













為什么 NUMA 會影響程序的延遲
為什么這么設計(Why’s THE Design)是一系列關于計算機領域中程序設計決策的文章,我們在這個系列的每一篇文章中都會提出一個具體的問題并從不同的角度討論這種設計的優(yōu)缺點、對具體實現(xiàn)造成的影響。如果你有想要了解的問題,可以在文章下面留言。
非一致性內(nèi)存訪問(Non-Uniform Memory Access、NUMA)是一種計算機內(nèi)存的設計方式[^1],與 NUMA 相對的還有一致性內(nèi)存訪問(Uniform Memory Access、UMA),也被稱作對稱多處理器架構(Symmetric Multi-Processor、SMP),早期的計算機都會使用 SMP,然而現(xiàn)代的多數(shù)計算機都會采用 NUMA 架構管理 CPU 和內(nèi)存資源。
uma-and-numa
圖 1 - UMA 和 NUMA
作為應用程序的開發(fā)者,因為操作系統(tǒng)為我們屏蔽了很多硬件層面的實現(xiàn)細節(jié),所以不太需要直接接觸硬件,不過因為 NUMA 會影響應用程序,所以想要寫出高性能、低延遲的服務,NUMA 是我們必須要了解并熟悉的,本文將從以下兩個方面介紹它的影響:
- NUMA 引入了本地內(nèi)存和遠程內(nèi)存,CPU 訪問本地內(nèi)存的延遲會小于訪問遠程內(nèi)存;
- NUMA 的內(nèi)存分配與內(nèi)存回收策略結合時會可能會導致 Linux 的頻繁交換分區(qū)(Swap)進而影響系統(tǒng)的穩(wěn)定性;
本地內(nèi)存
如果主機使用 NUMA 這種架構設計,那么 CPU 訪問本地內(nèi)存的延遲會小于訪問遠程內(nèi)存,這種現(xiàn)象并不是 CPU 設計者刻意制造的,而是物理層面的限制。不過 NUMA 這種設計并不是與計算機一同誕生的,我們在繼續(xù)分析 NUMA 對程序的影響之前先來分析一下 CPU 架構的演進過程。
在計算機誕生的最初幾十年,處理器基本都是單核的,根據(jù)摩爾定律,隨著技術的進步,處理器的性能每隔兩年就會翻一倍[^2],這一定律在上個世紀基本都是生效的,然而在過去十幾年,單個處理器中晶體管數(shù)目的增加速度逐漸放緩,很多廠商開始推出了雙核以及多核的計算機。
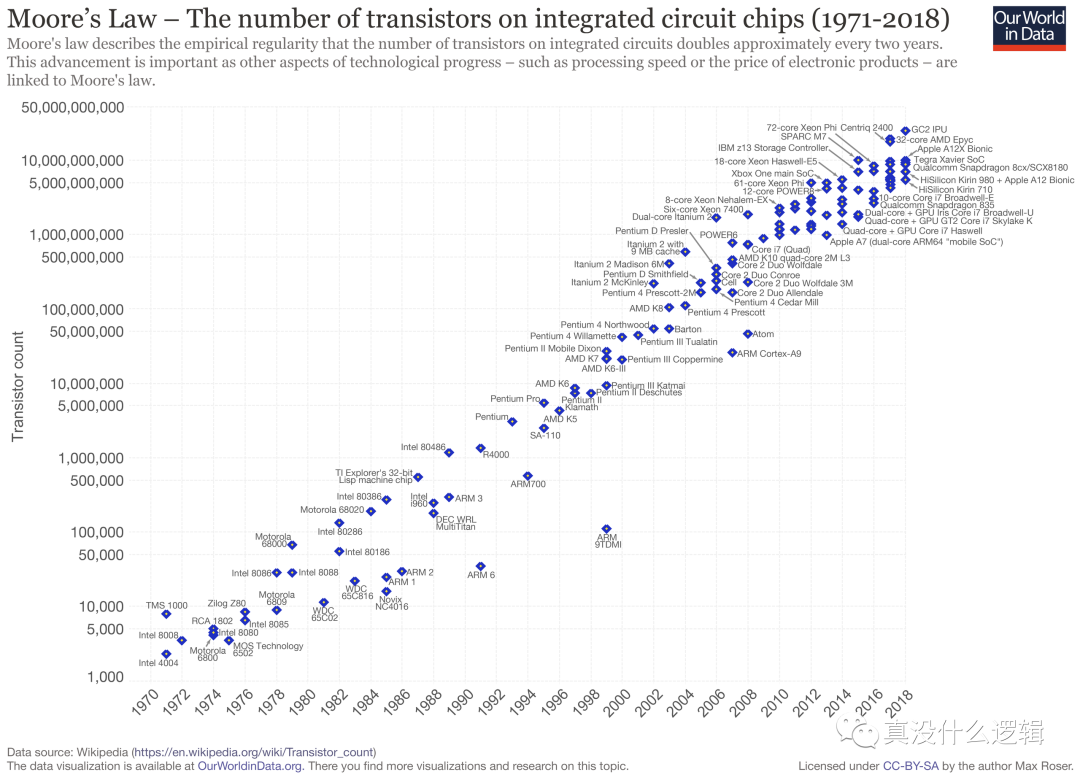
moores-law
圖 2 - 摩爾定律
單核或者多核計算機上的 CPU 最早會通過前端總線(Front-side bus)、北橋(Northbridge)和內(nèi)存總線(Memory bus)訪問內(nèi)存槽中的內(nèi)存,所有的 CPU 會通過相同的總線訪問相同的內(nèi)存以及 I/O 設備,計算機中的所有資源都是共享的,這種架構被稱作對稱多處理器架構(Symmetric Multi-Processor、SMP),也被稱為一致存儲器訪問結構(Uniform Memory Access、UMA)。
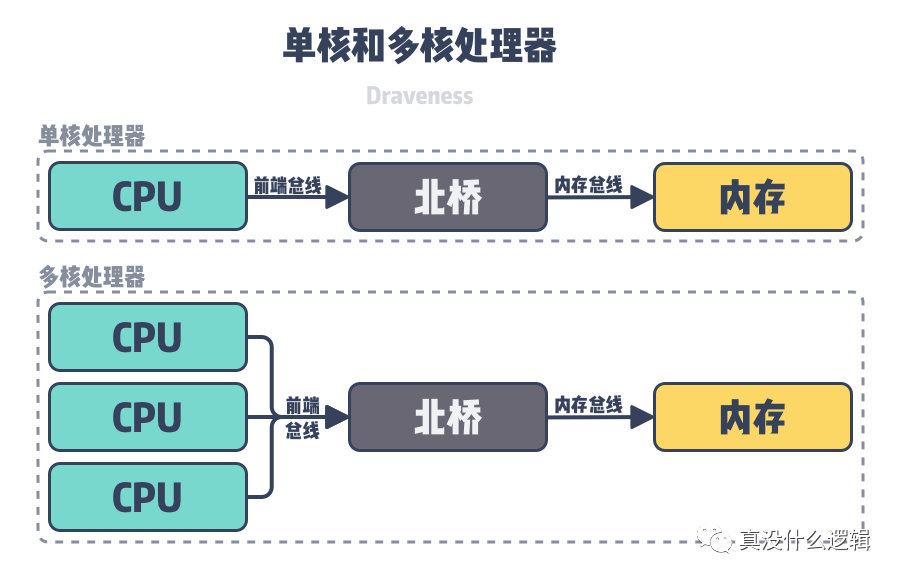
single-and-multi-core
圖 3 - 單核和多核處理器
然而隨著計算機中 CPU 數(shù)量的增加,多個 CPU 都需要通過總線和北橋訪問內(nèi)存,當同一個主機中包含幾十個 CPU 時,總線和北橋兩個模塊成為了系統(tǒng)的瓶頸,為了解決這一問題,CPU 架構的設計者使用如下所示的多個 CPU 模塊解決了這個問題:
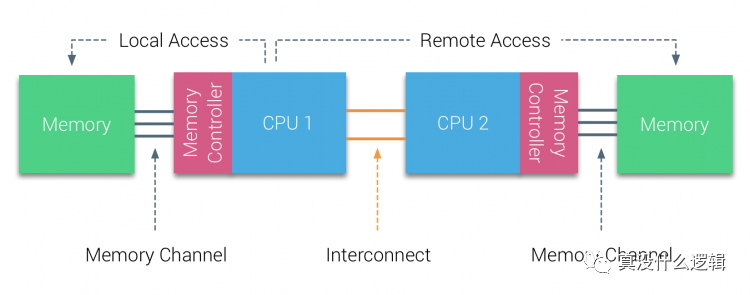
numa-local-remote-access
圖 4 - 雙節(jié)點 NUMA 架構
如上圖所示,該主機中包含 2 個 NUMA 節(jié)點,每個 NUMA 節(jié)點都包含物理 CPU 和內(nèi)存,從圖中我們可以看出 CPU 1 訪問本地內(nèi)存和遠程內(nèi)存會經(jīng)過不同的通道,這是訪問內(nèi)存時間不同的根本原因。
操作系統(tǒng)作為管理計算機硬件、軟件資源并為應用程序提供通用服務的軟件,它本身就會與底層的硬件打交道,Linux 操作系統(tǒng)就會為我們提供硬件相關的 NUMA 信息,你可以直接通過 numactl 命令查看機器上的 NUMA 節(jié)點[^3]:
- $ numactl -H
- available: 2 nodes (0-1)
- node 0 cpus: 0 1 2 3 4 5 6 7 8 9 10 11 24 25 26 27 28 29 30 31 32 33 34 35
- node 0 size: 63539 MB
- node 0 free: 18566 MB
- node 1 cpus: 12 13 14 15 16 17 18 19 20 21 22 23 36 37 38 39 40 41 42 43 44 45 46 47
- node 1 size: 64485 MB
- node 1 free: 20716 MB
- node distances:
- node 0 1
- 0: 10 21
- 1: 21 10
從上述輸出結果我們可以看出,該機器上包含兩個 NUMA 節(jié)點,每個節(jié)點上都包含 24 個 CPU 以及 64GB 的內(nèi)存,最后的節(jié)點距離(node distances)告訴我們兩個 NUMA 節(jié)點訪問內(nèi)存的開銷,其中 NUMA 節(jié)點 0 和 NUMA 節(jié)點 1 互相訪問對方內(nèi)存的延遲是各自節(jié)點訪問本地內(nèi)存的 2.1 倍(21 / 10 = 2.1),所以如果 NUMA 節(jié)點 0 上的進程如果在節(jié)點 1 上分配內(nèi)存,會增加進程的延遲。
正是因為 NUMA 節(jié)點訪問不同內(nèi)存的開銷不同,所以操作系統(tǒng)會為應用程序提供接口控制 CPU 和內(nèi)存的分配策略,在 Linux 系統(tǒng)中,我們可以使用 numactl 命令控制進程使用的 CPU 和內(nèi)存。
numactl 提供了 cpunodebind 和 physcpubind 兩種策略為進程分配 CPU,這兩種策略分別提供了不同粒度的綁定方法:
- cpunodebind — 將進程綁定到某幾個 NUMA 節(jié)點上;
- physcpubind — 將進程綁定到某幾個物理 CPU 上;
除了這兩種 CPU 分配策略之外,numactl 還提供四種不同的內(nèi)存分配策略,分別是:localalloc、preferred、membind 和 interleave:
- localalloc — 總是在當前節(jié)點上分配內(nèi)存;
- preferred — 傾向于在特定節(jié)點上分配內(nèi)存,當指定節(jié)點的內(nèi)存不足時,操作系統(tǒng)會在其他節(jié)點上分配;
- membind — 只能在傳入的幾個節(jié)點上分配內(nèi)存,當指定節(jié)點的內(nèi)存不足時,內(nèi)存的分配就會失敗;
- interleave — 內(nèi)存會在傳入的節(jié)點上依次分配(Round Robin),當指定節(jié)點的內(nèi)存不足時,操作系統(tǒng)會在其他節(jié)點上分配;
上述的兩種 CPU 分配策略和四種內(nèi)存分配策略是我們與 NUMA 打交道時經(jīng)常需要接觸的,當進程的性能受到 NUMA 的影響時,我們可能需要通過 numactl 命令調整 CPU 或者內(nèi)存的分配策略。
交換分區(qū)
NUMA 架構雖然能夠解決總線上的性能瓶頸并可以讓我們在同一個主機上運行更多的 CPU,但是如果不了解 NUMA 的工作原理或者使用錯誤的策略會帶來一些問題,Jeremy Cole 的文章 The MySQL “swap insanity” problem and the effects of the NUMA architecture 就曾經(jīng)分析過 NUMA 架構下 MySQL 可能出現(xiàn)的問題 — 頻繁發(fā)生的交換分區(qū)影響服務延遲[^4],我們在這里簡單介紹一下該問題背后的原因:
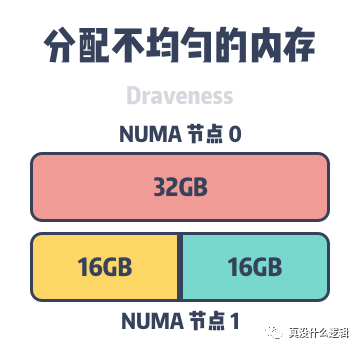
uneven-memory-node
圖 5 - 分配不均勻的內(nèi)存
因為 MySQL 等數(shù)據(jù)庫的運行會占用大量的內(nèi)存,在默認情況進程會先在所在的 NUMA 節(jié)點上分配內(nèi)存,當本地內(nèi)存不足時,才會在遠程分配內(nèi)存。如上圖所示,主機上包含兩個 NUMA 節(jié)點,其中每個節(jié)點都有 32GB 的內(nèi)存,但是當 MySQL InnoDB 的緩存池占用 48GB 的內(nèi)存時,它會在 NUMA 節(jié)點 0 和 NUMA 節(jié)點 1 分別分配 32GB 和 16GB 的內(nèi)存。
雖然 48GB 的內(nèi)存遠遠沒有到達主機 64GB 的內(nèi)存上限,但是當某些數(shù)據(jù)必須要在 NUMA 節(jié)點 0 的內(nèi)存上分配時,就會導致 NUMA 節(jié)點 0 中的內(nèi)存被交換到了文件系統(tǒng)上為新的內(nèi)存請求讓出位置[^5],InnoDB 緩存池中內(nèi)存的頻繁換入和換出會使 MySQL 的查詢隨機地出現(xiàn)延遲,而一旦發(fā)生了交換分區(qū),可能就是性能螺旋下降的開始。
Linux 中的 zone_reclaim_mode 可以允許工程師設置在 NUMA 節(jié)點內(nèi)存不足時內(nèi)存的回收策略,在默認情況下該模式都會處于關閉狀態(tài)[^6],如果我們在 NUMA 系統(tǒng)中通過該配置啟用了激進的內(nèi)存回收策略,可能會影響程序的性能[^7],MySQL 也會受到內(nèi)存回收策略的影響,但是僅僅關閉該策略并不會解決它遇到的頻繁觸發(fā)交換分區(qū)的問題[^8]。
- $ cat /proc/sys/vm/zone_reclaim_mode
- 0
想要解決該問題,我們需要使用上一節(jié)提到的 numactl 將內(nèi)存的分配策略改為 interleave,使用該內(nèi)存分配策略會使得 MySQL 的內(nèi)存均勻地分配到不同的 NUMA 節(jié)點上,能夠降低頁面頻繁換入換出的可能性。

even-memory-node
圖 6 - 分配均勻的內(nèi)存
該問題并不是 MySQL 獨有的,很多占用大量內(nèi)存的數(shù)據(jù)庫都會遇到上述問題,雖然使用 interleave 能夠暫時解決這些問題,但是 MySQL 進程訪問遠程內(nèi)存時,與本地內(nèi)存相比仍然會遇到性能損失,想要一勞永逸地避免服務在 NUMA 上運行的額外開銷,最好的辦法還是開發(fā)能夠感知底層 NUMA 架構的應用程序。以 MySQL 為例,Jeremy Cole 在文章中提出了如下的修改,可以更好地利用 NUMA 的本地內(nèi)存[^9]:
- 將緩存池中的數(shù)據(jù)按照塊或者索引智能地分配到不同節(jié)點上;
- 為正常的查詢線程保留默認的分配策略,內(nèi)存還是會優(yōu)先分配本地節(jié)點上;
- 將簡單的查詢線程重新調度到能夠訪問本地內(nèi)存的節(jié)點上;
除了 MySQL 可以利用 NUMA 來提高性能之外,一些框架或者編程語言也可以通過感知底層的 NUMA 信息來提升服務的響應速度,例如 Go 語言社區(qū)中就有關于 NUMA 感知調度的設計文檔[^10],雖然由于該特性的實現(xiàn)過于復雜,目前沒有投入到開發(fā)中,但是這仍然是調度器未來的發(fā)展方向。
總結
很多軟件工程師可能認為操作系統(tǒng)以及底層的硬件與我們的距離非常遙遠,我們在開發(fā)軟件時不需要考慮這么多細節(jié),對于絕大多數(shù)的應用程序來說,這一點都是成立的,操作系統(tǒng)能夠為我們屏蔽很多底層的實現(xiàn)細節(jié),讓我們能夠將更多的精力投入到業(yè)務邏輯的實現(xiàn)上。
不過正如我們在文章中提到的,哪怕操作系統(tǒng)做出再多的隔離和抽象,物理世界存在的限制還是會在暗處影響我們的應用程序,想要開發(fā)高性能的軟件必須要關注下兩層甚至更底層的實現(xiàn)細節(jié),NUMA 這種硬件層面的設計就會深刻的影響我們的軟件,這里再來回顧一下文章開頭提到的兩點影響:
- NUMA 引入了本地內(nèi)存和遠程內(nèi)存,CPU 訪問本地內(nèi)存的延遲會小于訪問遠程內(nèi)存;
- NUMA 的內(nèi)存分配與內(nèi)存回收策略結合時會可能會導致 Linux 的頻繁交換分區(qū)(Swap)進而影響系統(tǒng)的穩(wěn)定性;
我們當然更希望主機上的所有 CPU 都能夠快速地訪問全部的內(nèi)存,但是硬件的限制導致我們無法實現(xiàn)這么理想的情況,而 NUMA 可能是 CPU 架構發(fā)展的必然方向,通過將 CPU 和內(nèi)存資源分組降低總線的壓力,讓單個主機容納很多的 CPU。到最后,我們還是來看一些比較開放的相關問題,有興趣的讀者可以仔細思考一下下面的問題:
NUMA 架構最多可以支持多少 CPU?該架構又存在哪些瓶頸?
MPP(Massive Parallel Processing)是如何擴展系統(tǒng)的?它解決了哪些問題?
- Optimizing Linux Memory Management for Low-latency / High-throughput Databases https://engineering.linkedin.com/performance/optimizing-linux-memory-management-low-latency-high-throughput-databases
- NUMA (Non-Uniform Memory Access): An Overview https://queue.acm.org/detail.cfm?id=2513149
- PostgreSQL, NUMA and zone reclaim mode on linux http://frosty-postgres.blogspot.com/2012/08/postgresql-numa-and-zone-reclaim-mode.html
本文轉載自微信公眾號「真沒什么邏輯」,可以通過以下二維碼關注。轉載本文請聯(lián)系真沒什么邏輯公眾號。


















