Apache Doris入門,下一代實時數據倉庫
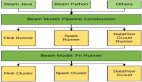
1 Apache Doris
Apache Doris是一個開源的實時數據倉庫,可以從各種數據源收集數據,包括關系型數據庫(MySQL、PostgreSQL、SQL Server、Oracle等)、日志和來自物聯網設備的時間序列數據。Apache Doris支持報表、即席分析、聯合查詢和日志分析等功能,因此可以用于支持儀表盤、自助式商業智能、A/B測試和用戶行為分析等應用。
Apache Doris支持批量導入和流式寫入,可以與Apache Spark、Apache Hive、Apache Flink、Airbyte、DBT和Fivetran等工具很好地集成。Apache Doris還可以連接到Apache Hive、Apache Hudi、Apache Iceberg、Delta Lake和Apache Paimon等數據湖。
 圖片
圖片
2 性能
作為實時OLAP引擎,Apache Doris在查詢速度上具有競爭優勢。根據TPC-H和SSB-Flat基準測試結果,Doris的性能遠遠超過了Presto、Greenplum和ClickHouse。
在自我演進方面,過去兩年中,Doris在復雜查詢和平面表分析方面的查詢速度提高了10倍以上。
 圖片
圖片
3 架構設計
Apache Doris之所以能夠實現如此快速的速度,是因為其背后的架構設計、特性和機制對Doris的性能起到了貢獻。
首先,Apache Doris擁有一個基于成本的優化器(CBO),可以找出復雜大查詢的最高效執行計劃。它擁有完全向量化的執行引擎,因此可以減少虛擬函數調用和緩存未命中。Apache Doris是基于MPP(Massively Parallel Processing)的,可以充分發揮用戶的計算機和核心的作用。在Doris中,查詢執行是數據驅動的,這意味著查詢是否執行取決于其相關數據是否準備就緒,這樣可以更高效地利用CPU。
4 基于列的數據庫的快速點查詢
Apache Doris是一種面向列的數據庫,因此可以更輕松、更快速地進行數據壓縮和數據分片。但是,在面向客戶服務等場景中,這種存儲方式可能不太適用。在這些情況下,數據平臺需要同時處理大量用戶的請求(稱為“高并發點查詢”),而列存儲引擎會增加每秒I/O操作的數量,特別是在數據以平面表的形式排列時。
為了解決這個問題,Apache Doris實現了混合存儲,即同時使用行存儲和列存儲。
 圖片
圖片
此外,由于點查詢都是簡單查詢,調用查詢計劃器將是不必要和浪費的,所以Doris對它們執行了短路計劃,以減少開銷。
在高并發點查詢中,另一個開銷較大的來源是SQL解析。為此,Doris引入了預編譯語句的概念。其思想是預先計算SQL語句并緩存它們,以便在類似查詢中重復使用。
 圖片
圖片
5 數據采集
Apache Doris提供了多種數據導入方法。
實時流寫入:
- Stream Load:通過該方法,可以通過HTTP編寫本地文件或數據流。在某些情況下,它具有線性可擴展性,并且可以達到每秒1000萬條記錄的吞吐量。
- Flink-Doris-Connector:該連接器內置Flink CDC,可以將數據從OLTP數據庫導入Doris。到目前為止,我們已經實現了從MySQL和Oracle到Doris的數據自動同步。
- Routine Load:通過該方法,可以從Kafka消息隊列訂閱數據。
- Insert Into:當嘗試在Doris內部進行ETL時,例如從一個Doris表寫入另一個Doris表時,可以使用此方法。
批量寫入:
- Spark Load:使用該方法,您可以利用Spark資源在寫入Doris之前對HDFS和對象存儲中的數據進行預處理。
- Broker Load:支持HDFS和S3協議。
- insert into <internal table> select from <external table>:這個簡單的語句允許您將Doris連接到各種存儲系統、數據湖和數據庫。
6 數據更新
對于數據更新,Apache Doris提供的是對Merge on Read和Merge on Write的支持。前者用于低頻批量更新,后者用于實時寫入。通過Merge on Write,最新的數據將在執行查詢時準備就緒,這就是為什么與Merge on Read相比,它可以將查詢速度提高5到10倍的原因。
從實現的角度來看,以下是一些常見的數據更新操作,Doris都支持:
- Upsert:替換或更新整行數據
- 部分列更新:更新行中的幾個列
- 條件更新:通過組合幾個條件來過濾出一些數據,以進行替換或刪除
- Insert Overwrite:重寫表或分區
在某些情況下,數據更新是并發發生的,這意味著有大量新數據進來并試圖修改現有的數據記錄,因此更新的順序非常重要。這就是為什么Doris允許您決定順序,可以根據事務提交的順序或序列列(在表中提前指定)來決定順序。Doris還支持基于指定謂詞的數據刪除,這就是條件更新的實現方式。
7 服務可用性和數據可靠性
除了在查詢和數據采集方面具有快速性能外,Apache Doris還提供了服務可用性保證,具體如下:
從架構上來說,Doris有兩個進程:前端和后端。它們都可以輕松擴展。前端節點管理集群、元數據并處理用戶請求;后端節點執行查詢,并具備自動數據平衡和自動恢復的能力。它支持集群升級和擴展,以避免服務中斷。
 圖片
圖片
8 跨集群復制
企業用戶,尤其是金融或電商領域的用戶,需要備份集群或整個數據中心,以防不測之需。因此,Doris 2.0提供了跨集群復制(CCR)。使用CCR,用戶可以實現以下功能:
- 災難恢復:快速恢復數據服務
- 讀寫分離:主集群+從集群;一個用于讀取,一個用于寫入
- 集群的隔離升級:對于集群擴展,CCR允許用戶預先創建一個備份集群進行試運行,以便清除可能的不兼容問題和錯誤。
測試表明,Doris CCR可以達到幾分鐘的數據延遲。在最佳情況下,它可以達到硬件環境的最高速度。
 圖片
圖片
9 多租戶管理
Apache Doris具有復雜的基于角色的訪問控制,并且可以對數據庫、表、行和列進行細粒度的權限控制。
 圖片
圖片
為了資源隔離,Doris過去實施了硬隔離計劃,即將后端節點劃分為資源組,并將資源組分配給不同的工作負載。這是一個硬隔離計劃。它簡單而整潔。但是有時用戶可以充分利用他們的計算資源,因為一些資源組是空閑的。
 圖片
圖片
因此,Doris 2.0引入了工作負載組,而不是資源組。為工作負載組設置了軟限制,限制其可以使用的資源數量。當達到軟限制時,同時有一些空閑資源可用。空閑資源將在工作負載組之間共享。用戶還可以根據對空閑資源的訪問優先級來對工作負載組進行優先級排序。
 圖片
圖片
10 易于使用
Apache Doris提供了許多功能,同時也非常易于使用。Apache Doris支持標準SQL,并兼容MySQL協議和市場上的大多多BI工具。
為了提高易用性,引入了一個名為輕量級模式更改(Light Schema Change)的功能。這意味著如果用戶需要在表中添加或刪除某些列,他們只需要在前端更新元數據,而無需修改所有數據文件。輕量級模式更改可以在毫秒級內完成。它還允許更改索引和列的數據類型。輕量級模式更改與Flink-Doris-Connector的結合意味著上游表格的同步可以在毫秒級內完成。
11 半結構化數據分析
半結構化數據是常見的數據類型,其中包括日志、可觀測性數據和時間序列數據等。這些數據具有一定的結構,但不符合傳統的關系型數據庫的嚴格模式。處理這些數據時,需要支持無模式的靈活性、低成本存儲以及多維分析和全文搜索等功能。
在文本分析中,使用LIKE運算符是常見的操作。為了提高性能,我們進行了大量的優化工作。其中一項優化是將LIKE運算符下推到存儲層,以減少數據掃描的量。此外,我們還引入了NGram Bloomfilter、Hyperscan正則表達式匹配庫和Volnitsky算法等技術,用于更高效地進行子字符串匹配操作。這些優化措施可以改善文本分析的性能和效率。
 圖片
圖片
這里還引入了倒排索引用于文本標記化。它是模糊關鍵字搜索、全文搜索、等價查詢和范圍查詢的有力工具。
12 數據湖倉庫
為了讓用戶構建高性能的數據湖倉庫和統一的查詢網關,Doris 可以映射、緩存和自動刷新來自外部源的元數據。它支持 Hive Metastore 和幾乎所有開放的數據湖倉庫格式。您可以將其連接到關系型數據庫、Elasticsearch 和其他許多源。它還允許您重用自己的身份驗證系統,如 Kerberos 和 Apache Ranger,用于外部表。
基準測試結果顯示,Apache Doris 在對 Hive 表進行查詢時比 Trino 快 3~5 倍。這是幾個特性的共同結果:
- 高效的查詢引擎
- 熱數據緩存機制
- 計算節點
- Doris 中的視圖
計算節點是版本 2.0 中針對數據湖倉庫引入的一種解決方案。與普通的后端節點不同,計算節點是無狀態的,不存儲任何數據。它們在集群擴展期間不參與數據平衡。因此,在計算高峰時,它們可以靈活而容易地加入集群。
此外,Doris 允許您將外部表的計算結果寫入 Doris 中以形成視圖。這與材料化視圖的思想類似:用空間換取速度。在執行對外部表的查詢后,結果可以在 Doris 內部存儲。當出現類似的后續查詢時,系統可以直接從 Doris 中讀取先前查詢的結果,從而提高速度。
13 層級存儲
層級存儲的主要目的是節省成本。層級存儲將熱數據和冷數據分開存儲,熱數據是經常訪問的數據,而冷數據則不是。它允許用戶將熱數據放入快速但昂貴的磁盤(如 SSD 和 HDD),將冷數據放入對象存儲中。
 圖片
圖片
粗略地說,對于由 80% 冷數據組成的數據資產,層級存儲將減少存儲成本約 70%。