













分布式數據庫:管理和存儲大規模數據
作者:高級互聯網架構
在數字化時代,數據規模不斷增長,許多企業面臨著存儲和管理海量數據的挑戰。分布式數據庫成為了解決這一問題的重要工具,它可以有效地管理和存儲大規模的數據,支持高可用性和擴展性的需求。
在數字化時代,數據規模不斷增長,許多企業面臨著存儲和管理海量數據的挑戰。分布式數據庫成為了解決這一問題的重要工具,它可以有效地管理和存儲大規模的數據,支持高可用性和擴展性的需求。
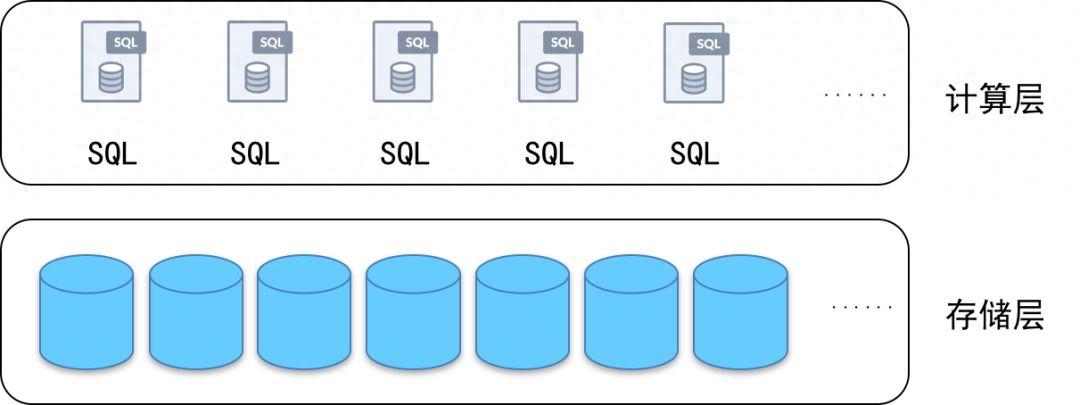
什么是分布式數據庫?
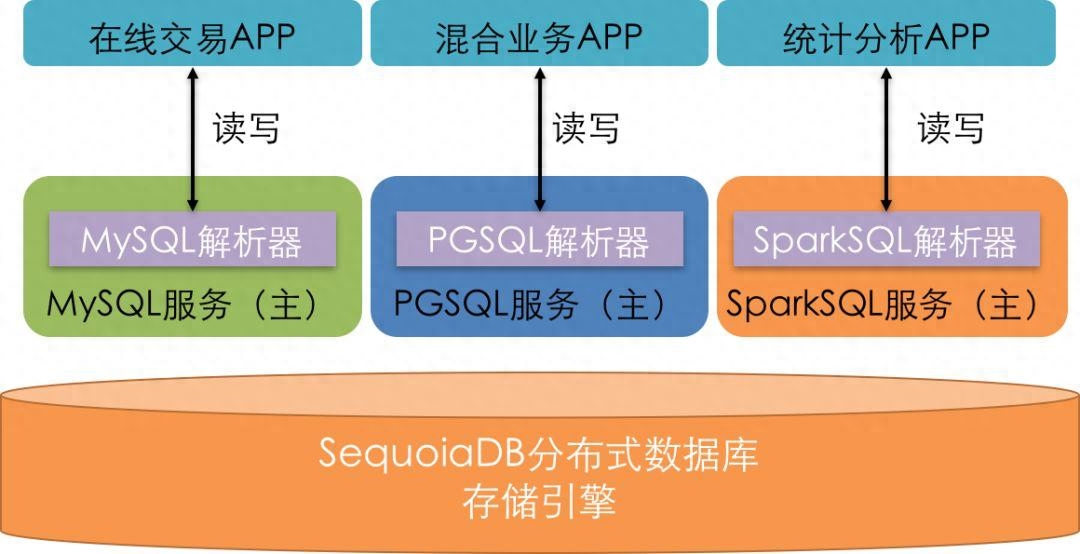
分布式數據庫是一種數據庫系統,將數據存儲在多個物理節點上,通過分布式計算和存儲技術來實現數據的管理。相比傳統的單機數據庫,分布式數據庫具有更高的可擴展性和容錯性,能夠處理大規模的數據和高并發的訪問請求。
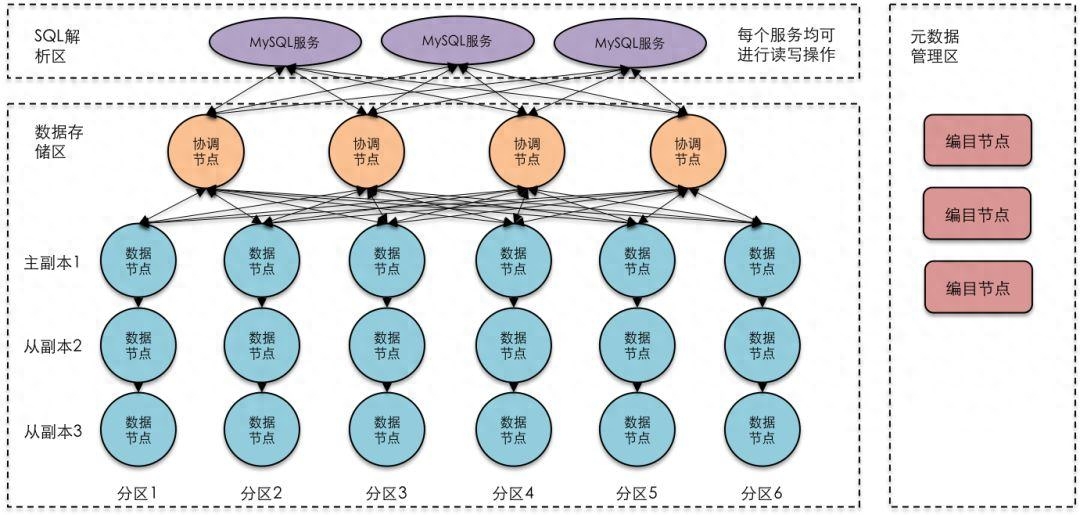
分布式數據庫的優勢
- 擴展性: 分布式數據庫可以輕松地擴展,通過增加節點來應對數據規模的增長,無需對整個系統進行重構。
- 高可用性: 分布式數據庫通常具備數據冗余和故障轉移的能力,即使部分節點發生故障,數據仍然可用。
- 性能: 分布式數據庫可以將數據分布在多個節點上,從而減少單節點的負載,提升查詢性能。
- 靈活性: 分布式數據庫可以根據不同的業務需求和數據類型選擇合適的存儲引擎和分布策略。
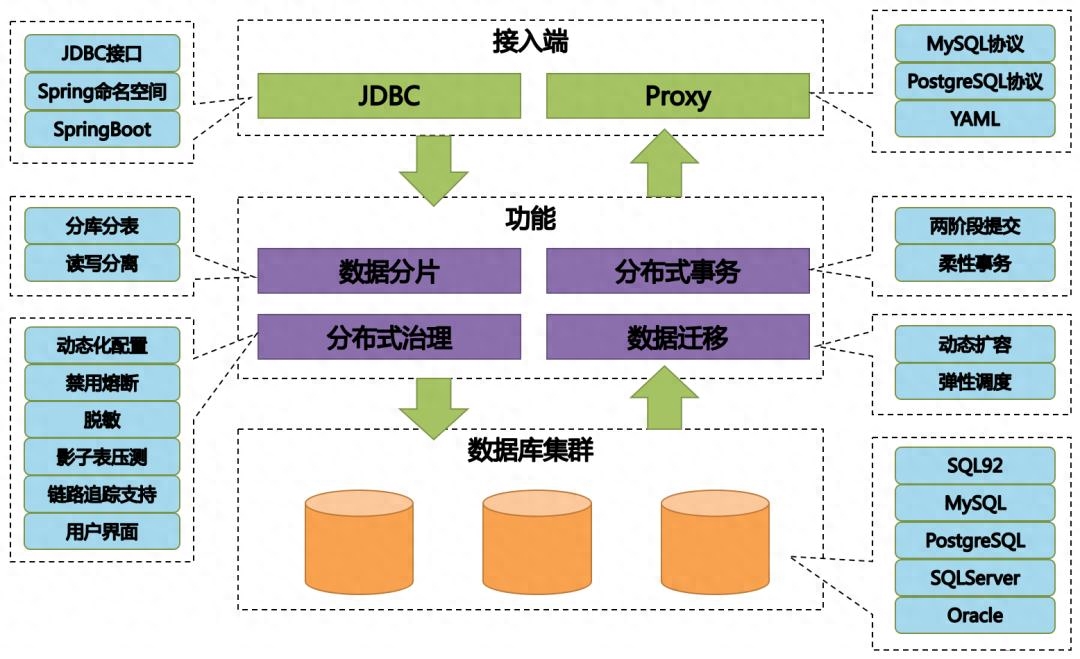
分布式數據庫的應用場景
- 大數據分析: 分布式數據庫可以支持大規模數據的分析和挖掘,幫助企業從數據中獲得洞察和價值。
- 實時應用: 對于需要實時處理和響應的應用,分布式數據庫能夠提供快速的數據訪問和查詢。
- 云原生應用: 在云計算環境下,分布式數據庫可以輕松適應不斷變化的資源需求。
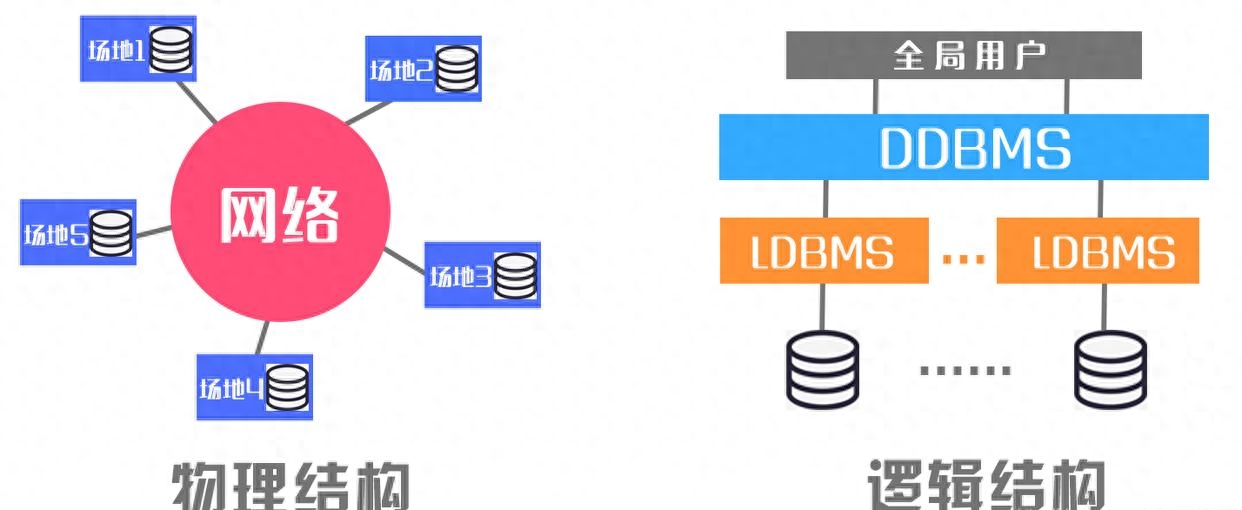
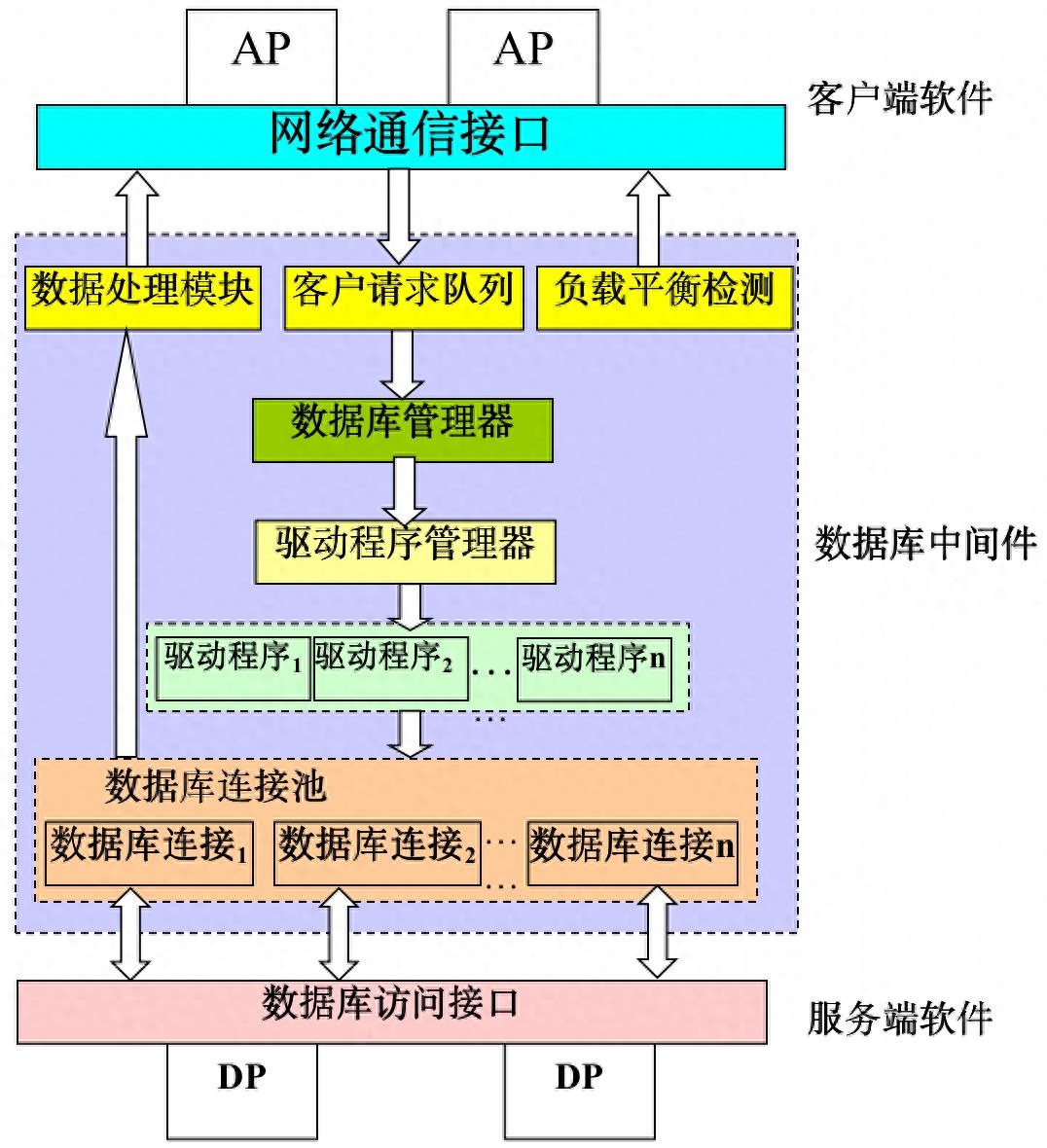
分布式數據庫的挑戰與注意事項
- 一致性與分區: 分布式數據庫需要解決數據一致性和分區的問題,確保數據的正確性和完整性。
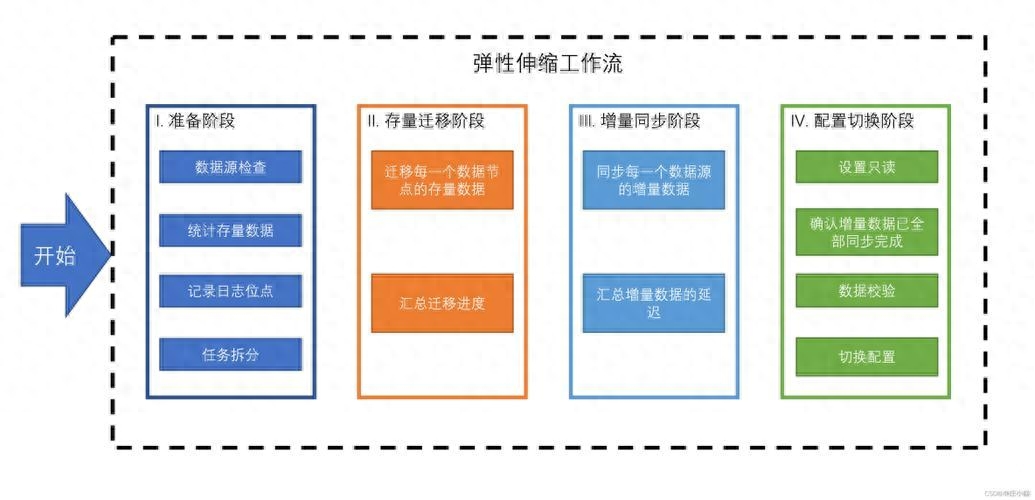
- 數據遷移: 分布式數據庫的擴展和變更可能需要進行數據遷移,需要謹慎規劃和執行。
- 復雜性: 分布式數據庫的配置、管理和維護相對復雜,需要專業的技術團隊。
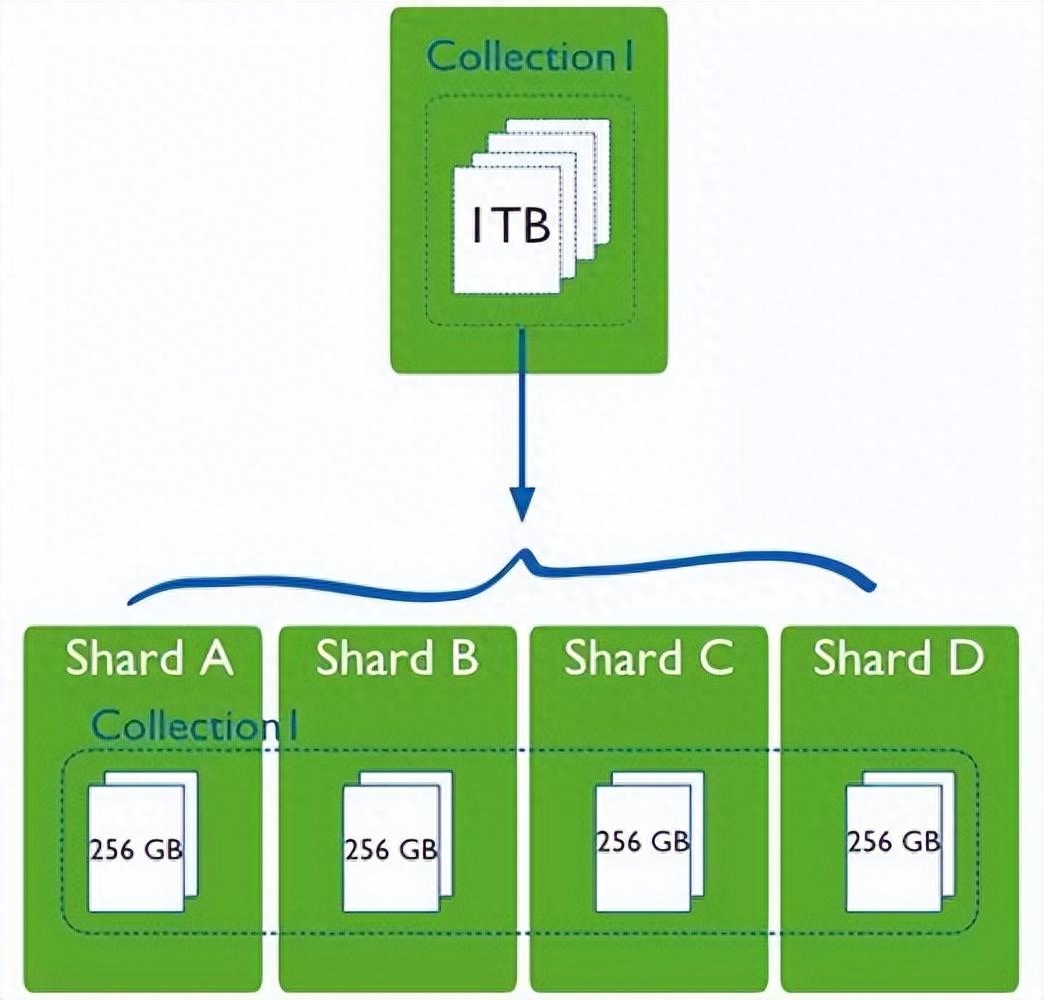
常見的分布式數據庫系統
- Apache HBase: 基于Hadoop的分布式數據庫,適用于海量結構化數據的存儲。
- Cassandra: 高可用性的分布式數據庫,適用于高寫入和高可擴展性的場景。
- MongoDB: NoSQL數據庫,適用于半結構化和非結構化數據的存儲和查詢。
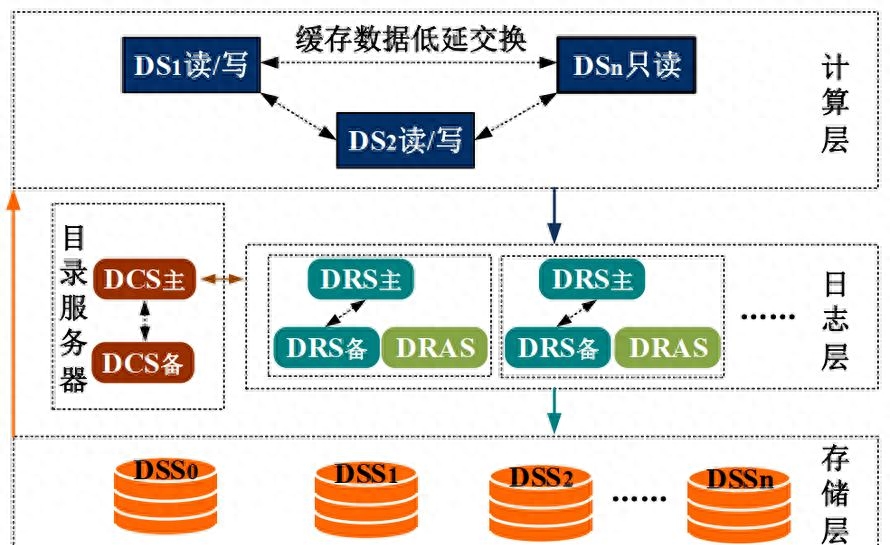
結論
分布式數據庫在處理大規模數據和高并發訪問方面具有明顯的優勢。通過有效地管理和存儲數據,分布式數據庫能夠支持企業的大數據分析、實時應用和云原生架構。然而,構建和維護分布式數據庫也面臨一些挑戰,需要在設計和實施過程中注意一致性、數據遷移等問題。綜合來看,分布式數據庫為企業提供了強大的數據管理和存儲工具,為業務的發展和創新提供了有力支持。
責任編輯:華軒
來源:
今日頭條






















