅游管理、數據分析等任務。
- 第二個是 Memory 模塊,包括兩部分:一是 Knowledge,包含行業知識和先驗知識;二是 Experience,記錄 Agent 過去的對話、用戶問題、思考過程及行動結果,這些經驗將幫助 Agent 改進后續的行為,避免重復錯誤。
- 第三個是 Planning 模塊,用于將復雜任務拆解成更容易執行的子任務。通過這種方式,Agent 可以在文本交互的基礎上完成更廣泛的任務。Planning 常見的算法有 Chain of Thought和Tree of Thought,這些就像程序設計中的流程圖,用來拆解復雜問題。
- 第四個是 Action 模塊,根據經驗和規劃執行實際任務。與大模型不同,Agent 不僅僅是文本或圖像輸入輸出,而是能對現實世界產生實際影響。Action 模塊的一個關鍵功能是 Function Calling,讓模型調用外部功能,甚至在某些場景中與機械臂等物理設備交互。
這四個模塊是我們認為一個基于大語言模型的 Agent 所需的核心組件。

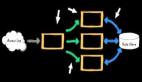
我們來看一個簡單的基于 Agent 實現的 RAG 流程。這個 RAG 不同于傳統的計算圖或工作流,而是通過 Agent 來實現的。
- 首先,Agent 會從用戶那里獲取任務,例如用戶要求從文檔中學習知識,提供了文檔鏈接。
- 第二步,模型進入思考階段,決定如何開展任務。這里可以使用 planning 模塊中的算法,如 React 或 Chain of Thought。在這個流程中,我們使用了 React 策略,即思考一步,執行一步。
- 第三步,模型決定采取具體行動。對于 RAG 場景,可以使用工具如 LlamaIndex 或 LangChain 對文檔進行解析,或調用 Lucene 和 VectorDB 進行語義檢索,甚至進行實時搜索。
- 第四步,將初始思考、選擇的行動及其結果作為三元組(triplet)存儲到 Memory 中,來指導后續工作。
- 第五步,繼續循環思考和執行,直到完成用戶任務。
特別需要注意的是,右邊的工具分為三類:紅色的 LlamaIndex 用于計算(CPU/GPU 密集型),綠色的 DB 和 Lucene 訪問為 Disk I/O,藍色的則是網絡訪問。Agent 任務中涉及這三種不同的計算任務,傳統模式可能只處理 CPU 或 CPU+IO,但在這里,一個單任務可能包含復雜的混合工作負載。

在完成 naive RAG Agent 的實現后,接下來就是部署上線。首先,我們將程序封裝成一個服務,放入 Docker 中,然后進行部署。我們的 Agent 平臺已經有大約 500 個 Agent,開發者可以在平臺上使用畫布構建并發布他們的 Agent。上圖中就是我們的一些案例。

最初,我們的做法很簡單,但很快收到了很多用戶抱怨。用戶常見的問題包括:不清楚為什么 APP 或 Pod 崩潰、缺乏監控 metrics、沒有工作負載監控、無法控制流量等。此外,由于混合工作負載,GPU 利用率通常很低。總結起來,這種簡單的做法顯然不適合生產環境。因此,我們決定將 Agent 平臺分布式化,進行生產化改造。在這個過程中,我們發現場景中確實有許多獨特的挑戰。
二、Motivation
相較于傳統計算或服務型 APP,我們認為 Agent 應用具有高度創造性,不斷涌現出革命性的創意,這也是近年來大模型和 Agent 概念火熱的原因。大家發現這些應用非常有趣,并且持續有新創意涌現,每個創意都需要快速低成本驗證,這在創業和商業中尤為重要。
一旦 PoC 驗證有效,就希望能迅速部署到線上,但這一步非常困難。上線應用涉及眾多模塊:服務、數據庫、數據來源、分布式框架等,對大公司而言,需要與多個團隊合作,小公司雖不需多個團隊,但仍需掌握所有技術。因此,PoC 到上線的過程繁瑣且漫長。此外,用戶任務可能同時涉及 GPU、CPU 和 Service Calling,且 Agent 覆蓋不同業務場景,每個場景的技術棧不同,需要大量兼容適配工作。

在分布式 Ray 生產化 Agent 過程中,我們對比了三個技術棧層級:底層的 Kubernetes(簡稱 K8S)、上層的算法庫 LangChain 和中間層的 Ray。Ray 之所以居于中間層,是因為它涵蓋豐富的 AI 生態,如 Ray Data 用于數據處理和服務化,以及強化學習和訓練。Ray 緊貼 K8S,為分布式執行調度提供支持。
Kubernetes 的優勢在于底層 API 的靈活性,允許編寫各種 CRD 并整合多種硬件,提供資源控制的完整性;但其缺點是從零開發 AI 程序非常復雜。我們與基于 K8S 的團隊交流發現,許多機器學習工程師并不熟悉 K8S。在螞蟻集團,算法工程師離掌握 K8S 還有較遠距離,這種學習曲線使得我們不太可能直接讓終端用戶使用 K8S。此外,Kubernetes 的 AI 生態相對簡陋,主要因其重心仍在底層。
LangChain 作為上層算法庫,優點在于豐富且易用,類似的 LlamaIndex 庫也非常易上手。它甚至提供 UI 功能,可以一站式開發 Agent 或大模型。然而,其缺點是僅為單機 API。在我們上線簡易版 LangChain 后,發現面臨許多生產化問題,每個問題都需解決。
接下來我們考慮使用 Ray。Ray 的優勢在于提供了一站式的工具箱,支持 AI 工作負載的數據處理、訓練和推理。Ray 的一個主要功能是輕松將本地代碼轉為分布式代碼,只需簡單加注解即可實現遠程進程。并且它在異構資源調度方面表現出色,尤其在 CPU 與 GPU 混合的數據處理中性能優于 Spark。Ray 不綁定特定計算范式(如 MapReduce 或圖計算),而是采用純分布式面向對象編程,提供了高度靈活性。
不過,Ray 也有一些不足:在資源管控上不如 K8S 靈活,因為它是在 K8S 之上再加一層;另外,目前 Ray 在大模型上沒有特定 API,一些外部組件如文件傳輸,需要在 Ray API 中額外封裝。
綜上,我們最終選擇了 Ray,同時也考慮了一些額外的加分項。例如,Ray 的 RuntimeEnv 功能提供了運行時沙箱,利用 container 執行用戶代碼,非常適合大模型場景中的代碼解釋器。它能夠直接啟動一個 Docker 容器,而在其他團隊中需要額外工作。另一個優勢是 Ray 的面向對象編程模式,與 Agent 的工作模式相似。Agent 的個性和配置可以視為對象的靜態資源,操作為成員函數,記憶則是運行時狀態,因此 Agent 很像一個對象。

決定使用 Ray 后,我們自然開始開發一個基于 Ray 的 Agent 框架。主要考慮點如下:①該框架需提供 Agent 的 API;②利用 Ray 實現從本地代碼到支持異構資源的分布式代碼的擴展;③在多 Agent 場景中,每個 Agent 都是一個分布式進程,我們需要一個框架來協調這些進程,即所謂的 environment;④要兼容不同的庫,如 MetaGPT 和 AutoGen;⑤希望利用 Ray 的沙箱(sandbox)、批處理能力和跨源調度功能。
三、Design & Impl.

在軟件技術棧中,我們使用 Ray 分為以下幾層:最上層是業務層,包括開發者已編寫的 Agent Apps。其下是 Agent Crafting Platform,這是開發者構建 Agents 的平臺。再下一層是算法庫,如 LangChain 和 MetaGPT,提供與大模型相關的算法和文檔解析功能,這些不在我們的框架實現范圍內。
在這三個業務層之下是 Ragent,它提供分布式 Agent SDK 和執行層,支持 Agent 所需的工具、記憶、環境管理、分布式通信及部署等功能。Ragent 不實現具體算法,而是將用戶代碼分布式化,依賴 Ray 的核心概念如 Task、Actor 和 Object,利用 Ray 的編程原語實現分布式面向對象編程。Ray Data 用于批處理,例如統一清洗和解析用戶文檔,類似于 Spark。Agent 的服務化通過 reserve 實現。使用 Ray 后,我們獲得高編程性能,并具備 Failover(故障轉移)能力、分級調度和共享內存的優勢。最底層是 K8S,用于資源管理和調度。

使用 Ragent 編寫一個 Agent 時,首先要了解 Ragent 提供的 Agent 概念,這是一個具備 Failover 能力的基礎單元,并內置消息隊列和 Memory。Memory 是 Agent 內部的記憶。由于存在多種 Planning 策略,Ragent 內置了 ReAct 算法,用于重復的 think 和 act 過程。如上圖的簡化版代碼中,通過一個 while True 循環,每次先進行 reasoning(think),獲取 thought 和預期執行的 action,然后實際調用 action,持續在循環中執行。

Agent 的能力主要來自于其具備的工具,如文檔清洗或制定旅游攻略的能力,這使得 Agent 能夠在功能上超越單純的大模型,因此 Tool 部分至關重要。要為 Agent 定制、加載或注冊一個 tool,我們可以通過注解實現。在 Python 代碼中,比如對 index_doc 函數輸入文檔,使用 Ray Data 和 LangChain 進行處理。用 tool 注解這個函數即可將其注冊到 Agent 中,使 Agent 理解。注冊過程中,需要用自然語言描述其功能、輸入輸出及用途,類似于編程中的 doc string。注冊的每個 tool 會作為 prompt 的一部分輸入到大模型,使得整個 Agent 相當于一個 Ray Actor。

實現一個簡易版的 RAG Agent 在我們的框架中非常簡單,只需幾行代碼。首先,引入必要的庫后,在 main 函數中初始化一個 Agent,使用內置的 ReAct 算法,并指定大模型為 Qwen。在 profile 中賦予靜態資源后,為 Agent 注冊多個工具,如 Apache Lucene 和 LlamaIndex。我們注冊的 action 包括使用 LlamaIndex 進行文檔索引,Lucene 用于 Elasticsearch,以及 DB 進行語義搜索,這些工具便可實現一個簡單的 RAG。
完成初始化和注冊后,Agent 便可與用戶交互。用戶的第一個 involve 是從 Ray 文檔中學習最新功能,此時 Agent 會調用工具,將用戶提供的文檔索引到 DB 中作為知識的一部分。工具使用 Ray Data 實現,因此在執行階段,Agent 將其作為 Ray Data 的作業提交,批處理輸出到 DB 中每個文檔的知識。

接下來,用戶可對文檔提問,如詢問 Ray 最新版本的 Ray Data 功能,此時 Agent 會從 DB 中進行字符和語義檢索,經過大模型處理后返回結果。整個過程只需幾行代碼即可完成一個 RAG Agent,不過這是簡易版的。
接下來,我們看一個 Multi-agent 的例子。左邊的圖是 MetaGPT 的實現,展示了如何利用多個 Agent 構建一個軟件公司。每個 Agent 承擔不同職責,如產品經理、架構師、代碼工程師和測試工程師。對于任務如編寫貪吃蛇程序,Agent 按順序協作。產品經理用工具生成設計圖給架構師,架構師再創建技術架構圖。工程師根據用戶需求編寫接口和實現,再交給測試進行 UT,直到程序完成。左圖展示了流程,右圖是用戶交互,比如編寫 FlappyBird,此例子被 Ragent 框架分布式化。
在該框架中,我們實現了一個 environment 組件,用于 task 追蹤,包含用戶任務和每個 Agent 的任務。它構建 workflow,通過 message queue 與 Agent 通信,并保存對話歷史。每個 Agent 作為遠程進程,由 Agent handler 管理。在代碼中,我們先初始化 environment(紫色為 MetaGPT 代碼,橙色為框架代碼),然后初始化架構師、產品經理和 coder 等 agent,為 MetaGPT 代碼進行適配。
初始化四個 Agent 后,將其加入 environment。每個 Agent 描述功能已在 profile 和 system prompt 中定義,注冊后 environment 知道各 Agent 職責。目前還需手動指定 Agent 交互順序,environment 尚不能自動選擇。加入后,環境運行應用,如編寫 FlappyBird 或貪吃蛇。在實踐中,GPT-4 效果較好,能構建設計圖和部分可運行代碼,但其他模型仍難以實現復雜應用,通常在第一輪生成輸出。以上是 Ragent 框架在 Multi-agent 場景的應用。

接下來是我們未來的一些工作。首先是 Agent Mesh。目前,Agent 框架眾多,但缺乏統一的通信和流程標準。我們希望通過 Agent Protocol 項目,制定一個協議,整合不同框架,實現類似服務網格的通信環境。右圖展示的是我們正在開發的離在線一體架構,這在非 Agent 場景下已實現。由于底層執行層都是 Ray,無論在線還是離線,技術棧相同,我們無需特別定制,能夠結合使用。
在 Agent 場景中,文檔處理等純離線操作通過 Ray Data 實現,第一步可用 Ray Data pipeline 完成離線工作。對于單 Agent 或多 Agent 的二三步,可以實現服務化,每個進程用 Agent Protocol 封裝,實現互通信。這在 Agent 場景中尚未完成,但在計劃中。
我們還需關注底層硬件。目前不需要大量 GPU,但有廠商和開源社區希望支持更多 GPU,如 NPU。以上即是我們的工作計劃。