













十分鐘掌握Doris,超越Hive、Elasticsearch和PostgreSQL

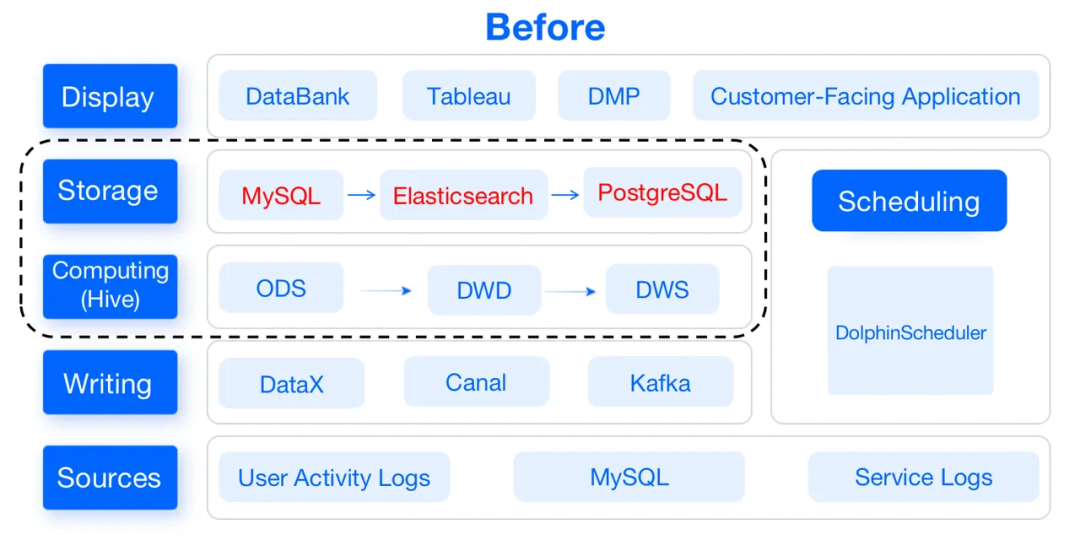
以前,數(shù)據(jù)倉庫通常由Apache Hive、MySQL、Elasticsearch和PostgreSQL組成。它們支持?jǐn)?shù)據(jù)倉庫的數(shù)據(jù)計算和數(shù)據(jù)存儲層:
- 數(shù)據(jù)計算:Apache Hive作為計算引擎。
- 數(shù)據(jù)存儲:MySQL為DataBank、Tableau和我們面向客戶的應(yīng)用程序提供數(shù)據(jù)。Elasticsearch和PostgreSQL用于我們的DMP用戶分割系統(tǒng):前者存儲用戶分析數(shù)據(jù),后者存儲用戶組數(shù)據(jù)包。
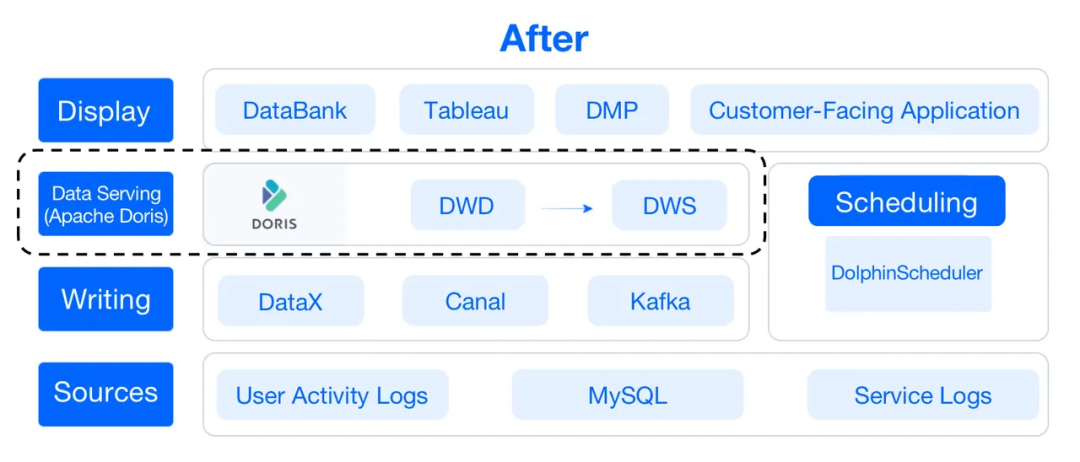
不過,這樣會導(dǎo)致數(shù)據(jù)管道又長又復(fù)雜,需要高維護(hù)成本,并且有損于開發(fā)效率。此外,它們無法進(jìn)行特定查詢。因此,作為數(shù)據(jù)倉庫的升級,可以用Apache Doris替換了其中大部分組件,這是一種基于MPP架構(gòu)的開源分析型數(shù)據(jù)庫。
1. 數(shù)據(jù)流
這是數(shù)據(jù)倉庫的側(cè)面視圖,可以從中看到數(shù)據(jù)如何流動。
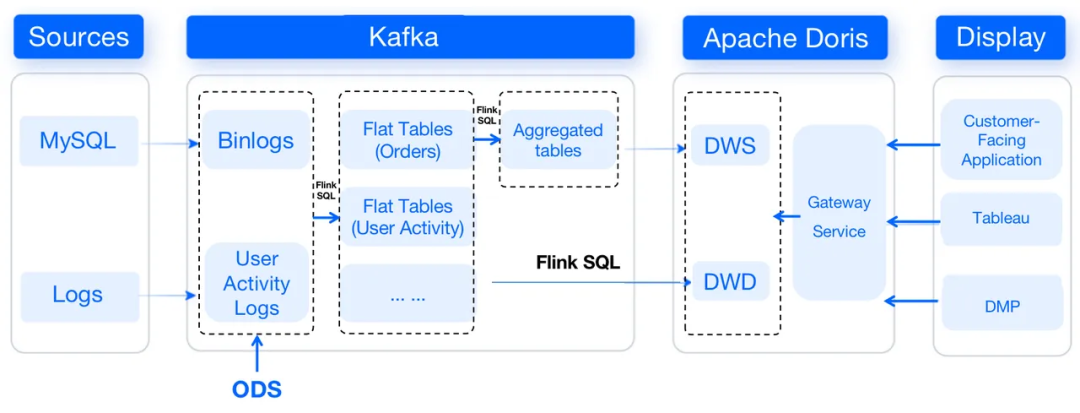
首先,MySQL的binlog將通過Canal被攝入到Kafka中,而用戶活動日志將通過Apache Flume傳輸?shù)終afka中。在Kafka中,數(shù)據(jù)將被清理并組織成平面表,然后將轉(zhuǎn)換為聚合表。然后,數(shù)據(jù)將從Kafka傳遞到Apache Doris,它充當(dāng)存儲和計算引擎。
我們在Apache Doris中采用不同的數(shù)據(jù)模型來處理不同的場景:來自MySQL的數(shù)據(jù)將按照Unique模型進(jìn)行排列,日志數(shù)據(jù)將放在Duplicate模型中,而DWS層中的數(shù)據(jù)將合并在Aggregate模型中。
這就是Apache Doris如何取代我們數(shù)據(jù)倉庫中Hive、Elasticsearch和PostgreSQL的角色。這種轉(zhuǎn)變在開發(fā)和維護(hù)方面節(jié)省了我們大量的工作量。它還使特定查詢成為可能,并使我們的用戶分割更加高效。
2. 臨時查詢
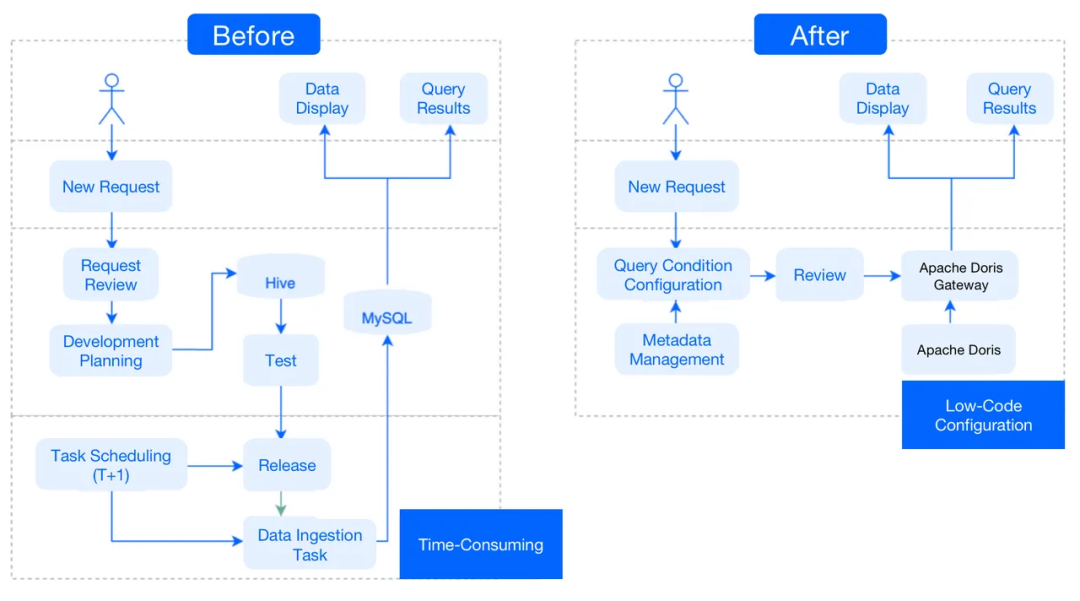
之前:每次提出新請求時,我們都會在Hive中開發(fā)和測試數(shù)據(jù)模型,并在MySQL中編寫調(diào)度任務(wù),以便我們面向客戶的應(yīng)用程序平臺可以從MySQL讀取結(jié)果。這是一個復(fù)雜的過程,需要大量時間和開發(fā)工作。
之后:由于Apache Doris擁有所有明細(xì)數(shù)據(jù),因此每當(dāng)它面臨新請求時,它只需提取元數(shù)據(jù)并配置查詢條件即可。然后它就可以進(jìn)行特定查詢了。簡而言之,它只需要低代碼配置即可響應(yīng)新請求。
3. 用戶分割
之前:基于元數(shù)據(jù)創(chuàng)建用戶分割任務(wù)后,相關(guān)的用戶ID將被寫入PostgreSQL配置文件列表和MySQL任務(wù)列表中。同時,Elasticsearch將根據(jù)任務(wù)條件執(zhí)行查詢;在產(chǎn)生結(jié)果后,它將在任務(wù)列表中更新狀態(tài),并將用戶組位圖包寫入PostgreSQL。(PostgreSQL插件能夠計算位圖的交集、并集和差集。)然后,PostgreSQL將為下游操作平臺提供用戶組數(shù)據(jù)包。
Elasticsearch和PostgreSQL中的表格無法重復(fù)使用,這使得這種架構(gòu)成本效益低。此外,我們必須預(yù)定義用戶標(biāo)簽,才能執(zhí)行新類型的查詢。這減慢了速度。
之后:用戶ID僅會被寫入MySQL任務(wù)列表中。對于第一次分割,Apache Doris將根據(jù)任務(wù)條件執(zhí)行特定查詢。在隨后的分割任務(wù)中,Apache Doris將執(zhí)行微批量滾動,并計算與先前生成的用戶組數(shù)據(jù)包相比的差異集,并通知下游平臺進(jìn)行任何更新。(這是由Apache Doris中的位圖函數(shù)實(shí)現(xiàn)的。)
在這個以Doris為中心的用戶分割過程中,我們不必預(yù)定義新標(biāo)簽。相反,標(biāo)簽可以根據(jù)任務(wù)條件自動生成。處理管道具有靈活性,可以使我們基于用戶組進(jìn)行A/B測試更加容易。此外,由于明細(xì)數(shù)據(jù)和用戶組數(shù)據(jù)包都在Apache Doris中,因此我們不必關(guān)注多個組件之間的讀寫復(fù)雜性。

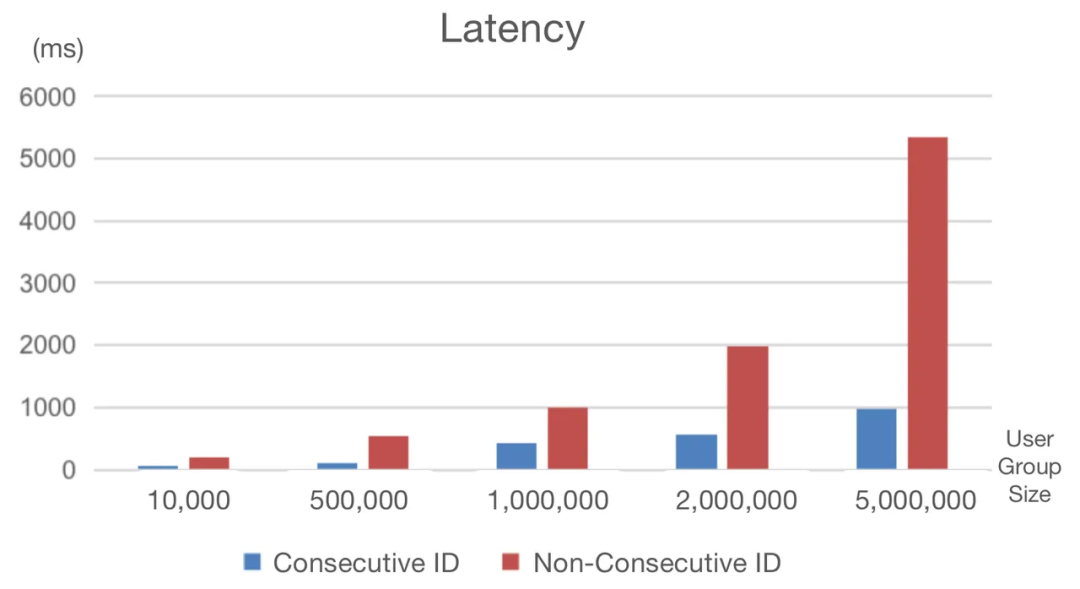
4. 提高用戶分組速度的技巧,可提高70%
由于風(fēng)險規(guī)避原因,隨機(jī)生成user_id是許多公司的選擇,但這會在用戶組數(shù)據(jù)包中產(chǎn)生稀疏和非連續(xù)的用戶ID。在用戶分組中使用這些ID,我們必須忍受等待位圖生成的漫長時間。
為了解決這個問題,我們?yōu)檫@些用戶ID創(chuàng)建了連續(xù)和密集的映射。通過這種方式,我們將用戶分組延遲降低了70%。

5. 示例
步驟1:創(chuàng)建用戶ID映射表
我們采用唯一模型用于用戶ID映射表,其中用戶ID是唯一鍵。映射的連續(xù)ID通常從1開始嚴(yán)格遞增。

步驟2:創(chuàng)建用戶組表:
我們采用聚合模型用于用戶組表,其中用戶標(biāo)簽作為聚合鍵。

假設(shè)我們需要挑選出ID在0到2000000之間的用戶。
以下代碼段分別使用非連續(xù)(tyc_user_id)和連續(xù)(tyc_user_id_continuous)用戶ID進(jìn)行用戶分組。它們的響應(yīng)時間之間存在很大差距:
- 非連續(xù)用戶ID:1843ms
- 連續(xù)用戶ID:543ms

6. 總結(jié)
我們在Apache Doris中擁有2個容納數(shù)十TB數(shù)據(jù)的集群,每天幾乎有10億行新數(shù)據(jù)流入。隨著數(shù)據(jù)量的擴(kuò)大,我們曾經(jīng)目睹數(shù)據(jù)攝入速度急劇下降。但是,在使用Apache Doris升級數(shù)據(jù)倉庫后,我們將數(shù)據(jù)寫入效率提高了75%。此外,在結(jié)果集小于500萬的用戶分組中,它能夠在毫秒內(nèi)響應(yīng)。最重要的是,我們的數(shù)據(jù)倉庫對開發(fā)人員和維護(hù)人員更加簡單和友好。























