













實時占用網絡? OccupancyDETR:使占用網絡與目標檢測一樣直接!

論文鏈接:https://arxiv.org/pdf/2309.08504.pdf
代碼鏈接:https://github.com/jypjypjypjyp/OccupancyDETR
基于視覺的3D語義占用感知(也稱為3D語義場景完成)是自動駕駛等機器人應用的一種新的感知范式。與BEV感知相比,它擴展了垂直維度,顯著增強了機器人理解周圍環境的能力。然而,正是由于這個原因,當前3D語義占用感知方法的計算需求通常超過BEV感知方法和2D感知方法。我們提出了一種新的3D語義占用感知方法OccupancyDETR,該方法由類似DETR的目標檢測模塊和3D占用解碼器模塊組成。目標檢測的集成在結構上簡化了我們的方法——它不是預測每個體素的語義,而是識別場景中的目標及其各自的3D占用網格。這加快了我們的方法,減少了所需的資源,并利用了目標檢測算法,使其在小目標上具有顯著的性能。在SemanticKITTI數據集上證明了本文提出方法的有效性,展示了23%mIoU和每秒6幀的處理速度,從而為實時3D語義場景完成提供了一個有前景的解決方案!
當前的一些主流方案
3D語義感知是機器人的一項基本能力。目前流行的方法采用了涉及激光雷達和相機的多傳感器融合,然而,這種方法引起了諸如高成本和缺乏可移植性等問題。近年來,人們對基于純視覺的3D語義感知方案產生了越來越大的興趣,因為它們在不影響性能的情況下成本相對較低。最初,引入了BEV感知,顯著增強了自動駕駛場景中的感知能力。隨后,出現了3D語義占用感知,將BEV感知擴展了垂直維度,從而在各種場景中提供了更廣泛的適用性。為此,我們專注于基于視覺的三維語義占用感知,目標是為這項任務開發一種更直接、更有效的方法。
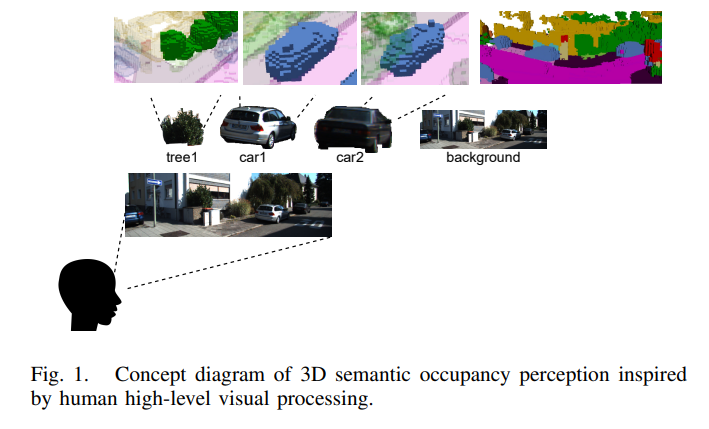
科學家們在對人類視覺感知的研究中注意到,在高級視覺處理中,傾向于優先考慮場景中的一些前景目標,同時參考未被注意到的背景信息。受此啟發,在3D語義占用感知中,我們模仿人類視覺感知的機制,引入了類似DETR的目標檢測模塊來指導3D語義占用網格的預測。我們使用檢測到的目標邊界框結果作為位置先驗,并使用目標的隱藏特征作為上下文信息,然后利用空間transformer解碼器來提取每個目標的3D占用網格。
這里提到的“目標”并不是精確地表示單個目標,而是表示具有相同語義的目標集群,例如一叢樹或一組建筑。通過這種方式,3D語義占用感知的任務被分解為識別場景中的各種目標,然后提取它們各自的3D占用網格。從早期的YOLO到最近的Deformable DETR等方法,目標檢測算法已經開發了多年,在復雜場景下取得了優異的性能。此外,它們的復雜度水平顯著低于3D語義占用感知。我們希望通過集成成熟的目標檢測算法來簡化3D語義占用感知方法,旨在使3D語義占用認知與目標檢測一樣簡單,并將這些任務統一在單個神經網絡中。最后,在SemanticKITTI數據集上驗證了提出的方法,證明了在較小目標上的卓越性能、更快的速度和更少的資源需求。
我們的主要貢獻如下:
1)提出了一種新的3D語義占用預測方法,該方法結合了目標檢測。這種方法簡單高效,特別擅長處理小目標,并在SemanticKITTI數據集上取得了優異的性能;
2)針對Detrlike算法的慢收斂問題,提出了一種早期匹配預訓練。這種預訓練增強了訓練的確定性并加速了融合;
3)設計了兩種類型的3D占用解碼器,一種使用帶高程的BEV查詢,另一種使用3D box查詢。通過實驗比較,檢驗了這兩種方法在不同類別物體上的性能;
我們提出的方法
模型整體結構如圖2所示,它由兩部分組成:目標檢測模塊和3D占用解碼器。對于輸入圖像,使用ResNet50主干來提取特征,然后將這些多尺度特征傳遞到可變形編碼器中進行進一步編碼。在第二步中,通過可變形的DETR解碼器對固定數量的查詢進行解碼,然后將其傳遞到三個Head——分類Head、2D box Head和3D box Head。來自分類頭和2D box Head的結果是目標檢測中的常規結果,根據分類頭的輸出來選擇高置信度的目標。在第三步驟中,這些高置信度目標的3D框用作3D占用解碼器的每個目標的位置先驗,從而提供位置嵌入。從可變形DETR解碼器獲得的特征用作上下文信息。隨后,3D占用解碼器基于可變形DETR編碼器編碼的多尺度特征來預測每個目標的3D占用網格。
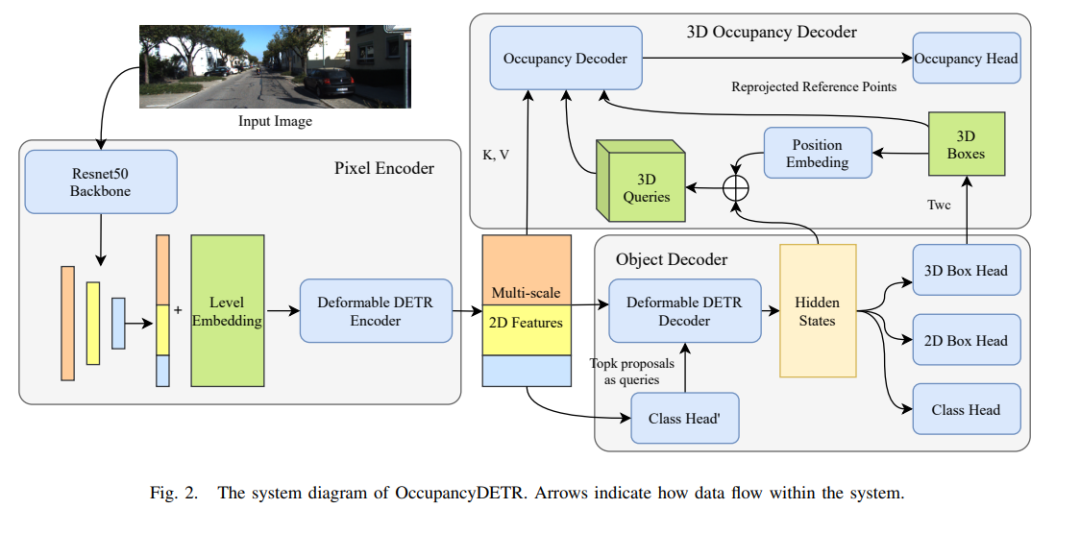
1)目標檢測模塊
我們將目標檢測引入到三維語義占用預測中,旨在簡化和輔助三維語義占用的預測。因此,識別出的“目標”與傳統目標檢測中的“目標“不同。在生成注釋數據時,首先根據距離從體素網格中對語義目標進行聚類,而不精確區分每個目標。然后將每個聚集的目標投影到2D圖像上,并基于這些投影點計算2D bounding box,而且在投影過程中會考慮遮擋。我們防止完全遮擋的不可觀察目標影響模型學習,因此將這些目標排除在外。然而,為了賦予模型場景補全功能,會保留部分遮擋的目標。
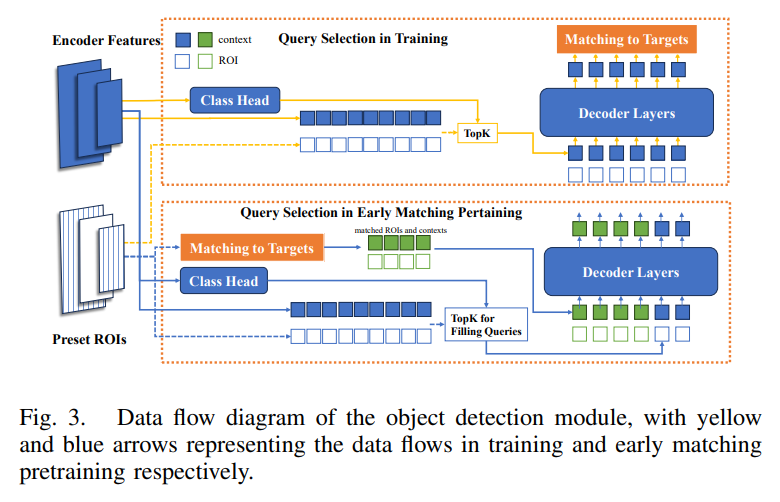
模型在兩階段可變形DETR的基礎上進行了改進,如圖3所示。作為第一種基于transformer的端到端方法,DETR由于獨立于任何手動設計方法,被許多學者認為是目標檢測的新方向。然而,DETR中不明確的查詢和二分匹配帶來的不確定性導致訓練過程中收斂速度極慢。我們發現,在DETR的長期訓練中,大多數時候,二分匹配仍然不穩定。將此歸因于這樣一個事實,即該模型必須經過大量的試驗才能為整個數據集找到合適的查詢,這占用了大部分訓練時間。因此,在目標檢測模塊中,我們采用了兩階段可變形DETR,并為查詢選擇過程設計了早期匹配預訓練。在常規訓練階段,從編碼器輸出的每個多尺度特征在查詢選擇過程中被分配一個預設的ROI。這些特征是通過分類Head計算的,并選擇得分最高的前k個特征作為查詢的上下文信息,其相應的ROI作為查詢的位置。在通過可變形解碼器之后,然后將它們與GT進行匹配。在早期匹配預訓練中,預先設置的ROI和groundtruth之間的先前二分匹配確保了確定性,避免了搜索合適查詢的漫長過程,從而加快了后續的常規訓練。在目標檢測的最后階段,由可變形detr解碼器處理的查詢已經具有模糊的3D空間信息。除了分類頭和2D bounding box Head之外,我們還添加了一個額外的3D bounding box Head。這用于預測camera坐標系下目標的3D邊界框。然后,根據相機的外參,將其轉換到占用網格坐標系中,為后續的3D占用解碼器提供位置先驗。
2)3D Occupancy Decoder
在目標檢測階段之后,選擇高置信度結果,并且將它們的特征連同占用網格坐標系中預測的3D框一起傳送到3D占用解碼器模塊中。考慮到我們并不完全相信3D box的預測結果,適度地放大了所有的3D box。如圖4所示,采用了兩種查詢構建模式。在具有高程模式的BEV查詢中,在該三維長方體的中間層均勻采樣32×32個點。另一方面,在3D長方體查詢模式中,在整個3D長方體空間中均勻采樣16×16×4個點。這些點被稱為三維參考點,當投影到2D圖像上時,它們被稱為2D參考點,這些三維參考點的位置嵌入與上下文結合用作三維查詢!
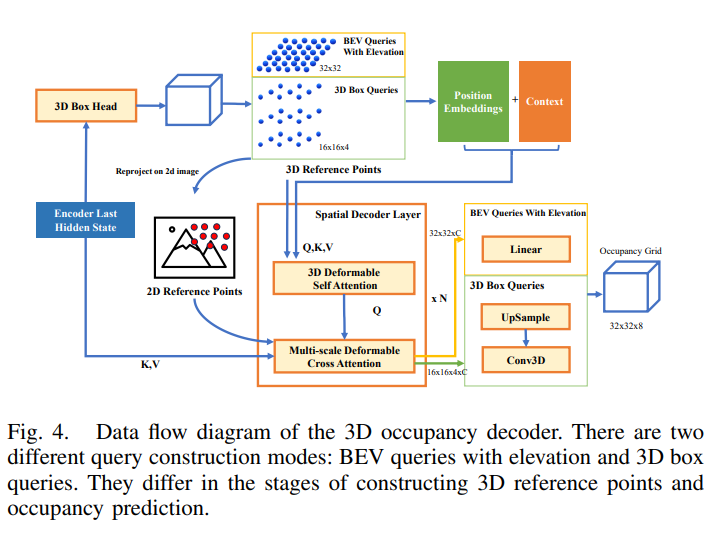
3D占用解碼器包括N層空間解碼器層。每個空間解碼器層由3D可變形的自注意和多尺度可變形的交叉注意構成,三維可變形自我注意的過程可以公式化如下:
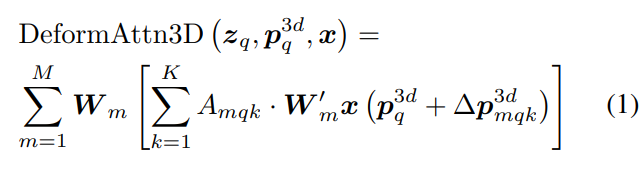
最后,使用線性層將具有高程的BEV查詢直接提升到三維占用網格中。或者,通過使用與3D卷積相結合的上采樣,將3D Box Queries擴展到相同大小的3D占用網格!
3)訓練策略
整個訓練過程分為四個步驟。盡管有多個階段,但始終有相同的注標注數據,這使得過程不會過于復雜。第一步涉及通過早期匹配進行預訓練,以加速兩階段可變形detr的收斂。第二步涉及對兩階段可變形detr的定期訓練,從而產生訓練有素的目標檢測模型。在第三步中,凍結目標檢測模型的權重,并利用其結果來訓練3D占用解碼器。在第四步也是最后一步中,不再凍結目標檢測模型的權重,并使用較小的學習率對整個模型進行微調。
損失函數如下:
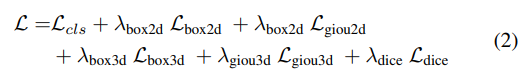
實驗對比
1)實驗數據集和設置
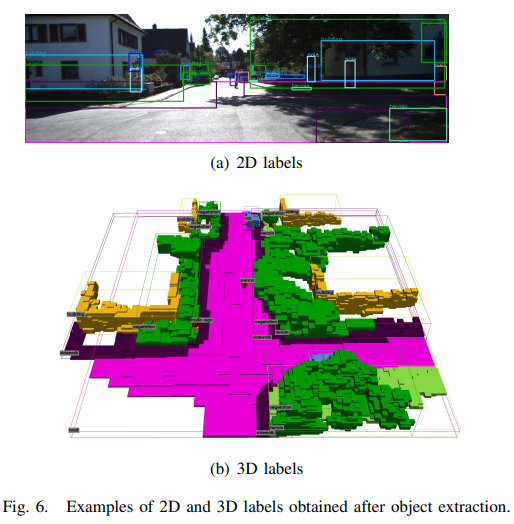
SemanticKITTI數據集建立在KITTI Odometry數據集基礎上,強調使用激光雷達點和前向相機對場景的語義理解。OccupancyDETR作為單目3D語義占用感知,僅使用左前視圖相機作為輸入。在該數據集中,注釋的語義占用表示為形狀為256×256×32的體素網格。每個體素的尺寸為0.2m×0.2m×0.2m,并帶有21個語義類別的標簽(19個語義,1個自由,1個未知)。考慮到該數據集的語義體素網格是由多幀拼接的激光雷達點云和圖像生成的,在遠處或遮擋區域存在間隙,這種情況阻礙了目標的聚類和提取。因此,通過插值來填補語義體素網格中這些缺失的單元,從而糾正了這個問題,目標提取后獲得的數據集的2D和3D標簽如圖6所示。
模型訓練是在Nvidia RTX 3090 GPU(24G)上進行的,而評估是在Nvidia RTX3080 GPU(16G)上進行的。訓練過程跨越四個階段,分別為50個epoch、10個epoch、50個epoch和10個epoch。每個階段的初始學習率分別設置為1e-4、2e-5、1e-4和2e-5,然后線性地減小到零,采用權重衰減為0.01的AdamW作為優化器。ResNet50主干使用timm提供的預訓練模型進行初始化,我們的實驗目標是驗證這個新框架的可行性和特點;因此,這里不使用任何數據擴充!
2)實驗結果
如表I所示,語義場景補全(SSC)任務的mIoU對比一覽:
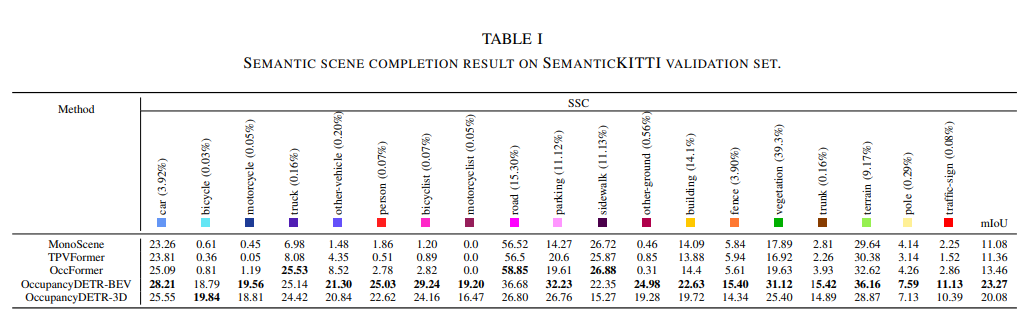
這里將本文的方法與其它單目3D語義占用感知方法進行了比較,并對結果進行了分析。可以看出,我們的方法在小目標上明顯優于其他方法,這歸因于目標檢測任務;然而,在道路和人行道等類別中,我們的方法落后于其他方法,對此我們進行了進一步的分析。分析的代表性案例如圖5所示。
①展示了我們的方法在小目標類別上的性能,它可以檢測到遠處的自行車手。②以及③揭示表現不佳的原因,我們在“道路”和“人行道”類別上的方法。我們認為這是由于我們的方法首先檢測目標,然后預測每個目標的3D占用網格。然而,提取關于3D空間中不同目標之間關系的特征的能力相對較弱,這導致了模型可以基于圖像直接檢測附近的十字路口,但無法基于其他3D目標間接完成遠處的十字路口的現象!
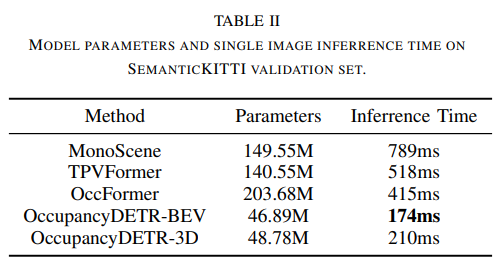
盡管如此,我們的方法在速度和資源需求方面的優勢是顯著的,推理時間和參數計數如表II所示。我們的方法平均推理時間為174ms(在Nvidia RTX 3080上),這已經實現實時性能。接下來,將BEV查詢的兩種模式:高程和3D box查詢進行比較。發現對于大多數類別,具有高程模式的BEV查詢表現更好,尤其是在道路、人行道、terrain和植被四類中,這四類查詢存在顯著差異。考慮到這四個類別在該數據集中通常是平坦的,它們更適合于具有高程模式的BEV查詢。這說明了對于具有不同形狀的目標,這兩種模式之間的顯著性能差異。
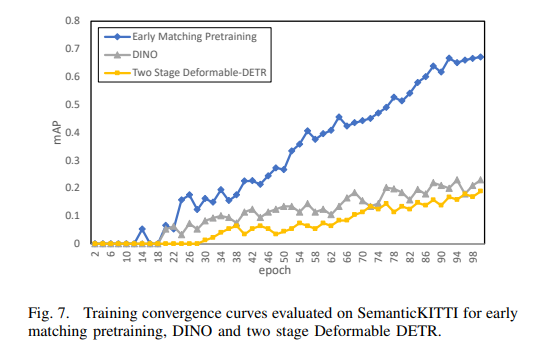
為了驗證早期匹配預訓練對類似DETR的目標檢測模型的積極影響,我們在相同的實驗條件下對DINO和兩階段可變形DETR進行了比較研究。在我們的實驗中,將初始學習率設置為1e-4,并在100個epoch內將其線性降低至零。圖7顯示了訓練過程中驗證集上三種方法的mAP曲線,表明早期匹配預訓練可以更快地收斂。此外,我們還分析了DINO的性能,這是一種基于兩階段可變形DETR的方法。DINO提出了一些改進來加速收斂,其中之一是混合查詢選擇。這個過程包括使用可學習嵌入作為靜態內容查詢,同時通過查詢選擇選擇錨點作為動態錨點。然而,靜態內容查詢和動態錨點的順序之間存在錯位問題,我們假設這種差異是DINO的表現沒有達到預期的原因。

原文鏈接:https://mp.weixin.qq.com/s/b6Y_5d5t7jqkJQL22_hYBA
















