LLM在放射科學中應用潛力如何?數十家研究機構聯合測試了31個大模型
近年來,大型語言模型(LLM)在自然語言領域(NLP)掀起了革新的狂潮,在大規模、高質量數據訓練的驅動下,LLM 在多種領域都展現出卓越的性能。LLMs 的崛起不僅讓我們重新審視了自然語言的處理方式,更是為多個領域注入了革新的 “新鮮血液”。值得注意的是,近期像 ChatGPT、BLOOM、Llama 這樣的 LLM 正在大量涌現與飛速進化,令人嘆為觀止。更令人興奮的是,國內多個優秀模型,如 Ziya-LLaMA、ChatGLM、baichuan 等,也在 LLM 的世界舞臺上嶄露頭角。這一潮流不僅見證了 LLM 不斷涌現和更新迭代,還展示了它們在醫療健康領域的巨大潛力。
在這一浪潮中,放射學 NLP 領域備受矚目,LLM 在這個領域的發展和應用更是已經成為不可忽視的趨勢。然而,盡管 LLMs 發展趨勢迅猛,系統性地評估它們在放射科 NLP 能力上的研究還遠遠不足,尤其是對來自像中國這樣的多語言國家的新興模型的研究:這些模型在英文和中文(等其它語言)的多語言處理能力方面有獨特的優勢,但卻鮮有深入的科學性能評估研究。在醫學和放射學領域,我們正面臨著一個亟需填補的知識空白。
因此,我們認為有必要對這些全球性 LLMs 進行嚴格且系統性的探索和分析。這不僅有助于更全面、更深入地了解它們的能力和局限性,還能將它們有機地融入全球 LLMs 的生態系統中之中,從而推進全球醫療領域、放射學領域 LLM 社區的發展。本研究旨在通過廣泛測試全球 31 個主流 LLMs 在兩個公開放射科數據集 (MIMIC-CXR 和 OpenI) 上的性能,驗證它們在生成放射學診斷信息(impression)的能力。

論文地址:https://arxiv.org/pdf/2307.13693.pdf
在這項研究中,我們采用了一系列具體指標來評估模型,模型的評估標準均基于它們從放射學發現生成診斷信息的能力,通過具體指標來驗證模型所生成診斷信息的質量。所用指標包括零樣本(zero-shot)、一樣本(one-shot)和五樣本(five-shot)條件下的 Recall@1、Recall@2 和 Recall@L。通過將這 31 個國際主流 LLMs 在這些指標上進行 “競爭”,我們旨在揭示它們在放射學領域的相對優勢和劣勢,為 LLMs 在放射學領域的應用提供更加深入的理解。
值得一提的是,這項研究的成果不僅有助于推動放射學自然語言處理工具和LLM的優化和開發,而且這些 LLM 模型也將成為放射科醫師和廣泛醫學界的寶貴工具,推動放射學 NLP 領域的發展。在這個充滿挑戰和機遇的時刻,我們對 LLMs 在放射學領域的應用充滿信心,并期待它們在未來的發展中發揮更加重要的作用。
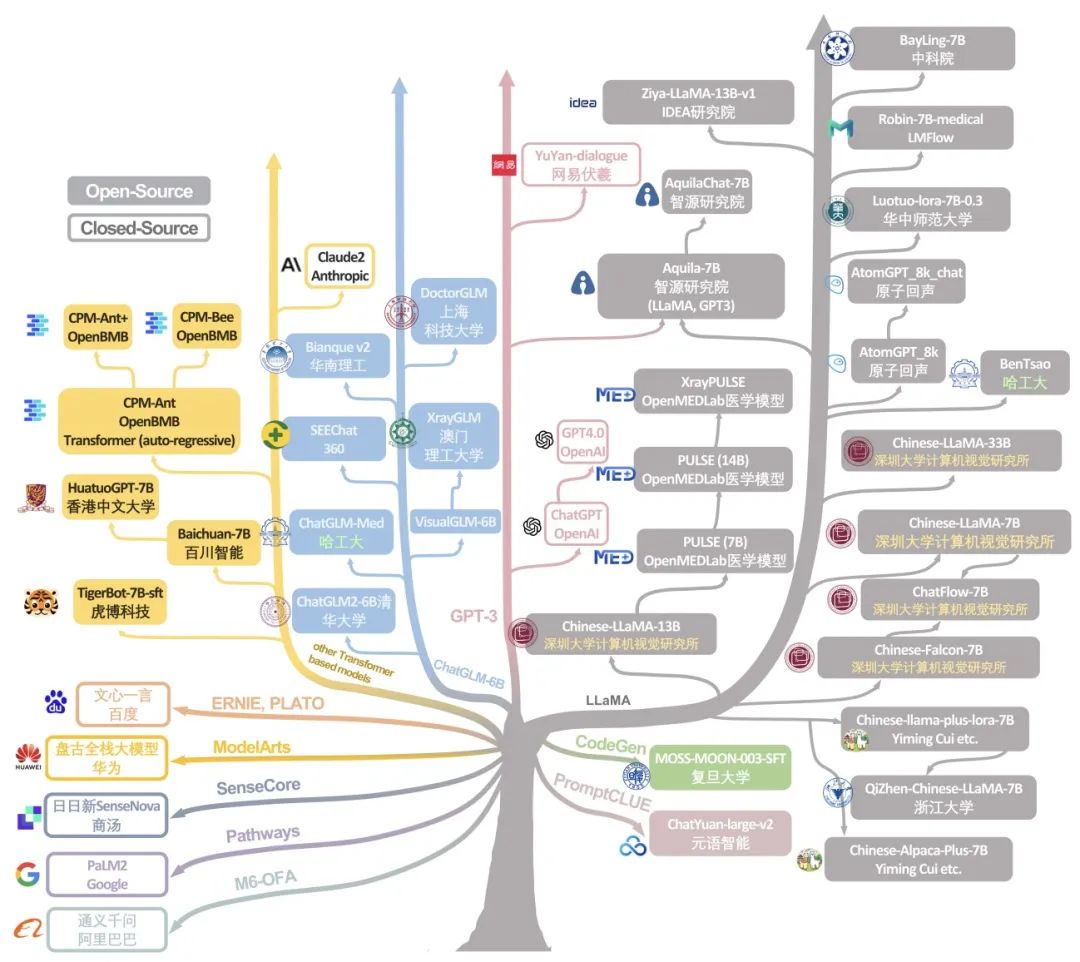
方法介紹
測試方法
對于整體實驗,我們會使用一些精心設計的 prompt 和推理參數來測試這 31 個大模型。對于三類樣本數推理測試,即 zero-shot、one-shot 以及 five-shot inference,我們結合專業醫療意見,對每種都設計了專有、統一的 Prompt 來進行測試。結合過程中的測試的效果,我們在大量實驗中總結、固定了推理參數,即 temperature=0.9、top-k=40 以及 top-p=0.9。
模型選擇
鑒于資源和比較一致性的考慮,我們集中評估了擁有約 70 億參數的大型語言模型(LLMs)。這個參數規模被選中是因為它在計算效率和性能之間取得了平衡,使得在高效地全面評估成為可能,并能夠代表不同類型的 LLMs 性能。對于開源模型,我們從官方 GitHub 存儲庫獲取了代碼和模型參數,確保了正確的實施和評估。而對于商業模型,我們利用它們的應用程序編程接口(APIs),以一致可靠的方式與模型進行交互,確保了評估的準確性和一致性。
測試 Prompt
為了確保在不同的 LLM 之間進行公平而公正的比較,不論是 zero-shot、one-shot,還是 five-shot 的情形,我們都嚴格遵循相同的提示設置,保持了一致性。在 zero-shot 評估中,模型將面對全新的任務,沒有任何之前的示例可供參考。而在 one-shot 的情景下,我們向模型提供了一個先前的示例作為參考。同時,在 five-shot 的情況下,模型將得到五個示例供其學習。所有的示例都是結合醫療建議嚴格挑選、設計。這些評估場景旨在模擬真實世界的使用條件,其中模型只獲得有限數量的示例,并需要從中推導出通用規則。
數據集
我們的研究充分利用了 MIMIC-CXR 和 OpenI 兩個放射學領域廣泛使用的公開數據集,評估了大型語言模型(LLMs)在生成放射學文本報告方面的性能。我們的研究重點集中在放射學報告的 “Finding” 和 “Impression” 部分,這些部分提供了對影像結果和放射科醫師的詳細解釋性文本信息。
實驗結果
在 OpenI 數據集上,Anthropic 的 Claude2 實現了最佳的 zero-shot 表現,而 BayLing-7B 在 five-shot 中領先。在 MIMIC-CXR 上,Claude2 再次在 zero-shot 中排名第一,PaLM2 在 one-shot 中排名第一,BayLing-7B 在 five-shot 中領先。
我們觀察到在不同模型之間存在顯著的性能差異。這些全面的測試結果為每個 LLM 在放射科應用中提供了質量指標數據,為領域研究者提供了關于其豐富的優勢和劣勢的深刻見解。
眾多的實驗結果表明,國內許多新興 LLM 與全球對手相比也有充分的競爭力,能夠在全球性的舞臺上作為后起之秀與全世界的對手一決高下。但是,像 AtomGPT_8k 這樣的一些模型在所有設置下的表現都很差。總體而言,模型大小并不意味著表現一定優越與否,更重要的是對于模型應用領域的適應性,我們的結果正是強調了根據特定放射科任務而不是模型大小本身來仔細選擇 LLM 的重要性,我們的工作正是為現在 LLM 研究中模型大小與效果優劣的相關問題拋出了預見性的 “橄欖枝”,為日后更為高效的 LLM 研究提供了經驗知識。


結論
這項開創性的研究對來自全球各大團隊的 LLM 在解釋放射科報告這一領域進行了詳盡的評估。關于模型之間能力和性能的差距所獲得的見解將作為引導未來擴展 LLM 以增強在放射科領域、乃至更多醫療健康領域實踐的堅固基石。通過審慎的應用和開發,LLM 在促進全球醫療保健交付方面顯示出巨大的前景。
但是,總體而言結果中 LLM 局限的能力(仍然不夠高的指標得分)預示著還需要開展持續的研究,開發更具有專業性、領域性、精確性的多語言和多模態 LLM, 以充分發揮它們在不同醫學專業中的潛力,這將為全世界的醫療行業提供啟發與便利,并且也是通用人工智能(AGI)在醫療行業中又一強大可能性。
總之,本全面基準測試研究對于 LLM 作為全球放射科醫生的寶貴工具的采用做出了重要貢獻,推進了全球 LLM 社區,尤其是在放射學、醫療領域的發展,為 AGI 在醫療領域的進一步實踐、發展提供了重要啟示。