昇騰Ascend C編程入門(mén)教程(純干貨)?
2023年5月6日,在昇騰AI開(kāi)發(fā)者峰會(huì)上,華為正式發(fā)布了面向算子開(kāi)發(fā)場(chǎng)景的昇騰Ascend C編程語(yǔ)言。Ascend C原生支持C/C++編程規(guī)范,通過(guò)多層接口抽象、并行編程范式、孿生調(diào)試等技術(shù),極大提高了算子的開(kāi)發(fā)效率,幫助AI開(kāi)發(fā)者低成本完成算子開(kāi)發(fā)和模型調(diào)優(yōu)部署。
昇騰AI軟硬件基礎(chǔ)
和CUDA開(kāi)發(fā)的算子運(yùn)行在GPU上一樣,基于Ascend C開(kāi)發(fā)的算子,可以通過(guò)異構(gòu)計(jì)算架構(gòu)CANN(Compute Architecture for Neural Networks)運(yùn)行在昇騰AI處理器(可簡(jiǎn)稱(chēng)NPU)上。CANN是使能昇騰AI處理器的一個(gè)軟件棧,通過(guò)軟硬件協(xié)同優(yōu)化,能夠充分發(fā)揮昇騰AI處理器的強(qiáng)大算力。從下面的架構(gòu)圖可以清楚的看到,使用Ascend C編程語(yǔ)言開(kāi)發(fā)的算子通過(guò)編譯器編譯和運(yùn)行時(shí)調(diào)度,最終運(yùn)行在昇騰AI處理器上。
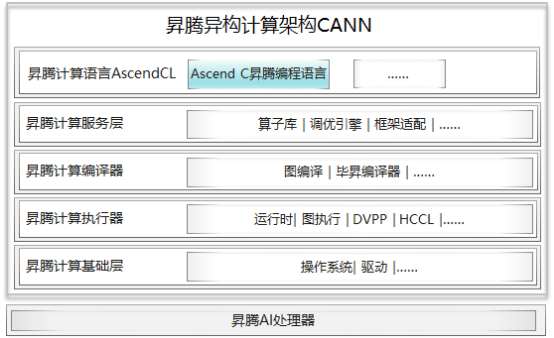
我們知道,通用計(jì)算就是我們常寫(xiě)的一些在CPU上運(yùn)行的計(jì)算,它擅長(zhǎng)邏輯控制和串行計(jì)算,而AI計(jì)算相對(duì)通用計(jì)算來(lái)說(shuō),更擅長(zhǎng)并行計(jì)算,可支持大規(guī)模的計(jì)算密集型任務(wù)。如下面左圖所示,做一個(gè)矩陣乘,使用CPU計(jì)算需要三層for循環(huán),而右圖在昇騰AI處理器上使用vector計(jì)算單元,只需要兩層for循環(huán),最小計(jì)算代碼能同時(shí)計(jì)算多個(gè)數(shù)據(jù)的乘加,更近一步,如果使用Cube計(jì)算單元,只需要一條語(yǔ)句就能完成一個(gè)矩陣乘的計(jì)算,這就是我們所說(shuō)的SIMD(單指令多數(shù)據(jù))。因此,我們通常使用AI處理器來(lái)進(jìn)行大量的并行計(jì)算。
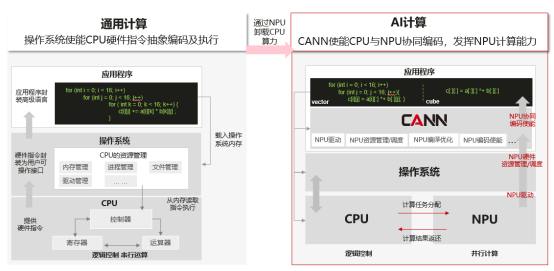
NPU不能獨(dú)立運(yùn)行,需要與CPU協(xié)同工作,可以看成是CPU的協(xié)處理器,CPU負(fù)責(zé)整個(gè)操作系統(tǒng)運(yùn)行,管理各類(lèi)資源并進(jìn)行復(fù)雜的邏輯控制,而NPU主要負(fù)責(zé)并行計(jì)算任務(wù)。在基于CPU+NPU的異構(gòu)計(jì)算架構(gòu)中,NPU與CPU通過(guò)PCIe總線連接在一起來(lái)協(xié)同工作,CPU所在位置稱(chēng)為主機(jī)端(host),而NPU所在位置稱(chēng)為設(shè)備端(device),示意圖如下:

這里再詳細(xì)介紹一下昇騰AI處理器。昇騰AI處理器有不同的型號(hào)和產(chǎn)品形態(tài),小到模塊、加速卡,大到服務(wù)器、集群。昇騰AI處理器里面最核心的部件是AI Core,有多個(gè),是神經(jīng)網(wǎng)絡(luò)加速的計(jì)算核心,每一個(gè)AI Core就相當(dāng)于我們大家平時(shí)理解的多核cpu里的每個(gè)核,使用Ascend C編程語(yǔ)言開(kāi)發(fā)的算子就運(yùn)行在AI Core上,因?yàn)楹诵牡纳窠?jīng)網(wǎng)絡(luò)計(jì)算的加速都來(lái)源于AI Core的算力。
AI Core內(nèi)部的并行計(jì)算架構(gòu)抽象如下圖所示:
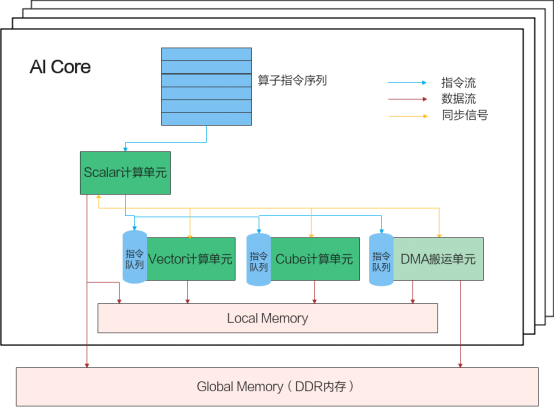
這個(gè)并行計(jì)算架構(gòu)抽象核心包含了幾個(gè)大的部件,AI Core外面有一個(gè)Gobal Memory,是多個(gè)AI Core共享的,在AI Core內(nèi)部有一塊本地內(nèi)存Local Memory,因?yàn)榭拷?jì)算單元,所以它的帶寬會(huì)非常高,相對(duì)的容量就會(huì)很小,比如一般是幾百K到1M。AI Core內(nèi)部的核心組件有三個(gè)計(jì)算單元,標(biāo)量計(jì)算單元、向量計(jì)算單元,矩陣計(jì)算單元。另外還有一個(gè)DMA搬運(yùn)單元,DMA搬運(yùn)單元負(fù)責(zé)在Global Memory和Local Memory之間搬運(yùn)數(shù)據(jù)。
AI Core內(nèi)部的異步并行計(jì)算過(guò)程:Scalar計(jì)算單元讀取指令序列,并把向量計(jì)算、矩陣計(jì)算、數(shù)據(jù)搬運(yùn)指令發(fā)射給對(duì)應(yīng)單元的指令隊(duì)列,向量計(jì)算單元、矩陣計(jì)算單元、數(shù)據(jù)搬運(yùn)單元異步并行執(zhí)行接收到的指令。該過(guò)程可以參考上圖中藍(lán)色箭頭所示的指令流。不同的指令間有可能存在依賴(lài)關(guān)系,為了保證不同指令隊(duì)列間的指令按照正確的邏輯關(guān)系執(zhí)行,Scalar計(jì)算單元也會(huì)給對(duì)應(yīng)單元下發(fā)同步指令。各單元之間的同步過(guò)程可以參考上圖中的橙色箭頭所示的同步信號(hào)流。
AI Core內(nèi)部數(shù)據(jù)處理的基本過(guò)程:DMA搬入單元把數(shù)據(jù)搬運(yùn)到Local Memory,Vector/Cube計(jì)算單元完成數(shù)據(jù),并把計(jì)算結(jié)果寫(xiě)回Local Memory,DMA搬出單元把處理好的數(shù)據(jù)搬運(yùn)回Global Memory。該過(guò)程可以參考上圖中的紅色箭頭所示的數(shù)據(jù)流。
Ascend C編程模型基礎(chǔ)
Ascend C編程范式
Ascend C編程范式是一種流水線式的編程范式,把算子核內(nèi)的處理程序,分成多個(gè)流水任務(wù),通過(guò)隊(duì)列(Queue)完成任務(wù)間通信和同步,并通過(guò)統(tǒng)一的內(nèi)存管理模塊(Pipe)管理任務(wù)間通信內(nèi)存。流水編程范式應(yīng)用了流水線并行計(jì)算方法。
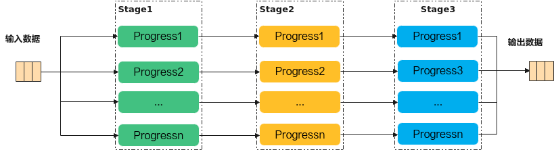
若n=3,即待處理的數(shù)據(jù)被切分成3片,則上圖中的流水任務(wù)運(yùn)行起來(lái)的示意圖如下,從運(yùn)行圖中可以看出,對(duì)于同一片數(shù)據(jù),Stage1、Stage2、Stage3之間的處理具有依賴(lài)關(guān)系,需要串行處理;不同的數(shù)據(jù)切片,同一時(shí)間點(diǎn),可以有多個(gè)任務(wù)在并行處理,由此達(dá)到任務(wù)并行、提升性能的目的。
Ascend C分別針對(duì)Vector、Cube編程設(shè)計(jì)了不同的流水任務(wù)。開(kāi)發(fā)者只需要完成基本任務(wù)的代碼實(shí)現(xiàn)即可,底層的指令同步和并行調(diào)度由Ascend C框架實(shí)現(xiàn),開(kāi)發(fā)者無(wú)需關(guān)注。
矢量編程范式
矢量編程范式把算子的實(shí)現(xiàn)流程分為3個(gè)基本任務(wù):CopyIn,Compute,CopyOut。CopyIn負(fù)責(zé)搬入操作,Compute負(fù)責(zé)矢量計(jì)算操作,CopyOut負(fù)責(zé)搬出操作。

我們只需要根據(jù)編程范式完成基本任務(wù)的代碼實(shí)現(xiàn)就可以了,底層的指令同步和并行調(diào)度由Ascend C框架來(lái)實(shí)現(xiàn)。
那Ascend C是怎么完成不同任務(wù)之間的數(shù)據(jù)通信和同步的呢?這里Ascend C提供了Queue隊(duì)列管理的API,主要就是兩個(gè)隊(duì)列操作API EnQue、DeQue以及內(nèi)存的邏輯抽象。
矢量編程中使用到的邏輯位置(QuePosition)定義如下:
- 搬入數(shù)據(jù)的存放位置:VECIN;
- 計(jì)算中間變量的位置:VECCALC;
- 搬出數(shù)據(jù)的存放位置:VECOUT。
從前面可以看到,矢量編程主要分為CopyIn、Compute、CopyOut三個(gè)任務(wù)。CopyIn任務(wù)中將輸入數(shù)據(jù)從Global內(nèi)存搬運(yùn)至Local內(nèi)存后,需要使用EnQue將LocalTensor放入VECIN的Queue中;Compute任務(wù)等待VECIN的Queue中LocalTensor出隊(duì)之后才可以完成矢量計(jì)算,計(jì)算完成后使用EnQue將計(jì)算結(jié)果LocalTensor放入到VECOUT的Queue中;CopyOut任務(wù)等待VECOUT的Queue中LocalTensor出隊(duì),再將其拷貝到Global內(nèi)存。這樣 ,Queue隊(duì)列就完成了三個(gè)任務(wù)間的數(shù)據(jù)通信和同步。具體流程和流程圖如下:
- Stage1:CopyIn任務(wù)。使用DataCopy接口將GlobalTensor數(shù)據(jù)拷貝到LocalTensor。
使用EnQue接口將LocalTensor放入VECIN的Queue中。 - Stage2:Compute任務(wù)。使用DeQue接口從VECIN中取出LocalTensor。
使用Ascend C接口完成矢量計(jì)算。
使用EnQue接口將計(jì)算結(jié)果LocalTensor放入到VECOUT的Queue中。 - Stage3:CopyOut任務(wù)。
使用DeQue接口從VECOUT的Queue中去除LocalTensor。
使用DataCopy接口將LocalTensor拷貝到GlobalTensor上。
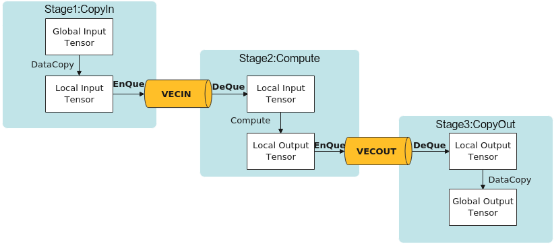
這樣我們的kernel實(shí)現(xiàn)代碼就很清晰了。先初始化內(nèi)存和隊(duì)列,然后通過(guò)編程范式實(shí)現(xiàn)CopyIn、Compute、CopyOut三個(gè)Stage就可以了。
SPMD并行編程-多核
最前面介紹昇騰AI處理器的時(shí)候,有介紹過(guò)AI Core是有多個(gè)的,那我們?cè)趺窗讯鄠€(gè)AI Core充分利用起來(lái)呢?常用的并行計(jì)算方法中,有一種SPMD(Single-Program Multiple-Data)數(shù)據(jù)并行的方法,簡(jiǎn)單說(shuō)就是將數(shù)據(jù)分片,每片數(shù)據(jù)經(jīng)過(guò)完整的一個(gè)數(shù)據(jù)處理流程。這個(gè)就能和昇騰AI處理器的多核匹配上了,我們將數(shù)據(jù)分成多份,每份數(shù)據(jù)的處理運(yùn)行在一個(gè)核上,這樣每份數(shù)據(jù)并行處理完成,整個(gè)數(shù)據(jù)也就處理完了。Ascend C是SPMD(Single-Program Multiple-Data)編程,多個(gè)AI Core共享相同的指令代碼,每個(gè)核上的運(yùn)行實(shí)例唯一的區(qū)別是就是block_idx(內(nèi)置變量)不同,這樣我們就可以通過(guò)block_idx來(lái)區(qū)分不同的核,只要對(duì)Global Memory上的數(shù)據(jù)地址進(jìn)行切分偏移,就可以讓每個(gè)核處理自己對(duì)應(yīng)的那部分?jǐn)?shù)據(jù)了。
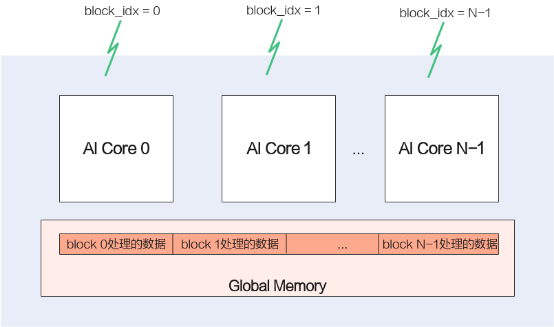
算子被調(diào)用時(shí),所有的計(jì)算核心都執(zhí)行相同的實(shí)現(xiàn)代碼,入口函數(shù)的入?yún)⒁彩窍嗤摹C總€(gè)核上處理的數(shù)據(jù)地址需要在起始地址上增加block_idx*BLOCK_LENGTH(每個(gè)block處理的數(shù)據(jù)長(zhǎng)度)的偏移來(lái)獲取。這樣也就實(shí)現(xiàn)了多核并行計(jì)算的數(shù)據(jù)切分。
class KernelAdd {
public:
__aicore__ inline KernelAdd() {}
__aicore__ inline void Init(GM_ADDR x, GM_ADDR y, GM_ADDR z)
{
// get start index for current core, core parallel
GM_ADDR xGmOffset = x + BLOCK_LENGTH * GetBlockIdx();
GM_ADDR yGmOffset = y + BLOCK_LENGTH * GetBlockIdx();
GM_ADDR zGmOffset = z + BLOCK_LENGTH * GetBlockIdx();
xGm.SetGlobalBuffer((__gm__ half*)xGmOffset, BLOCK_LENGTH);
yGm.SetGlobalBuffer((__gm__ half*)yGmOffset, BLOCK_LENGTH);
zGm.SetGlobalBuffer((__gm__ half*)zGmOffset, BLOCK_LENGTH);
……
}
……
}
Ascend C API介紹
在整個(gè)kernel實(shí)現(xiàn)中,最最核心的代碼就是Add(zLocal, xLocal, yLocal, TILE_LENGTH);通過(guò)一個(gè)Ascend C提供的API接口完成了所有數(shù)據(jù)的加法計(jì)算,對(duì),沒(méi)看錯(cuò),就是這個(gè)接口完成了計(jì)算。
接下來(lái)就介紹下Ascend C提供的API。Ascend C算子采用標(biāo)準(zhǔn)C++語(yǔ)法和一組類(lèi)庫(kù)API進(jìn)行編程,類(lèi)庫(kù)API主要包含以下幾種,大家可以在核函數(shù)的實(shí)現(xiàn)中根據(jù)自己的需求選擇合適的API:
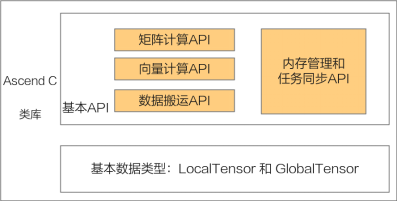
- 計(jì)算類(lèi)API,包括標(biāo)量計(jì)算API、向量計(jì)算API、矩陣計(jì)算API,分別實(shí)現(xiàn)調(diào)用Scalar計(jì)算單元、Vector計(jì)算單元、Cube計(jì)算單元執(zhí)行計(jì)算的功能。
- 數(shù)據(jù)搬運(yùn)API,上述計(jì)算API基于Local Memory數(shù)據(jù)進(jìn)行計(jì)算,所以數(shù)據(jù)需要先從Global Memory搬運(yùn)至Local Memory,再使用計(jì)算接口完成計(jì)算,最后從Local Memory搬出至Global Memory。執(zhí)行搬運(yùn)過(guò)程的接口稱(chēng)之為數(shù)據(jù)搬移接口,比如DataCopy接口。
- 內(nèi)存管理API,用于分配管理內(nèi)存,比如AllocTensor、FreeTensor接口。
- 任務(wù)同步API,完成任務(wù)間的通信和同步,比如EnQue、DeQue接口。
Ascend C API的計(jì)算操作數(shù)都是Tensor類(lèi)型:GlobalTensor和LocalTensor。
介紹完Ascend C API種類(lèi)后,下面來(lái)解釋下為什么一個(gè)Add接口就可以計(jì)算所有的數(shù)。原來(lái)Ascend C編程模型是基于SIMD(單指令多數(shù)據(jù))架構(gòu)的,單條指令可以完成多個(gè)數(shù)據(jù)操作,同時(shí)在API內(nèi)部封裝了一些指令的高級(jí)功能。
算子執(zhí)行基本流程
前面有提到,在異構(gòu)計(jì)算架構(gòu)中,NPU與CPU是協(xié)同工作的,在Ascend C編程模型中,我們需要實(shí)現(xiàn)NPU側(cè)的代碼和CPU側(cè)的代碼。在NPU側(cè)的代碼我們通常叫做Kernel實(shí)現(xiàn)代碼,CPU側(cè)的代碼我們一般叫做Host實(shí)現(xiàn)代碼,一份完整的Ascend C代碼,通常包括Host側(cè)實(shí)現(xiàn)代碼和Kernel側(cè)實(shí)現(xiàn)代碼。Ascend C算子執(zhí)行的基本流程如下:
- 初始化Device設(shè)備;
- 創(chuàng)建Context綁定設(shè)備;
- 分配Host內(nèi)存,并進(jìn)行數(shù)據(jù)初始化;
- 分配Device內(nèi)存,并將數(shù)據(jù)從Host上拷貝到Device上;
- 用內(nèi)核調(diào)用符<<<>>>調(diào)用核函數(shù)完成指定的運(yùn)算;
- 將Device上的運(yùn)算結(jié)果拷貝回Host;
- 釋放申請(qǐng)的資源。
核函數(shù)介紹
上面的流程中,最重要的一步就是調(diào)用核函數(shù)來(lái)進(jìn)行并行計(jì)算任務(wù)。核函數(shù)(Kernel Function)是Ascend C算子Device側(cè)實(shí)現(xiàn)的入口。在核函數(shù)中,需要為在AI核上執(zhí)行的代碼規(guī)定要進(jìn)行的數(shù)據(jù)訪問(wèn)和計(jì)算操作。
extern "C" __global__ __aicore__ void add_custom(__gm__ uint8_t* x, __gm__ uint8_t* y, __gm__ uint8_t* z);
上面這個(gè)是一個(gè)核函數(shù)聲明的示例,extern "C"表示核函數(shù)按照類(lèi)C的編譯和連接規(guī)約來(lái)編譯和連接,__global__函數(shù)類(lèi)型限定符表示它是一個(gè)核函數(shù), __aicore__函數(shù)類(lèi)型限定符表示該核函數(shù)在device側(cè)的AI Core上執(zhí)行。參數(shù)列表中的變量類(lèi)型限定符__gm__,表明該指針變量指向Global Memory上某處內(nèi)存地址,注意這里的入?yún)⒅荒苤С种羔樆駽/C++內(nèi)置數(shù)據(jù)類(lèi)型,樣例里指針使用的類(lèi)型為uint8_t,在后續(xù)的使用中需要將其轉(zhuǎn)化為實(shí)際的指針類(lèi)型。
Ascend C編程模型中的核函數(shù)采用內(nèi)核調(diào)用符<<<...>>>來(lái)調(diào)用,樣例如下:
kernel_name<<<blockDim, l2ctrl, stream>>>(argument list);
kernel_name即為上面講的核函數(shù)名稱(chēng),argument list是核函數(shù)的函數(shù)入?yún)?/span>,在<<<>>>中間,有3個(gè)參數(shù):
- blockDim,規(guī)定了核函數(shù)將會(huì)在幾個(gè)核上執(zhí)行,我們可以先設(shè)置為1;
- l2ctrl,保留參數(shù),暫時(shí)設(shè)置為固定值nullptr,我們不用關(guān)注;
- stream,使用aclrtCreateStream創(chuàng)建,用于多線程調(diào)度。
樣例開(kāi)發(fā)講解
樣例代碼結(jié)構(gòu)
|-- CMakeLists.txt //編譯工程文件
|-- cmake //編譯工程文件
|-- data_utils.h //數(shù)據(jù)讀入寫(xiě)出函數(shù)
|-- input //存放腳本生成的輸入數(shù)據(jù)目錄
|-- leakyrelu_custom.cpp //算子kernel實(shí)現(xiàn)
|-- leakyrelu_custom.py //輸入數(shù)據(jù)和真值數(shù)據(jù)生成腳本文件
|-- leakyrelu_custom_tiling.h //host側(cè)tiling函數(shù)
|-- main.cpp //主函數(shù),host側(cè)調(diào)用代碼,含cpu域及npu域調(diào)用
|-- output //存放算子運(yùn)行輸出數(shù)據(jù)和標(biāo)桿數(shù)據(jù)的目錄
|-- readme.md //執(zhí)行命令說(shuō)明
|-- run.sh //運(yùn)行腳本
主要文件
輸入數(shù)據(jù)和真值數(shù)據(jù)生成腳本文件:KERNEL_NAME.py。
根據(jù)算子的輸入輸出編寫(xiě)生成輸入數(shù)據(jù)和真值數(shù)據(jù)的腳本。
本例子生成8 * 200 * 1024大小的fp16數(shù)據(jù):
……
def gen_golden_data_simple():
total_length_imm = 8 * 200 * 1024
tile_num_imm = 8
//生成tilling的bin文件
total_length = np.array(total_length_imm, dtype=np.uint32)
tile_num = np.array(tile_num_imm, dtype=np.uint32)
scalar = np.array(0.1, dtype=np.float32)
tiling = (total_length, tile_num, scalar)
tiling_data = b''.join(x.tobytes() for x in tiling)
with os.fdopen(os.open('./input/tiling.bin', WRITE_FILE_FLAGS, PEN_FILE_MODES_640), 'wb') as f:
f.write(tiling_data)
//生成輸入數(shù)據(jù)
input_x = np.random.uniform(-100, 100, [8, 200, 1024]).astype(np.float16)
//生成golden數(shù)據(jù),功能和LeakyRelu相同
golden = np.where(input_x > 0, input_x, input_x * scalar).astype(np.float16)
input_x.tofile("./input/input_x.bin")
golden.tofile("./output/golden.bin")
編譯工程文件:CMakeLists.txt
用于編譯cpu側(cè)或npu側(cè)運(yùn)行的Ascend C算子。主要關(guān)注CMakeLists.txt中源文件是否全部列全。
調(diào)用算子的應(yīng)用程序:main.cpp
主要是內(nèi)存申請(qǐng),數(shù)據(jù)拷貝和文件讀寫(xiě)等操作,并最終調(diào)用算子,相關(guān)API的介紹如下:
- AscendCL初始化接口aclInit,用于運(yùn)行時(shí)接口AscendCL的初始化,是程序最先調(diào)用的接口;aclrtCreateContext和aclrtCreateStream用于創(chuàng)建Context和Stream,主要用于線程相關(guān)的資源管理。
- aclrtMallocHost接口,用于在Host上申請(qǐng)內(nèi)存:aclError aclrtMallocHost(void **hostPtr, size_t size)
這個(gè)函數(shù)和C語(yǔ)言中的malloc類(lèi)似,用于在Host上申請(qǐng)一定字節(jié)大小的內(nèi)存,其中hostPtr是指向所分配內(nèi)存的指針,size是申請(qǐng)的內(nèi)存大小,如果需要釋放這塊內(nèi)存的話,使用aclrtFreeHost接口釋放,這和C語(yǔ)言中的free函數(shù)對(duì)應(yīng)。 - aclrtMalloc接口,用于在Device上申請(qǐng)內(nèi)存:aclError aclrtMalloc(void **devPtr, size_t size, aclrtMemMallocPolicy policy)
和Host上的內(nèi)存申請(qǐng)接口相比,多了一個(gè)policy參數(shù),用于設(shè)置內(nèi)存分配規(guī)則,一般設(shè)置成ACL_MEM_MALLOC_HUGE_FIRST就可以了。使用完畢后可以用對(duì)應(yīng)的aclrtFree接口釋放內(nèi)存。 - aclrtMemcpy接口,用于Host和Device之間數(shù)據(jù)拷貝:前面申請(qǐng)的內(nèi)存區(qū)分了Host內(nèi)存和Device內(nèi)存,那就會(huì)涉及到數(shù)據(jù)同步的問(wèn)題,aclrtMemcpy就是用于Host和Device之間數(shù)據(jù)通信的接口:
aclError aclrtMemcpy(void *dst, size_t destMax, const void *src, size_t count, aclrtMemcpyKind kind)
其中src指向數(shù)據(jù)源,而dst是目標(biāo)內(nèi)存地址,destMax 是目的內(nèi)存地址的最大內(nèi)存長(zhǎng)度,count是拷貝的字節(jié)數(shù),其中aclrtMemcpyKind控制復(fù)制的方向:ACL_MEMCPY_HOST_TO_HOST、ACL_MEMCPY_HOST_TO_DEVICE、ACL_MEMCPY_DEVICE_TO_HOST和ACL_MEMCPY_DEVICE_TO_DEVICE,像ACL_MEMCPY_HOST_TO_DEVICE就是將Host上數(shù)據(jù)拷貝到Device上。 - 核心函數(shù)為CPU側(cè)的調(diào)用kernel函數(shù)
ICPU_RUN_KF(leakyrelu_custom, blockDim, x, y, usrWorkSpace, tiling);
和NPU側(cè)調(diào)用的
leakyrelu_custom_do(blockDim, nullptr, stream, xDevice, yDevice, workspaceDevice, tilingDevice);
完整代碼如下:
//This file constains code of cpu debug and npu code.We read data from bin file and write result to file.
#include "data_utils.h"
#include "leakyrelu_custom_tiling.h"
#ifndef __CCE_KT_TEST__
#include "acl/acl.h"
extern void leakyrelu_custom_do(uint32_t coreDim, void* l2ctrl, void* stream, uint8_t* x, uint8_t* y,
uint8_t* workspace, uint8_t* tiling);
#else
#include "tikicpulib.h"
extern "C" __global__ __aicore__ void leakyrelu_custom(GM_ADDR x, GM_ADDR y, GM_ADDR workspace, GM_ADDR tiling);
#endif
int32_t main(int32_t argc, char* argv[])
{
size_t tilingSize = sizeof(LeakyReluCustomTilingData);
size_t usrWorkspaceSize = 4096;
size_t sysWorkspaceSize = 16 * 1024 * 1024;
uint32_t blockDim = 8;
#ifdef __CCE_KT_TEST__ //CPU側(cè)調(diào)用
//申請(qǐng)內(nèi)存用于存放workspace和tilling數(shù)據(jù)
uint8_t* usrWorkSpace = (uint8_t*)AscendC::GmAlloc(usrWorkspaceSize);
uint8_t* tiling = (uint8_t*)AscendC::GmAlloc(tilingSize);
ReadFile("./input/tiling.bin", tilingSize, tiling, tilingSize);
size_t inputByteSize = blockDim * 200 * 1024 * sizeof(uint16_t); // uint16_t represent half
size_t outputByteSize = blockDim * 200 * 1024 * sizeof(uint16_t); // uint16_t represent half
//申請(qǐng)內(nèi)存用于存放輸入和輸出數(shù)據(jù)
uint8_t* x = (uint8_t*)AscendC::GmAlloc(inputByteSize);
uint8_t* y = (uint8_t*)AscendC::GmAlloc(inputByteSize);
//獲取輸入數(shù)據(jù)
ReadFile("./input/input_x.bin", inputByteSize, x, inputByteSize);
// PrintData(x, 16, printDataType::HALF);
//在AIV上執(zhí)行
AscendC::SetKernelMode(KernelMode::AIV_MODE);
//調(diào)用kernel函數(shù)
ICPU_RUN_KF(leakyrelu_custom, blockDim, x, y, usrWorkSpace, tiling); // use this macro for cpu debug
// PrintData(y, 16, printDataType::HALF);
WriteFile("./output/output_y.bin", y, outputByteSize);
AscendC::GmFree((void *)x);
AscendC::GmFree((void *)y);
AscendC::GmFree((void *)usrWorkSpace);
AscendC::GmFree((void *)tiling);
#else //NPU側(cè)調(diào)用
CHECK_ACL(aclInit(nullptr));
aclrtContext context;
int32_t deviceId = 0;
CHECK_ACL(aclrtSetDevice(deviceId));
CHECK_ACL(aclrtCreateContext(&context, deviceId));
aclrtStream stream = nullptr;
CHECK_ACL(aclrtCreateStream(&stream));
uint8_t *xHost, *yHost, *tilingHost, *workspaceHost;
uint8_t *xDevice, *yDevice, *tilingDevice, *workspaceDevice;
//申請(qǐng)host上tilling內(nèi)存并讀入tilling數(shù)據(jù)
CHECK_ACL(aclrtMallocHost((void**)(&tilingHost), tilingSize));
ReadFile("./input/tiling.bin", tilingSize, tilingHost, tilingSize);
//申請(qǐng)host上workspace內(nèi)存
CHECK_ACL(aclrtMallocHost((void**)(&workspaceHost), tilingSize));
size_t inputByteSize = blockDim * 200 * 1024 * sizeof(uint16_t); // uint16_t represent half
size_t outputByteSize = blockDim * 200 * 1024 * sizeof(uint16_t); // uint16_t represent half
size_t workspaceByteSize = sysWorkspaceSize + usrWorkspaceSize;
//申請(qǐng)host和device上的輸入輸出內(nèi)存和device上的workspace和tilling內(nèi)存
CHECK_ACL(aclrtMallocHost((void**)(&xHost), inputByteSize));
CHECK_ACL(aclrtMallocHost((void**)(&yHost), inputByteSize));
CHECK_ACL(aclrtMallocHost((void**)(&workspaceHost), workspaceByteSize));
CHECK_ACL(aclrtMalloc((void**)&xDevice, inputByteSize, ACL_MEM_MALLOC_HUGE_FIRST));
CHECK_ACL(aclrtMalloc((void**)&yDevice, inputByteSize, ACL_MEM_MALLOC_HUGE_FIRST));
CHECK_ACL(aclrtMalloc((void**)&tilingDevice, tilingSize, ACL_MEM_MALLOC_HUGE_FIRST));
CHECK_ACL(aclrtMalloc((void**)&workspaceDevice, workspaceByteSize, ACL_MEM_MALLOC_HUGE_FIRST));
ReadFile("./input/input_x.bin", inputByteSize, xHost, inputByteSize);
// PrintData(xHost, 16, printDataType::HALF);
//從host上拷貝輸入數(shù)據(jù)和tilling數(shù)據(jù)到device
CHECK_ACL(aclrtMemcpy(xDevice, inputByteSize, xHost, inputByteSize, ACL_MEMCPY_HOST_TO_DEVICE));
CHECK_ACL(aclrtMemcpy(tilingDevice, tilingSize, tilingHost, tilingSize, ACL_MEMCPY_HOST_TO_DEVICE));
//調(diào)用核函數(shù)
leakyrelu_custom_do(blockDim, nullptr, stream, xDevice, yDevice, workspaceDevice, tilingDevice);
//等待核函數(shù)運(yùn)行完成
CHECK_ACL(aclrtSynchronizeStream(stream));
//拷回運(yùn)行結(jié)果到host
CHECK_ACL(aclrtMemcpy(yHost, outputByteSize, yDevice, outputByteSize, ACL_MEMCPY_DEVICE_TO_HOST));
// PrintData(yHost, 16, printDataType::HALF);
WriteFile("./output/output_y.bin", yHost, outputByteSize);
//釋放資源
CHECK_ACL(aclrtFree(xDevice));
CHECK_ACL(aclrtFree(yDevice));
CHECK_ACL(aclrtFree(workspaceDevice));
CHECK_ACL(aclrtFree(tilingDevice));
CHECK_ACL(aclrtFreeHost(xHost));
CHECK_ACL(aclrtFreeHost(yHost));
CHECK_ACL(aclrtFreeHost(workspaceHost));
CHECK_ACL(aclrtFreeHost(tilingHost));
CHECK_ACL(aclrtDestroyStream(stream));
CHECK_ACL(aclrtDestroyContext(context));
CHECK_ACL(aclrtResetDevice(deviceId));
CHECK_ACL(aclFinalize());
#endif
return 0;
}
一鍵式編譯運(yùn)行腳本run.sh
編譯和運(yùn)行應(yīng)用程序。
cpu側(cè)運(yùn)行命令:
bash run.sh leakyrelu_custom ascend910B1 VectorCore cpu
npu側(cè)運(yùn)行命令:
bash run.sh leakyrelu_custom ascend910B1 VectorCore npu
參數(shù)含義如下:
bash run.sh <kernel_name> <soc_version> <core_type> <run_mode>
<kernel_name>表示需要運(yùn)行的算子。
<soc_version>表示算子運(yùn)行的AI處理器型號(hào)。
<core_type>表示在AI Core上或者Vector Core上運(yùn)行,參數(shù)取值為AiCore/VectorCore。
<run_mode>表示算子以cpu模式或npu模式運(yùn)行,參數(shù)取值為cpu/npu。
kernel實(shí)現(xiàn)
函數(shù)原型定義
本樣例中,函數(shù)名為leakyrelu_custom,根據(jù)對(duì)算子輸入輸出的分析,確定有2個(gè)參數(shù)x,y,其中x為輸入內(nèi)存,y為輸出內(nèi)存。核函數(shù)原型定義如下所示:
extern "C" __global__ __aicore__ void leakyrelu_custom(GM_ADDR x, GM_ADDR y, GM_ADDR workspace, GM_ADDR tiling){ }
使用__global__函數(shù)類(lèi)型限定符來(lái)標(biāo)識(shí)它是一個(gè)核函數(shù),可以被<<<...>>>調(diào)用;使用__aicore__函數(shù)類(lèi)型限定符來(lái)標(biāo)識(shí)該核函數(shù)在設(shè)備端AI Core上執(zhí)行;為方便起見(jiàn),統(tǒng)一使用GM_ADDR宏修飾入?yún)ⅲ珿M_ADDR宏定義:
#define GM_ADDR __gm__ uint8_t* __restrict__
獲取tilling數(shù)據(jù),并調(diào)用算子類(lèi)的Init和Process函數(shù)。
算子類(lèi)的Init函數(shù),完成內(nèi)存初始化相關(guān)工作,Process函數(shù)完成算子實(shí)現(xiàn)的核心邏輯。
extern "C" __global__ __aicore__ void leakyrelu_custom(GM_ADDR x, GM_ADDR y, GM_ADDR workspace, GM_ADDR tiling)
{
GET_TILING_DATA(tilingData, tiling);
KernelLeakyRelu op;
op.Init(x, y, tilingData.totalLength, tilingData.tileNum, tilingData.scalar);
op.Process();
}
對(duì)核函數(shù)的調(diào)用進(jìn)行封裝
封裝后得到leakyrelu_custom_do函數(shù),便于主程序調(diào)用。#ifndef __CCE_KT_TEST__表示該封裝函數(shù)僅在編譯運(yùn)行NPU側(cè)的算子時(shí)會(huì)用到,編譯運(yùn)行CPU側(cè)的算子時(shí),可以直接調(diào)用add_custom函數(shù)。調(diào)用核函數(shù)時(shí),除了需要傳入輸入輸出參數(shù)x,y,切分相關(guān)參數(shù)tiling,還需要傳入blockDim(核函數(shù)執(zhí)行的核數(shù)), l2ctrl(保留參數(shù),設(shè)置為nullptr), stream(應(yīng)用程序中維護(hù)異步操作執(zhí)行順序的stream)來(lái)規(guī)定核函數(shù)的執(zhí)行配置。
#ifndef __CCE_KT_TEST__
// call of kernel function
void leakyrelu_custom_do(uint32_t blockDim, void* l2ctrl, void* stream, uint8_t* x, uint8_t* y,
uint8_t* workspace, uint8_t* tiling)
{
leakyrelu_custom<<<blockDim, l2ctrl, stream>>>(x, y, workspace, tiling);
}
#endif
獲取tiling參數(shù)
主要從tilingPointer中獲取tiling的參數(shù)totalLength(總長(zhǎng)度)、tileNum(切分個(gè)數(shù),單核循環(huán)處理數(shù)據(jù)次數(shù))和scalar(LeakyRelu計(jì)算標(biāo)量)。
#define GET_TILING_DATA(tilingData, tilingPointer) \
LeakyReluCustomTilingData tilingData; \
INIT_TILING_DATA(LeakyReluCustomTilingData, tilingDataPointer, tilingPointer); \
(tilingData).totalLength = tilingDataPointer->totalLength; \
(tilingData).tileNum = tilingDataPointer->tileNum; \
(tilingData).scalar = tilingDataPointer->scalar;
#endif // LEAKYRELU_CUSTOM_TILING_H
Init函數(shù)
主要獲取tiling數(shù)據(jù)后,設(shè)置單核上gm的地址和Buffer的初始化。
__aicore__ inline void Init(GM_ADDR x, GM_ADDR y, uint32_t totalLength, uint32_t tileNum, float scalar)
{
ASSERT(GetBlockNum() != 0 && "block dim can not be zero!");
this->blockLength = totalLength / GetBlockNum();
this->tileNum = tileNum;
this->scalar = static_cast<half>(scalar);
ASSERT(tileNum != 0 && "tile num can not be zero!");
this->tileLength = this->blockLength / tileNum / BUFFER_NUM;
// get start index for current core, core parallel
xGm.SetGlobalBuffer((__gm__ half*)x + this->blockLength * get_block_idx(), this->blockLength);
yGm.SetGlobalBuffer((__gm__ half*)y + this->blockLength * get_block_idx(), this->blockLength);
// pipe alloc memory to queue, the unit is Bytes
pipe.InitBuffer(inQueueX, BUFFER_NUM, this->tileLength * sizeof(half));
pipe.InitBuffer(outQueueY, BUFFER_NUM, this->tileLength * sizeof(half));
}
Process函數(shù)
主要實(shí)現(xiàn)三個(gè)CopyIn、Compute、CopyOut這三stage。
__aicore__ inline void Process()
{
// loop count need to be doubled, due to double buffer
int32_t loopCount = this->tileNum * BUFFER_NUM;
// tiling strategy, pipeline parallel
for (int32_t i = 0; i < loopCount; i++) {
CopyIn(i);
Compute(i);
CopyOut(i);
}
}
CopyIn函數(shù)
負(fù)責(zé)從Global Memory拷貝數(shù)據(jù)到Local Memory,并將數(shù)據(jù)加入Queue
__aicore__ inline void CopyIn(int32_t progress)
{
// alloc tensor from queue memory
LocalTensor<half> xLocal = inQueueX.AllocTensor<half>();
// copy progress_th tile from global tensor to local tensor
DataCopy(xLocal, xGm[progress * tileLength], tileLength);
// enque input tensors to VECIN queue
inQueueX.EnQue(xLocal);
}
Compute函數(shù)
負(fù)責(zé)從Queue中取出數(shù)據(jù),進(jìn)行計(jì)算,并將結(jié)果放入Queue
__aicore__ inline void Compute(int32_t progress)
{
// deque input tensors from VECIN queue
LocalTensor<half> xLocal = inQueueX.DeQue<half>();
LocalTensor<half> yLocal = outQueueY.AllocTensor<half>();
// call LeakyRelu instr for computation
LeakyRelu(yLocal, xLocal, scalar, tileLength);
// enque the output tensor to VECOUT queue
outQueueY.EnQue<half>(yLocal);
// free input tensors for reuse
inQueueX.FreeTensor(xLocal);
}
CopyOut函數(shù)
負(fù)責(zé)從Queue中將數(shù)據(jù)取出,并將數(shù)據(jù)從Local Memory拷貝到Global Memory。
__aicore__ inline void CopyOut(int32_t progress)
{
// deque output tensor from VECOUT queue
LocalTensor<half> yLocal = outQueueY.DeQue<half>();
// copy progress_th tile from local tensor to global tensor
DataCopy(yGm[progress * tileLength], yLocal, tileLength);
// free output tensor for reuse
outQueueY.FreeTensor(yLocal);
}
編譯和執(zhí)行
在CPU側(cè)執(zhí)行
執(zhí)行結(jié)果如下:
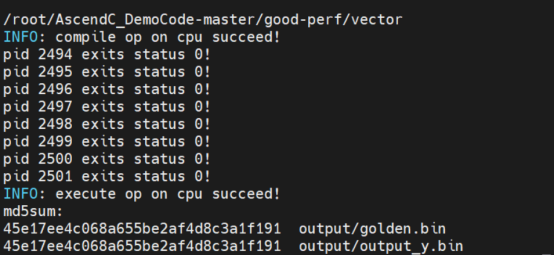
可以看到最后的輸出結(jié)果output_y.bin和標(biāo)桿數(shù)據(jù)golden.bin的MD5值相同,說(shuō)明計(jì)算結(jié)果相同。
執(zhí)行完成后,在input下存放輸入數(shù)據(jù)和tiling數(shù)據(jù),在output下面存放了輸出數(shù)據(jù)和標(biāo)桿數(shù)據(jù),npuchk目錄下是每個(gè)核的npu_check執(zhí)行結(jié)果
在當(dāng)前目錄還有一個(gè)可執(zhí)行二進(jìn)制文件leakyrelu_custom_cpu,如果執(zhí)行報(bào)錯(cuò),可以通過(guò)gdb調(diào)試這個(gè)可執(zhí)行文件,具體調(diào)試可參考文末官方教程。
在NPU側(cè)執(zhí)行
在NPU側(cè)執(zhí)行有兩種方式:仿真執(zhí)行和上板運(yùn)行,命令都相同,只是編譯選項(xiàng)不同,我們可以通過(guò)修改編譯選項(xiàng)-DASCEND_RUN_MODE為SIMULATOR運(yùn)行CAModel仿真,設(shè)置為 ONBOARD是上板運(yùn)行。
function compile_and_execute() {
# 使用cmake編譯cpu側(cè)或者npu側(cè)算子, SIMULATOR or ONBOARD
mkdir -p build; cd build; \
cmake .. \
-Dsmoke_testcase=$1 \
-DASCEND_PRODUCT_TYPE=$2 \
-DASCEND_CORE_TYPE=$3 \
-DASCEND_RUN_MODE="SIMULATOR" \
-DASCEND_INSTALL_PATH=$ASCEND_HOME_DIR
VERBOSE=1 cmake --build . --target ${1}_${4}
……
}
參考資料
總之,學(xué)習(xí)Ascend C,僅需了解C++編程、理解對(duì)列通信與內(nèi)存申請(qǐng)釋放機(jī)制、通過(guò)調(diào)用相應(yīng)的計(jì)算接口與搬運(yùn)接口,就可以寫(xiě)出運(yùn)行在昇騰AI處理器上的高性能算子。
了解更多Ascend C學(xué)習(xí)資源,請(qǐng)?jiān)L問(wèn)官方教程:Ascend C編程指南(官方教程)