













MySQL 用 limit 為什么會(huì)影響性能?有什么優(yōu)化方案?
Limit 是一種常用的分頁(yè)查詢語(yǔ)句,它可以指定返回記錄行的偏移量和最大數(shù)目。例如,下面的語(yǔ)句表示從 test 表中查詢 val 等于4的記錄,并返回第300001到第300005條記錄:
select * from test where val=4 limit 300000,5;這樣的語(yǔ)句看起來(lái)很簡(jiǎn)單,但是在實(shí)際使用中,可能會(huì)出現(xiàn)性能問(wèn)題。為什么呢?我們需要從 Mysql 的索引結(jié)構(gòu)和查詢過(guò)程來(lái)分析。
Mysql 的索引結(jié)構(gòu)
Mysql 支持多種類型的索引,其中最常用的是 B+ 樹索引。B+ 樹索引是一種平衡多路查找樹,它有以下特點(diǎn):
- 樹中的每個(gè)節(jié)點(diǎn)最多包含 m 個(gè)子節(jié)點(diǎn),m 被稱為 B+ 樹的階。
- 樹中的每個(gè)節(jié)點(diǎn)最少包含 m/2(向上取整)個(gè)子節(jié)點(diǎn),除了根節(jié)點(diǎn)和葉子節(jié)點(diǎn)。
- 樹中的所有葉子節(jié)點(diǎn)都位于同一層,并且通過(guò)指針相連。
- 樹中的所有非葉子節(jié)點(diǎn)只存儲(chǔ)鍵值(索引列)和指向子節(jié)點(diǎn)的指針。
- 樹中的所有葉子節(jié)點(diǎn)存儲(chǔ)鍵值(索引列)和指向數(shù)據(jù)記錄(聚簇索引)或者數(shù)據(jù)記錄地址(非聚簇索引)的指針。
下圖是一個(gè) B+ 樹索引的示例:
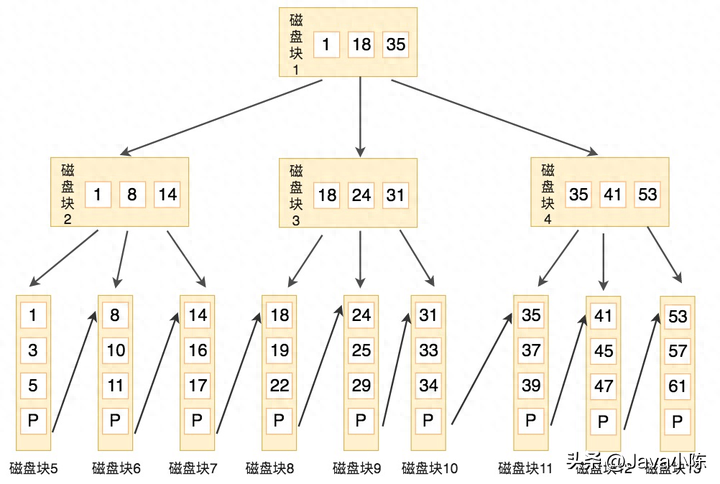
在 Mysql 中,有兩種常見的 B+ 樹索引:聚簇索引和非聚簇索引。
聚簇索引是一種特殊的 B+ 樹索引,它將數(shù)據(jù)記錄和索引放在一起存儲(chǔ),也就是說(shuō),葉子節(jié)點(diǎn)就是數(shù)據(jù)記錄。在 Mysql 中,每張表只能有一個(gè)聚簇索引,通常是主鍵或者唯一非空鍵。如果沒有定義這樣的鍵,Mysql 會(huì)自動(dòng)生成一個(gè)隱藏的聚簇索引。
非聚簇索引是一種普通的 B+ 樹索引,它將數(shù)據(jù)記錄和索引分開存儲(chǔ),也就是說(shuō),葉子節(jié)點(diǎn)只存儲(chǔ)鍵值和指向數(shù)據(jù)記錄地址的指針。在 Mysql 中,每張表可以有多個(gè)非聚簇索引,通常是普通鍵或者唯一鍵。
下圖是一個(gè)聚簇索引和非聚簇索引的對(duì)比:
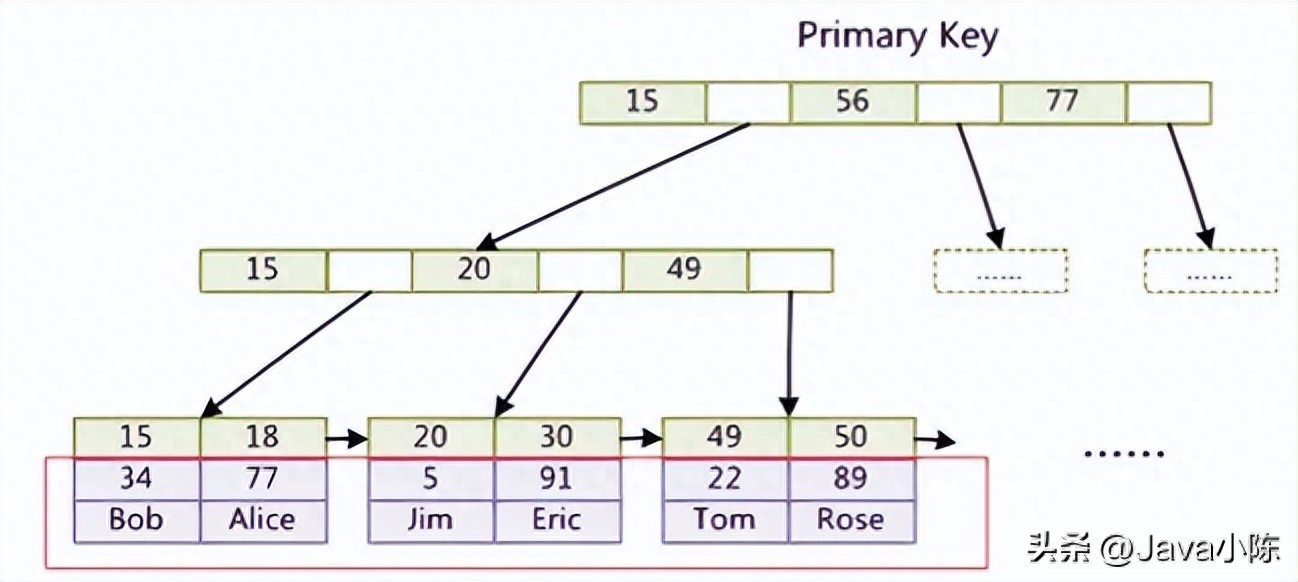 聚簇索引
聚簇索引
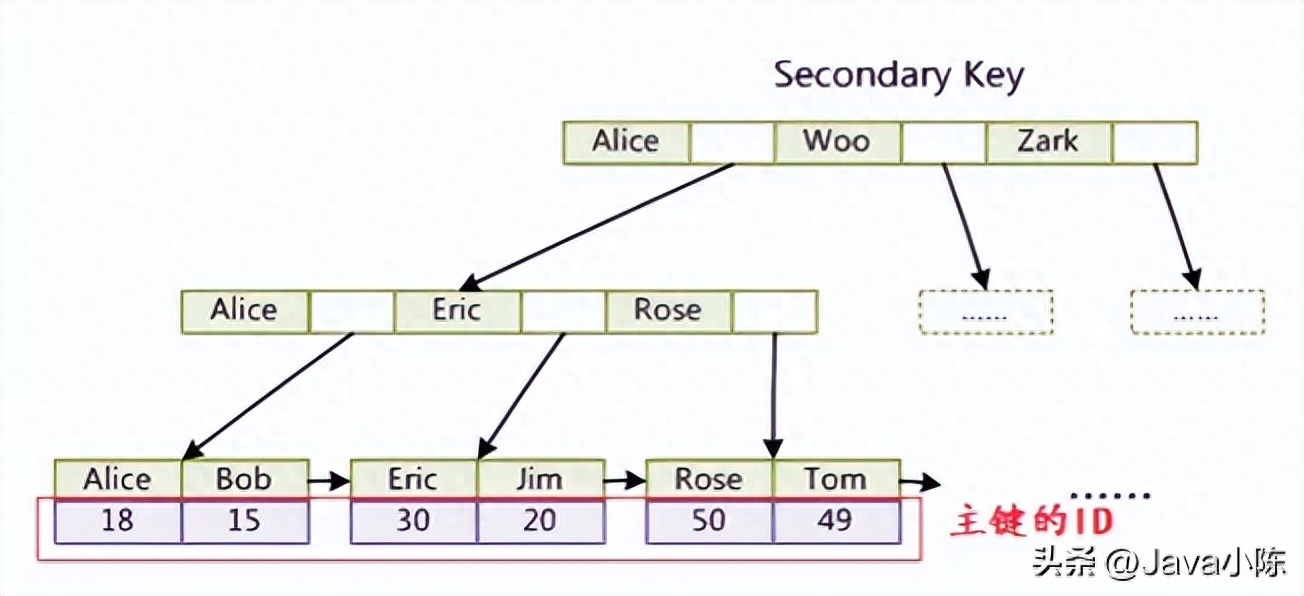 非聚簇索引
非聚簇索引
Mysql 的查詢過(guò)程
當(dāng)我們執(zhí)行一個(gè) SQL 查詢語(yǔ)句時(shí),Mysql 會(huì)根據(jù)優(yōu)化器的選擇,使用不同的執(zhí)行計(jì)劃來(lái)執(zhí)行。其中,最常見的執(zhí)行計(jì)劃有以下幾種:
- 全表掃描:顧名思義,就是掃描整張表的所有數(shù)據(jù)記錄,逐條檢查是否滿足條件。這種執(zhí)行計(jì)劃通常在沒有合適的索引或者條件過(guò)于復(fù)雜時(shí)使用。
- 索引掃描:也稱為范圍掃描,就是根據(jù)條件在索引上進(jìn)行查找,并返回滿足條件的記錄。這種執(zhí)行計(jì)劃通常在有合適的索引且條件較為簡(jiǎn)單時(shí)使用。
- 索引覆蓋掃描:也稱為索引只掃描,就是根據(jù)條件在索引上進(jìn)行查找,并返回滿足條件的記錄,但是不需要再訪問(wèn)數(shù)據(jù)記錄,因?yàn)椴樵兯璧乃凶侄味荚谒饕小_@種執(zhí)行計(jì)劃通常在有合適的索引且查詢字段較少時(shí)使用。
- 回表查詢:也稱為索引查找,就是根據(jù)條件在索引上進(jìn)行查找,并返回滿足條件的記錄,然后再根據(jù)索引指針去訪問(wèn)數(shù)據(jù)記錄,獲取查詢所需的其他字段。這種執(zhí)行計(jì)劃通常在有合適的索引但查詢字段較多時(shí)使用。
下圖是一個(gè)回表查詢的示例:
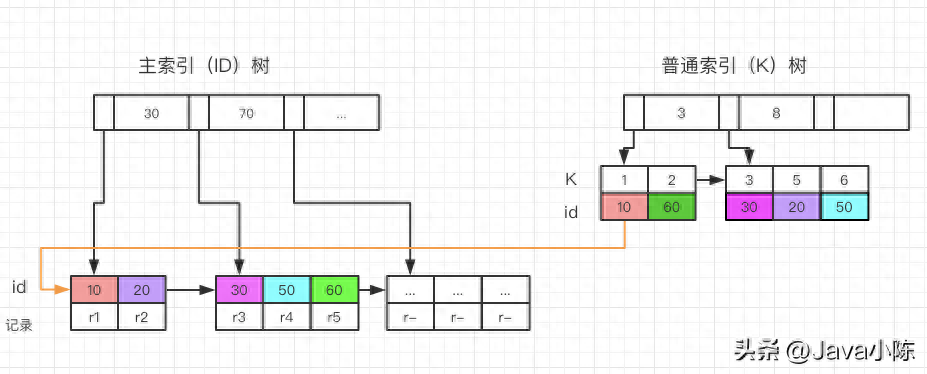
Mysql 的 Limit 性能問(wèn)題
回到我們最開始的問(wèn)題,Mysql 的 Limit 會(huì)影響性能嗎?為什么?
答案是:會(huì)影響性能,因?yàn)?Limit 會(huì)導(dǎo)致 Mysql 掃描過(guò)多的數(shù)據(jù)記錄或者索引記錄,而且大部分掃描到的記錄都是無(wú)用的。
我們以一個(gè)非聚簇索引為例,來(lái)分析一下 Limit 的影響。假設(shè)我們有一張表 test ,它有兩個(gè)字段 id 和 val ,其中 id 是主鍵,val 是非唯一非聚簇索引。表中有 500 萬(wàn)條數(shù)據(jù),val 的值從 1 到 10 隨機(jī)分布。我們執(zhí)行以下語(yǔ)句:
select * from test where val=4 limit 300000,5;這條語(yǔ)句的意思是查詢 val 等于 4 的記錄,并返回第 300001 到第 300005 條記錄。Mysql 會(huì)怎么執(zhí)行呢?
首先,Mysql 會(huì)選擇 val 索引作為執(zhí)行計(jì)劃,因?yàn)樗梢钥s小查詢范圍。然后,Mysql 會(huì)從 val 索引的根節(jié)點(diǎn)開始查找,沿著 B+ 樹向下搜索,直到找到第一個(gè) val 等于 4 的葉子節(jié)點(diǎn)。接著,Mysql 會(huì)沿著葉子節(jié)點(diǎn)的指針向右移動(dòng),掃描所有 val 等于 4 的葉子節(jié)點(diǎn),并記錄它們對(duì)應(yīng)的 id 值和數(shù)據(jù)記錄地址。
由于我們要返回第 300001 到第 300005 條記錄,所以 Mysql 必須掃描至少 300005 個(gè)葉子節(jié)點(diǎn),才能確定哪些是我們需要的。這就導(dǎo)致了大量的隨機(jī) I/O 操作,在磁盤上讀取索引頁(yè)。
接下來(lái),Mysql 還要根據(jù)葉子節(jié)點(diǎn)指向的數(shù)據(jù)記錄地址,去訪問(wèn)數(shù)據(jù)頁(yè),獲取查詢所需的所有字段。由于我們要返回所有字段(select *),所以 Mysql 必須訪問(wèn)至少 300005 次數(shù)據(jù)頁(yè),才能獲取到完整的數(shù)據(jù)記錄。這又導(dǎo)致了大量的隨機(jī) I/O 操作,在磁盤上讀取數(shù)據(jù)頁(yè)。
最后,Mysql 還要對(duì)掃描到的數(shù)據(jù)記錄進(jìn)行排序和過(guò)濾,拋棄前面 300000 條無(wú)用的記錄,只保留后面 5 條有用的記錄。這就導(dǎo)致了大量的 CPU 和內(nèi)存消耗,在內(nèi)存中進(jìn)行排序和過(guò)濾。
綜上所述,Mysql 在執(zhí)行這條語(yǔ)句時(shí),需要做以下操作:
- 掃描至少 300005 個(gè)索引頁(yè)
- 訪問(wèn)至少 300005 次數(shù)據(jù)頁(yè)
- 排序和過(guò)濾至少 300005 條數(shù)據(jù)記錄
這些操作都是非常耗時(shí)和耗資源和時(shí)間的浪費(fèi)。為了返回 5 條有用的記錄,Mysql 不得不掃描和訪問(wèn)大量的無(wú)用的記錄。這就是 Limit 會(huì)影響性能的原因。
那么,有沒有辦法優(yōu)化這個(gè)問(wèn)題呢?
答案是:有,但是需要根據(jù)具體的情況來(lái)選擇合適的方法。下面,我們介紹幾種常見的優(yōu)化方法:
- 使用索引覆蓋掃描。如果我們只需要查詢部分字段,而不是所有字段,我們可以嘗試使用索引覆蓋掃描,也就是讓查詢所需的所有字段都在索引中,這樣就不需要再訪問(wèn)數(shù)據(jù)頁(yè),減少了隨機(jī) I/O 操作。例如,如果我們只需要查詢 id 和 val 字段,我們可以執(zhí)行以下語(yǔ)句:
select id,val from test where val=4 limit 300000,5;這樣,Mysql 只需要掃描索引頁(yè),而不需要訪問(wèn)數(shù)據(jù)頁(yè),提高了查詢效率。
- 使用子查詢。如果我們不能使用索引覆蓋掃描,或者查詢字段較多,我們可以嘗試使用子查詢,也就是先用一個(gè)子查詢找出我們需要的記錄的 id 值,然后再用一個(gè)主查詢根據(jù) id 值獲取其他字段。例如,我們可以執(zhí)行以下語(yǔ)句:
select * from test where id in (select id from test where val=4 limit 300000,5);這樣,Mysql 先執(zhí)行子查詢,在 val 索引上進(jìn)行范圍掃描,并返回 5 個(gè) id 值。然后,Mysql 再執(zhí)行主查詢,在 id 索引上進(jìn)行點(diǎn)查找,并返回所有字段。這樣,Mysql 只需要掃描 5 個(gè)數(shù)據(jù)頁(yè),而不是 300005 個(gè)數(shù)據(jù)頁(yè),提高了查詢效率。
- 使用分區(qū)表。如果我們的表非常大,或者數(shù)據(jù)分布不均勻,我們可以嘗試使用分區(qū)表,也就是將一張大表分成多個(gè)小表,并按照某個(gè)字段或者范圍進(jìn)行劃分。這樣,Mysql 可以根據(jù)條件只訪問(wèn)部分分區(qū)表,而不是整張表,減少了掃描和訪問(wèn)的數(shù)據(jù)量。例如,如果我們按照 val 字段將 test 表分成 10 個(gè)分區(qū)表(test_1 到 test_10),每個(gè)分區(qū)表只存儲(chǔ) val 等于某個(gè)值的記錄,我們可以執(zhí)行以下語(yǔ)句:
select * from test_4 limit 300000,5;這樣,Mysql 只需要訪問(wèn) test_4 這個(gè)分區(qū)表,而不需要訪問(wèn)其他分區(qū)表,提高了查詢效率。




















