













作者 | 崔皓
審校 | 重樓
摘要
隨著LLM(大語言模型)的發展,最近流行起利用大語言模型對源代碼進行分析的潮流。網絡博主紛紛針對GitHub Co-Pilot、Code Interpreter、Codium和Codeium上的代碼進行分析。我們也來湊個熱鬧,利用OpenAI 的GPT-3.5-Turbo和LangChain對LangChain的源代碼進行分析。
開篇
眾所周知,作為程序員經常會和源代碼打交道,很多情況下,當程序員遇到新代碼庫,或者是遺留項目的代碼庫,都有些手足無措。特別是要在已有的代碼庫中進行修改,那更是舉步維艱,生怕走錯一步成千古恨。例如:不清楚類,方法之間的關系,不清楚函數之間的業務邏輯。不過現在不用擔心了,有了大語言模型的加持,已讓閱讀代碼不是難事,對代碼庫的整體分析也是小菜一碟。
總結來說,可以通過大語言模型進行如下操作:
1. 通過對代碼庫進行問答,以了解其工作原理。
2. 利用LLM提供重構或改進建議。
3. 使用LLM對代碼進行文檔化。
今天我們就從代碼庫問答開始,帶大家手把手編寫代碼庫問答的程序。
整體介紹
首先,我們來整理一些思路,如圖1 所示。我們會先下載LangChain的源代碼,將source code的目錄以及目錄下面的所有源代碼文件保存到磁盤上。然后再對其進行加載和轉換,也就是圖中紅色的部分。將這些代碼文件切割成小的文件塊,用來Embedding操作。也就是將其嵌入到向量數據庫中,即圖中橙色的部分。接著,圖中最右邊用戶會請求大模型,這里的模型我們使用GPT-3.5-Turbo,請求模型提問與LangChain源代碼相關的問題,例如:“在LangChain中如何初始化ReAct agent “。此時,GPT-3.5-Turbo的大語言模型會從向量數據庫中獲取相關信息,并且返回給用戶。
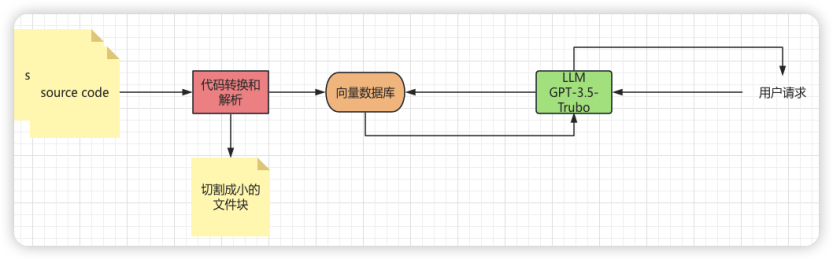 圖1 源代碼庫提問思路整理
圖1 源代碼庫提問思路整理
具體來說,可以采用一種分割策略,其機制由如下幾個步驟組成:
1. 將代碼中的每個頂級函數和類加載到單獨的文檔中。
2. 將剩余部分加載到另一個獨立的文檔中。
3. 保留關于每個分割來自何處的元數據信息。
不過,這些步驟都是由LangChain內部機制實現的, 我們只需要調用簡單的代碼就可以完成。
整個代碼的構建和處理過程如上面圖1 所示,接下來我們就可以編寫代碼,大概會分如下幾個步驟:
- 下載LangChain代碼
- 在VS Code導入代碼
- 安裝相關依賴
- 裝載LangChain的源代碼文件
- 切割文件
- 嵌入到向量數據庫
- 利用大模型進行查詢
- 返回查詢結果
下面,我們就按照步驟來逐一介紹。
下載LangChain代碼
首先,有請我們的主角LangChain源代碼登場。 如圖2 所示,可以通過訪問地址:https://github.com/langchain-ai/langchain,來查看源代碼庫。
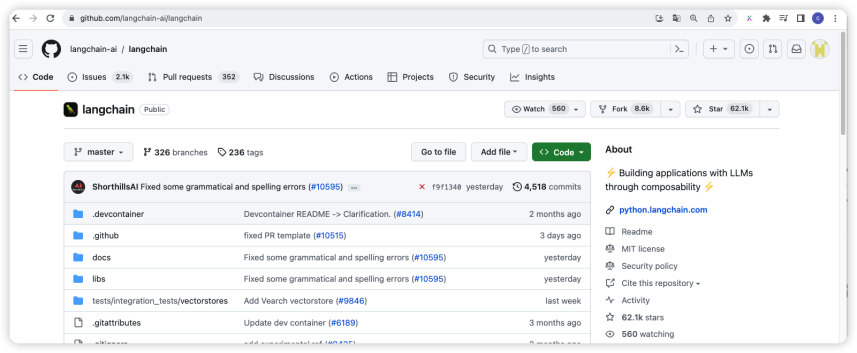 圖2 LangChain源代碼庫
圖2 LangChain源代碼庫
當然可以通過Clone方法下載代碼,或者使用如圖3所示的方式,直接下載zip包然后解壓。
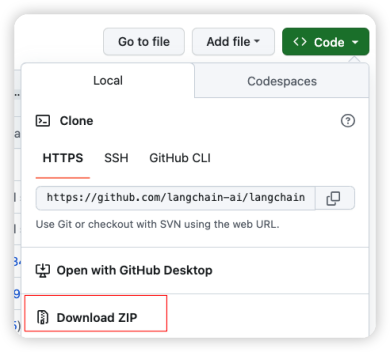 圖3 下載LangChain源代碼
圖3 下載LangChain源代碼
下載之后進行解壓,請記住解壓的目錄后面會用到。
在VS Code導入代碼
在解壓LangChain的源代碼庫之后,將其導入到VS Code中。 如圖3 所示,在VS Code中加載,在LANGCHAIN-MASTER目錄下面的 /libs/langchain/langchain下面就是我們的目標目錄了。里面存放著LangChain的源代碼,接下來就需要對這個目錄進行掃描讀取器中的文件。
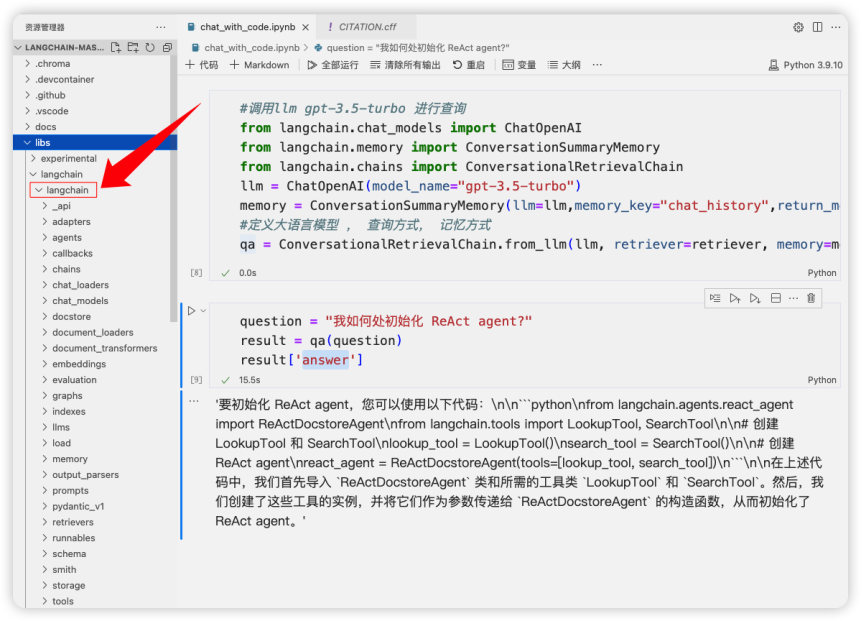 圖3LangChain代碼庫所在位置
圖3LangChain代碼庫所在位置
安裝相關依賴
在對代碼庫進行加載之前,我們先創建對應的Jupyter Notebook文件。如圖4 所示,為了方便我們在源代碼的根目錄下面創建chat_with_code.ipynb文件。
 圖4 源代碼文件結構
圖4 源代碼文件結構
在文件中加入一些依賴包如下,分別加載了OpenAI的包,它是用來應用GPT-3.5-Turbo模型的。Tiktoken 是用來處理NLP(自然語言處理)任務的,例如:分詞,嵌入,計算文本長度。ChromDB 是向量數據庫的包,源代碼文件會保存在這里,以便后續查詢。另外,LangChain的包是進行一些操作的腳手架,少了它程序玩不轉。
#引入依賴包
#openai gpt 模型
#tiktoken NLP 處理
#chromadb 向量數據庫
#langchain llm 腳手架
pip install openai tiktoken chromadb langchain安裝完了依賴包之后,需要獲取環境變量配置。因為要使用OpenAI的API去調用大模型,所以需要加入如下代碼:
#通過環境配置的方式獲取openai 訪問api的key
import dotenv
dotenv.load_dotenv()需要說明的是,我們在源代碼根目錄下面創建了一個”.env”文件,文件中寫入如下代碼:
OPENAI_API_KEY= openaikey用來存放OpenAI的 key。
裝載LangChain的源代碼文件
引入依賴包之后就可以加載LangChain的源代碼文件了。 如下代碼,我們先引入幾個LangChain的Class幫助我們加載代碼。
#基于編程語言的字符切割
from langchain.text_splitter import Language
#大文件的裝載
from langchain.document_loaders.generic import GenericLoader
#解析編程語言的語法
from langchain.document_loaders.parsers import LanguageParser- langchain.text_splitter 中的Language可以幫助我們基于編程語言進行文件的切割。
- langchain.document_loaders.generi中的GenericLoader可以進行大文件的加載,因為可能會遇到類文件比較大的情況。
- langchain.document_loaders.parsers中的LanguageParser是用來對類和方法進行解析的。
接著定義源代碼所在的路徑。
#定義源代碼所在的目錄
repo_path ="/Users/cuihao/doc/39 - GPT/langchain-master"然后就可以開始加載Python文件了。
#加載文件(s)多個文件
loader = GenericLoader.from_filesystem(
repo_path+"/libs/langchain/langchain",
#加載所有目錄下的所有文件
glob="**/*",
#針對.py的文件進行加載
suffixes=[".py"],
#激活解析所需的最小行數
parser=LanguageParser(language=Language.PYTHON, parser_threshold=500)
)
documents = loader.load()
len(documents)從上面的代碼可以看出通過GenericLoader的from_filesystem方法進行多目錄下文件的加載。首先,傳入源代碼所在的根目錄。接著,通過glob 參數定義所有目錄下的所有文件是我們的目標文件。再就是定義處理文件的后綴是”.py”。最后,使用了LanguageParser方法針對Python進行解析,并且指定每次激活解析的代碼行數是 500。
切割文件
有了加載以后的文件,我們將其給到Documents變量中,接著就是對Documents進行切割。一般而言大模型都有輸入限制的要求,如下面代碼所示:
#對加載好的py 文件進行切割
#ChatGPT 最大的輸入是2048
from langchain.text_splitter import RecursiveCharacterTextSplitter
python_splitter = RecursiveCharacterTextSplitter.from_language(
language=Language.PYTHON,
#每個切割之后的文件的大小
chunk_size=2000,
#文件與文件之間的重合部分是200
chunk_overlap=200)
#將所有源代碼文件切割成小的文件塊,以便llm 能夠進行嵌入
texts = python_splitter.split_documents(documents)
len(texts)這里利用LangChain.text_splitter包中的RecursiveCharacterTextSplitter函數對源代碼進行切割。文件塊的大小是2000字節,文件之間重合的部分是200字節。將切割好的文件塊賦給texts變量,這里的texts實際上是一個文件塊的數組,后面將會將這個數組嵌入到向量數據庫chroma中。
這里需要對文件塊切割的chunk_size和chunk_overlap兩個參數做一下說明。如圖5 所示,如果我們對文件按照長度進行切割,切割的文字很有可能丟失上下文。例如:“我們去公園玩好不好,如果天氣好的”,這樣一句話一定是不完整的,大模型在進行學習或者推理的時候會丟失一部分信息。在自然語言中是這樣,在代碼解析中也是如此。
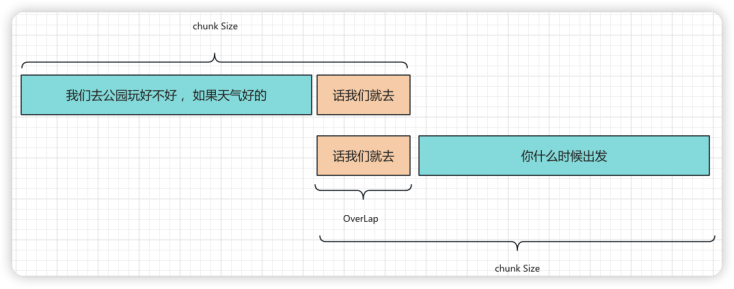 圖5 自然語言的文本切割
圖5 自然語言的文本切割
因此,我們在切割的時候會保存一部分文字塊的上下文信息。圖中“話我們就去”就是這部分信息,我們稱之為“overlap”也就是相互覆蓋的部分。這樣每個文字塊都可以保留它相鄰文字塊的部分信息,最大限度地保證了上下文信息的完整性,在代碼解析中我們也會沿用這種做法。
嵌入到向量數據庫
文件分塊完成以后,接下來將把這些代碼形成的文件塊嵌入到向量數據庫中了。只有嵌入進去以后,才能方便后續用戶的查詢。如下代碼所示,利用OpenAI中的OpenAIEmbeddings函數將texts,也就是切割好的代碼文件保存到chroma的向量數據庫中。
from langchain.vectorstores import Chroma
from langchain.embeddings.openai import OpenAIEmbeddings
#將切割好的文件塊嵌入到向量數據庫中, chroma db
db = Chroma.from_documents(texts, OpenAIEmbeddings(disallowed_special=()))
#定義如何查詢代碼
retriever = db.as_retriever(
#Maximal Marginal Relevance (最大邊際相關性)= 相關性 + 多樣性
search_type="mmr",# Also test "similarity"
#控制在檢索中返回的文檔數量
search_kwargs={"k":8},
)不僅如此,還針對向量數據庫創建了Retriever 作為索引器,幫助后續查找。其中有兩個參數,第一個search_type定義的是mmr,這個是Maximal Marginal Relevance (最大邊際相關性)的縮寫。它是一種相關性查詢的方式,同時考慮了查詢目標的相關性和多樣性。還有一個參數search_kwargs 定義了k 為8,這個是匹配相關文檔的數量。
利用大模型進行查詢
經過上面的步驟離我們的目標已經不遠了。創建GPT-3.5-Turbo模型的查詢是當務之急。如下代碼所示,引入ChatOpenAI函數創建GPT-3.5-Turbo的模型實體。接著使用ConversationSummaryMemory創建有記憶的對話,最重要的是使用ConversationalRetrievalChain,從名字上可以看出來是基于對話的索引器,它以Chain的方式存在。Chain是LangChain的核心組件,用來將其他組件,例如:Model I/O,DataConnection,Agent等組合使用。這里它將大模型(LLM),索引器(Retriever)以及記憶組件(Memory)整合在一起進行問答響應。
#調用llm gpt-3.5-turbo 進行查詢
from langchain.chat_models import ChatOpenAI
from langchain.memory import ConversationSummaryMemory
from langchain.chains import ConversationalRetrievalChain
llm = ChatOpenAI(model_name="gpt-3.5-turbo")
memory = ConversationSummaryMemory(llm=llm,memory_key="chat_history",return_messages=True)
#定義大語言模型 , 查詢方式, 記憶方式
qa = ConversationalRetrievalChain.from_llm(llm,retriever=retriever,memory=memory)返回查詢結果
萬事俱備只欠東風,我們通過如下代碼開始提問。
question ="我如何處初始化 ReAct agent?"
result = qa(question)
result['answer']GPT-3.5-Turbo的回復如下:
要初始化 ReAct agent,您可以使用以下代碼:
from langchain.agents.react_agent import ReActDocstoreAgent
from langchain.tools import LookupTool, SearchTool
# 創建 LookupTool 和 SearchTool
lookup_tool = LookupTool()
search_tool = SearchTool()
# 創建 ReAct agent
react_agent =ReActDocstoreAgent(tools=[lookup_tool, search_tool])
在上述代碼中,我們首先導入 ReActDocstoreAgent 類和所需的工具類 LookupTool 和 SearchTool。
然后,我們創建了這些工具的實例,并將它們作為參數傳遞給 ReActDocstoreAgent 的構造函數,從而初始化了 ReAct agent。回復中告訴我們要引入哪些類,以及ReAct Agent初始化需要依賴的類以及函數,把類和函數之間的依賴關系說清楚了。
總結
本文介紹了如何利用LangChain和GPT-3.5-Turbo來理解大型代碼庫。首先,我們下載了LangChain代碼庫并在VS Code中導入。然后,通過安裝必要的依賴包,如OpenAI、Tiktoken、ChromaDB和LangChain,為后續操作做準備。接著,我們加載LangChain的源代碼文件,包括使用LanguageParser進行解析。隨后,我們將代碼文件切割成小塊,以滿足大模型的輸入要求。這些切割后的代碼塊被嵌入到Chroma向量數據庫中,并創建了一個用于查詢的Retriever,它使用Maximal Marginal Relevance進行相關性查詢,并限制返回的文檔數量。最后,我們使用GPT-3.5-Turbo來進行代碼庫的查詢,實現了代碼的問答和解釋,使代碼庫的理解變得更加容易。
作者介紹
崔皓,51CTO社區編輯,資深架構師,擁有18年的軟件開發和架構經驗,10年分布式架構經驗。




























