













GPT-4推理更像人了!中國科學院提出「思維傳播」,類比思考完勝CoT,即插即用
如今,GPT-4、PaLM等巨型神經網絡模型橫空出世,已經展現出驚人的少樣本學習能力。
只需給出簡單提示,它們就能進行文本推理、編寫故事、回答問題、編程......
對此,中國科學院和耶魯大學的研究人員提出了一種「思維傳播」(Thought Propagation)新框架,能夠通過「類比思維」增強LLM的推理。

論文地址:https://arxiv.org/abs/2310.03965
「思維傳播」靈感來自人類認知,即當遇到一個新問題時,我們經常將其與我們已經解決的類似問題進行比較,以推導出策略。
因此,這一方法的核心便是,讓LLM在解決輸入的問題之前,探索與輸入相關的「類似」問題。
最后,它們的解決方案可以拿來即用,或提取有用計劃的見解。
可以預見的是,「思維傳播」在為LLM邏輯能力的固有限制提出的全新思路,讓大模型像人類一樣用「類比」方法解決難題。
LLM多步推理,敗給人類
顯而易見,LLM擅長根據提示進行基本推理,但在處理復雜的多步驟問題時仍有困難,比如優化、規劃。
反觀人類,他們會汲取類似經驗中的直覺來解決新問題。
大模型無法做到這點,是由其固有的局限性決定的。
因為LLM的知識完全來自于訓練數據中的模式,無法真正理解語言或概念。因此,作為統計模型,它們很難進行復雜的組合泛化。

最最重要的是,LLM缺乏系統推理能力,無法像人類那樣逐步推理,從而解決具有挑戰性的問題。
再加上,大模型的推理是局部的、「短視的」,因此LLM很難找到最佳解決方案,也很難在長時間范圍內保持推理的一致性。
總之,大模型在數學證明、戰略規劃和邏輯推理方面的缺陷,主要源于2個核心問題:
- 無法重用先前經驗中的見解。
人類從實踐中積累了可重復使用的知識和直覺,有助于解決新問題。相比之下,LLM在處理每個問題時都是 「從0開始」,不會借鑒先前的解決方案。
- 多步驟推理中的復合錯誤。
人類會監控自己的推理鏈,并在必要時修改最初的步驟。但是LLM在推理的早期階段所犯的錯誤會被放大,因為它們會把后面的推理引向錯誤的道路。
以上這些弱點,嚴重阻礙了LLM應對需要全局最優或長期規劃的復雜挑戰中的應用。
對此,研究人員提出了一種全新的解決方法——思維傳播。
TP框架
通過類比思維,讓LLM更像人類一樣進行推理。
在研究者看來,從0開始推理無法重復使用解決類似問題的見解,而且會在中間推理階段出現錯誤累積。
而「思維傳播」可以探索與輸入問題相關的類似問題,并從類似問題的解決方案中獲得啟發。
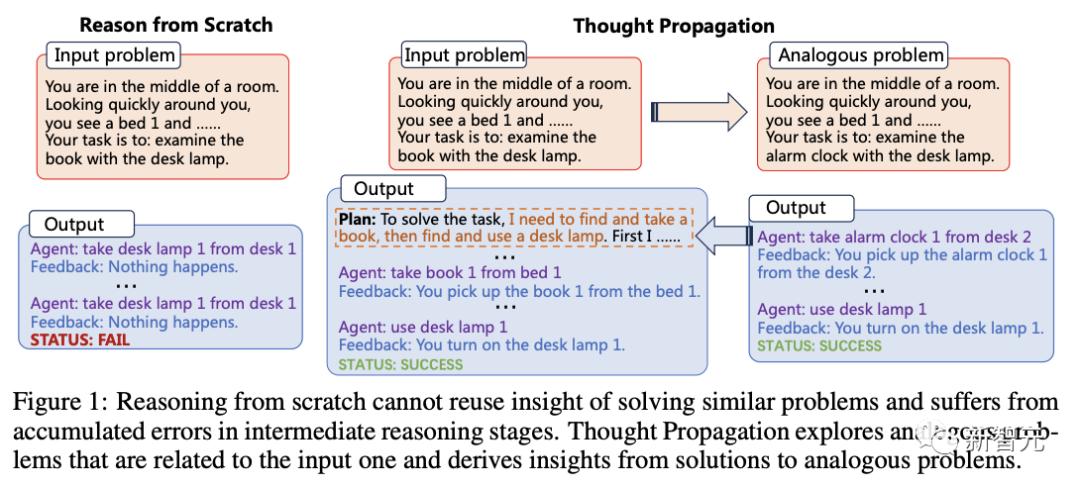
下圖是「思維傳播」(TP)與其他代表性技術的比較,對于輸入問題 p,IO、CoT和ToT會從頭開始推理,才得出解決方案s。
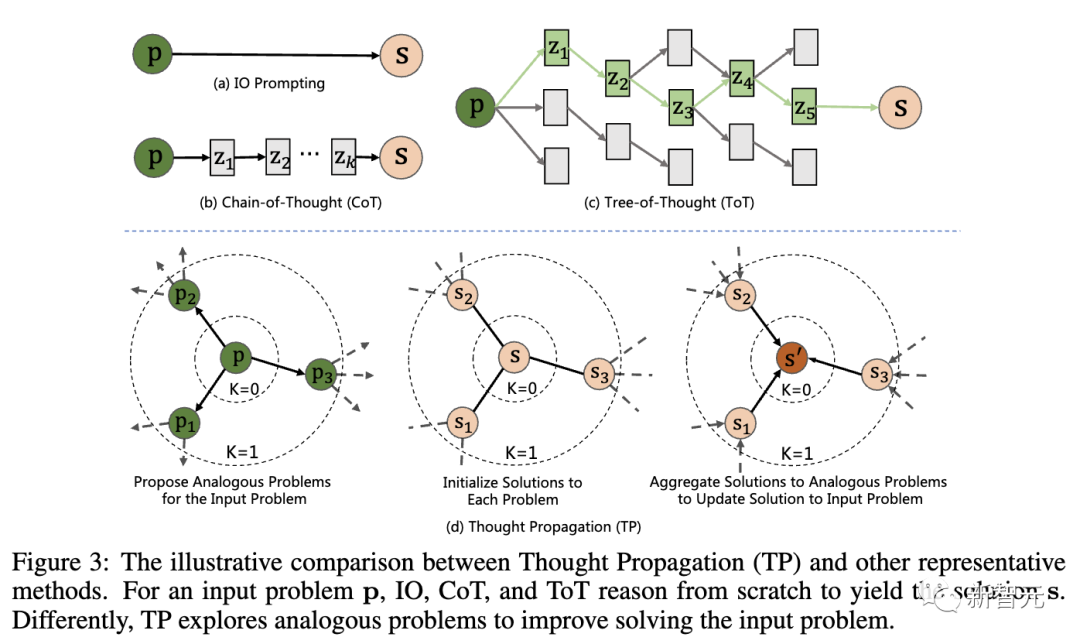
具體來說,TP包括了三個階段:
1. 提出類似問題:LLM通過提示生成一組與輸入問題有相似之處的類似問題。這將引導模型檢索潛在的相關先前經驗。
2. 解決類似問題:通過現有的提示技術,如CoT,讓LLM解決每個類似的問題。
3. 匯總解決方案:有2種不同的途徑——根據類比解決方案,直接推斷出輸入問題的新解決方案;通過比較輸入問題的類比解決方案,推導出高級計劃或策略。
這樣一來,大模型就可以重用先前的經驗和啟發式方法,還可以將其初始推理與類比解決方案進行交叉檢查,以完善這些解決方案。
值得一提的是,「思維傳播」與模型無關,可以在任何提示方法的基礎上進行單個問題解決步驟。
這一方法關鍵的新穎之處在于,激發LLM類比思維,以引導復雜的推理過程。
「思維傳播」究竟能讓LLM多像人類,還得實操結果來說話。
中國科學院和耶魯的研究人員在3個任務中進行了評估:
- 最短路徑推理:需要在圖中找到節點之間的最佳路徑需要全局規劃和搜索。即使在簡單的圖上,標準技術也會失敗。
- 創意寫作:生成連貫、有創意的故事是一個開放式的挑戰。當給出高層次的大綱提示時,LLM通常會失去一致性或邏輯性。
- LLM智能體規劃:與文本環境交互的LLM智能體與長期戰略方面舉步維艱。它們的計劃經常會出現「漂移」或陷入循環。
最短路徑推理
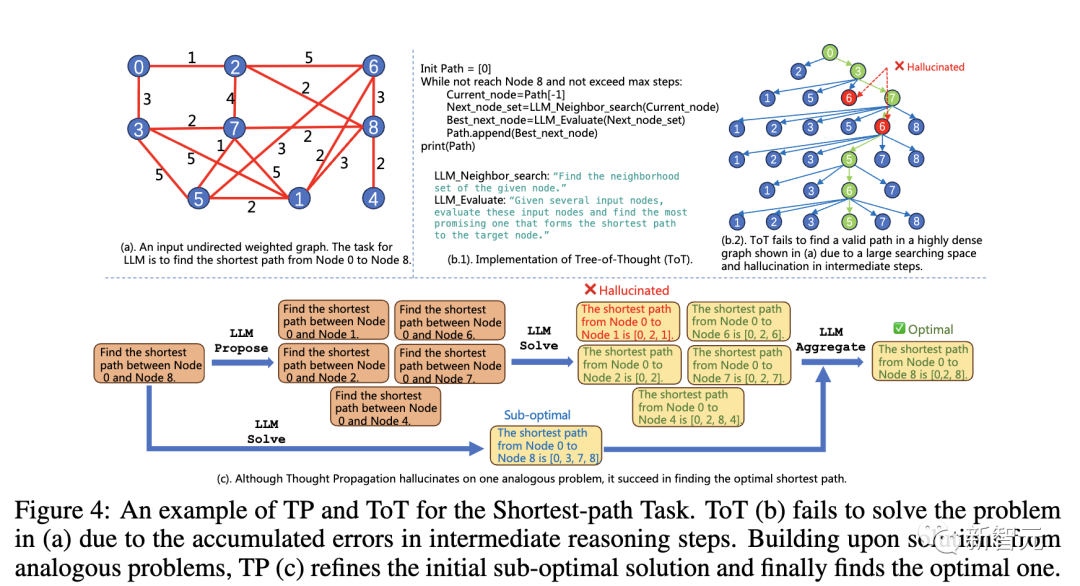
最短路徑推理任務中,現有的方法推理遇到的問題無法解決。
雖然(a)中的圖非常簡單,但由于推理從0開始,這些方法只能讓LLM找到次優解(b,c),甚至重復訪問中間節點(d)。

如下是結合了TP和ToT使用的例子。
由于中間推理步驟的錯誤累積,ToT (b) 無法解決 (a) 中的問題。基于類似問題的解決方案,TP (c) 完善了最初的次優解決方案,并最終找到了最優解決方案。
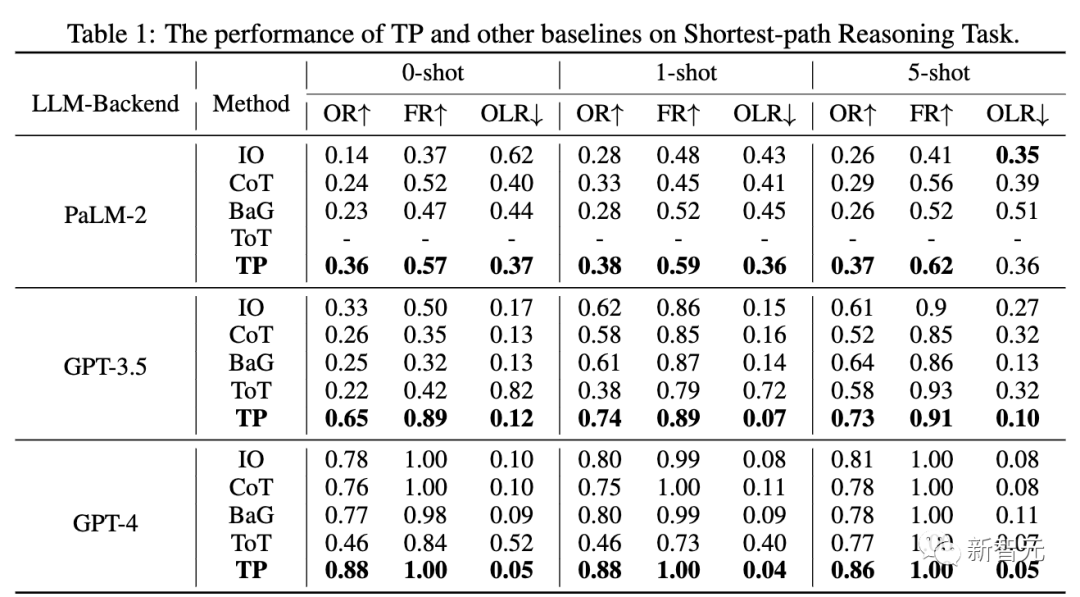
通過與基線比較,TP在處理最短路徑任務中的性能顯著提升了12%, 生成了最優和有效的最短路徑。
此外,由于OLR最低,與基線相比,TP生成的有效路徑最接近最優路徑。
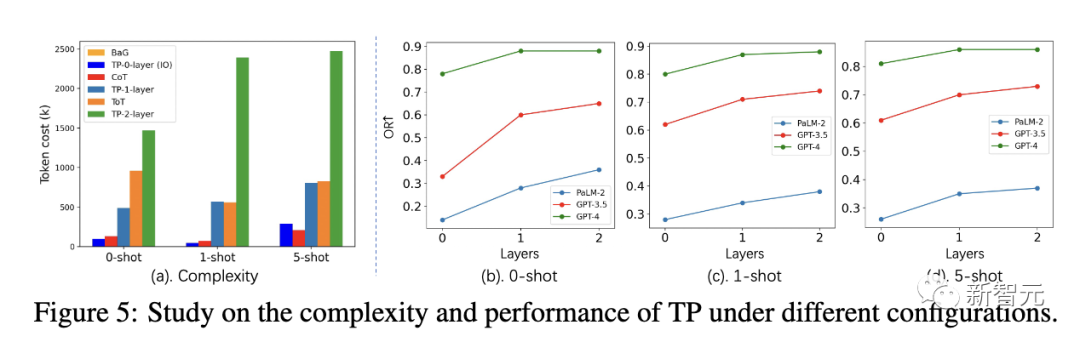
同時,研究人員還進一步研究了TP層數對最短路徑任務復雜性和性能的影響。
在不同設置下,1層TP的token成本與ToT類似。但是,1層TP在尋找最優最短路徑方面,已經取得了非常有競爭力的性能。
此外,與0層TP(IO)相比,1層TP的性能增益也非常顯著。圖5 (a) 顯示了2層TP的token成本增加。
創意寫作
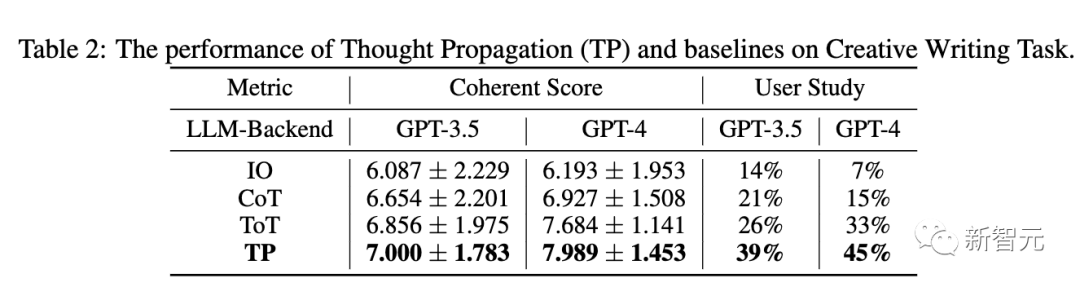
下表2顯示了TP和基線在GPT-3.5和GPT-4中的表現。在一致性上,TP都超過了基線。另外,在用戶研究中,TP在創意寫作中人類偏好提高了13%。
LLM智能體規劃
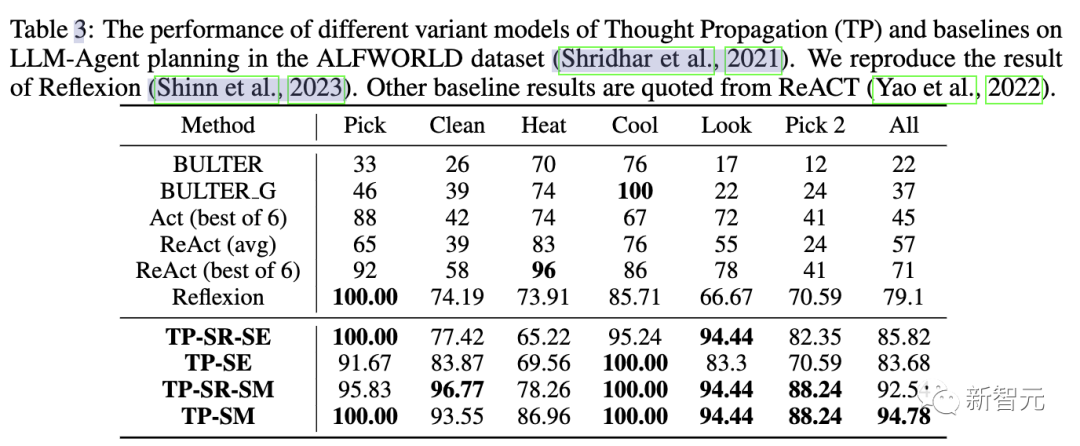
在第三個任務評估中,研究人員使用ALFWorld游戲套件,在134個環境中實例化LLM智能體規劃任務。
TP在LLM智能體規劃中任務完成率提高15%。這表明,在完成類似任務時,對成功規劃的反思TP具有優越性。
通過以上的實驗結果表明,「思維傳播」可以推廣到各種不同的推理任務中,并在所有這些任務中表現出色。
增強LLM推理的關鍵
「思維傳播」模型為復雜的LLM推理提供了一種全新的技術。
類比思維是人類解決問題能力的標志,它可以帶來一系列系統性的優勢,比如更高效的搜索和錯誤糾正。
類似的,LLM也能通過提示類比思維,更好地克服自身弱點,如缺乏可重用的知識和級聯的局部錯誤等。
然而,這些研究結果存在一些限制。
高效地生成有用的類比問題并不容易,而且鏈式更長的類比推理路徑可能會變得臃腫不堪。同時,控制和協調多步推理鏈也依舊十分困難。
不過,「思維傳播」還是通過創造性地解決LLM的推理缺陷,為我們提供了一個有趣的方法。
隨著進一步的發展,類比思維可能會使LLM的推理變得更加強大。而這也為在大語言模型中實現更像人類的推理指明了道路。
作者介紹
Ran He(赫然)

赫然是中國科學院自動化研究所模式識別國家實重點驗室和中國科學院大學的教授, IAPR Fellow和IEEE高級會員。
此前,他在大連理工大學獲得學士和碩士學位,并于2009年于中國科學院自動化研究所獲得博士學位。
他的研究方向是生物識別算法(人臉識別與合成、虹膜識別、人物再識別)、表征學習(使用弱/自監督或遷移學習預訓練網絡)、生成學習(生成模型、圖像生成、圖像翻譯)。
他在國際期刊和會議上發表了200多篇論文,其中包括IEEE TPAMI、IEEE TIP、IEEE TIFS、IEEE TNN、IEEE TCSVT等著名國際期刊,以及CVPR、ICCV、ECCV、NeurIPS等頂級國際會議。
他是IEEE TIP、IEEE TBIOM和Pattern Recognition編委會成員,并曾擔任CVPR、ECCV、NeurIPS、ICML、ICPR和IJCAI等國際會議的區域主席。
Junchi Yu(俞俊馳)

俞俊馳是中國科學院自動化研究所的四年級博士生,導師是赫然教授。
此前,他曾在騰訊人工智能實驗室實習,并與Tingyang Xu博士、Yu Rong博士、Yatao Bian博士和Junzhou Huang教授共事。目前,他是耶魯大學計算機科學系的交流生,師從Rex Ying教授。
他的目標是開發具有良好可解釋性和可移植性的可信圖學習(TwGL)方法,并探索其在生物化學方面的應用。





















