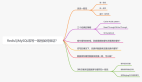
探索 Redis 與 MySQL 的雙寫問題
在日常的應用開發中,我們經常會遇到需要使用多種不同類型的數據庫管理系統來滿足各種業務需求。其中最典型的就是Redis和MySQL的組合使用。
這兩者擁有各自的優點,例如Redis為高性能的內存數據庫提供了極快的讀寫速度,而MySQL則是非常強大的關系型數據庫,支持事務處理,并且提供了很好的數據一致性。
然而,在實際應用過程中,如何保證Redis和MySQL雙寫時的數據一致性問題成為了開發者們面臨的重要挑戰。本文即將針對這個問題進行深入探討,希望能為廣大開發者們提供一些有價值的思路和解決方案。

一、雙寫一致問題
雙寫一致性問題主要是指當我們同時向Redis和MySQL寫數據時,由于網絡延遲、服務器故障等原因,可能導致數據在兩個系統之間產生不一致。
例如,你可能已經更新了MySQL中的數據,但是Redis中的數據還未來得及更新,或者反過來。這樣的結果就可能導致用戶讀到的是舊的、不正確的數據。
比如在現實生活中的購物網站場景:假設用戶A在購買一件庫存僅剩1件的商品,系統在接收到請求后,先將MySQL中的庫存減少1,然后出現了網絡延遲或系統故障,Redis中的庫存沒有減少。此時,用戶B看到的是還有1件商品,也發起了購買請求,如果系統又首先更改了MySQL,那么就會出現超賣的情況,即實際庫存已經沒有,但因為緩存中的信息不準確,導致系統銷售了更多的商品。
嚴格意義上任何非原子操作都不可能保證一致性,除非用阻塞讀寫實現強一致性,所以對于緩存架構我們追求的目標是最終一致性。
實際上,緩存就是通過犧牲強一致性來提高性能的。這是由CAP理論決定的。緩存系統適用的場景就是非強一致性的場景,它屬于CAP中的AP。
二、緩存讀寫策略
解決這種問題的常見策略就是“緩存讀寫策略”。這個策略用于處理先更新數據庫還是先更新緩存等場景。
接下來,我們將探討三種緩存讀寫策略。這些策略各有優劣,沒有絕對的最佳選擇。請根據具體的應用場景選擇最合適的策略。
1.Cache-Aside Pattern(旁路緩存模式)
Cache-Aside Pattern,即旁路緩存模式,它的提出是為了盡可能地解決緩存與數據庫的數據不一致問題。旁路緩存模式中服務端需要同時維護DB和Cache,并且是以DB的結果為準。

讀 :從緩存讀取數據,讀到直接返回。如果讀取不到的話,從數據庫加載,寫入緩存后,再返回響應。

寫:更新的時候,先「更新數據庫,然后再刪除緩存」。
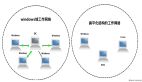
2.Read/Write Through Pattern(讀寫穿透模式)
Read/Write Through Pattern 中服務端把 cache 視為主要數據存儲,從中讀取數據并將數據寫入其中。cache 服務負責將此數據讀取和寫入 DB,從而減輕了應用程序的職責。
因為我們經常使用的分布式緩存 Redis 并沒有提供 cache 將數據寫入DB的功能,所以使用并不多。

讀:從 cache 中讀取數據,讀取到就直接返回 。讀取不到的話,先從 DB 加載,寫入到 cache 后返回響應。
從流程圖中可以看出,讀寫穿透模式和旁路緩存模式的讀取流程幾乎相同。不過,在旁路緩存模式中,客戶端需要負責將數據寫入cache。而在讀寫穿透模式中,cache服務自行寫入緩存,對客戶端來說,這個過程是透明的。

寫:先查 cache,cache 中不存在,直接更新 DB。cache 中存在,則先更新 cache,然后 cache 服務自己更新 DB(同步更新 cache和DB)。
3.Write Behind Pattern(異步緩存寫入模式)
Write Behind Pattern 和 Read/Write Through Pattern 很相似,兩者都是由 cache 服務來負責 cache 和 DB 的讀寫。
但是,兩個又有很大的不同:Read/Write Through 是同步更新 cache 和 DB,而 Write Behind Caching 則是只更新緩存,不直接更新 DB,而是改為異步批量的方式來更新 DB。
很明顯,這種方式對數據一致性帶來了更大的挑戰,比如cache數據可能還沒異步更新DB的話,cache服務可能就掛掉了,反而會帶來更大的災難。
這種策略在我們平時開發過程中也非常非常少見,但是不代表它的應用場景少,比如消息隊列中消息的異步寫入磁盤、MySQL 的 InnoDB Buffer Pool 機制都用到了這種策略。
Write Behind Pattern 下 DB 的寫性能非常高,非常適合一些數據經常變化又對數據一致性要求沒那么高的場景,比如瀏覽量、點贊量等。
三、旁路緩存模式解析
1.Cache Aside Pattern 的一些疑問
旁路緩存模式是我們平時中使用最多的,根據該模式,我們可能會有以下幾個疑問。
(1) 為什么寫操作是刪除緩存,而不是更新緩存
答:假設線程A先發起一個寫操作,第一步先更新數據庫。線程B再發起一個寫操作,緊接著也更新了數據庫。由于網絡等原因,線程B比線程A先更新了緩存,然后線程A更新緩存。
這時候,緩存保存的是A的數據(老數據),而數據庫保存的是B的數據(新數據),數據就不一致了,臟數據出現啦。如果是「刪除緩存取代更新緩存」則不會出現這個臟數據問題。
實際上要寫操作的時候更新緩存也是可以的,不過我們需要加一個鎖/分布式鎖來保證更新cache的時候不存在線程安全問題。
(2) 在寫數據的過程中,為什么要先更新DB再刪除緩存
答:假設請求1 是寫操作,要是先刪除緩存A,這時候來了請求2,請求2是讀操作,先讀緩存A,發現緩存被刪除了(被請求1刪除了),然后去讀數據庫,但是此時請求1還沒來得及把數據及時更新,那么請求2讀的就是舊數據,并且請求2還會把讀到的舊數據放到緩存中,造成了數據的不一致。
其實要先刪緩存,再更新數據庫也是可以,如采用「延時雙刪策略」。
休眠一段時間,再次淘汰緩存。這么做,可以將這段時間內所造成的緩存臟數據,再次刪除。
注意sleep休眠的時間不能小于修改數據庫數據的時間小,基本上1秒就夠了。
(3) 在寫數據的過程中,先更新DB,后刪除cache就沒有問題了么?
答: 理論上來說還是可能會出現數據不一致性的問題,不過概率非常小。
假設這會有兩個請求,一個請求A做查詢操作,一個請求B做更新操作,那么會有如下情形產生:
- 緩存剛好失效。
- 請求A查詢數據庫,得一個舊值。
- 請求B將新值寫入數據庫。
- 請求B刪除緩存。
- 請求A將查到的舊值寫入緩存 ok,如果發生上述情況,確實是會發生臟數據。
然而,發生這種情況的概率并不高
發生上述情況有一個先天性條件,就是步驟(3)的寫數據庫操作比步驟(2)的讀數據庫操作耗時更短,才有可能使得步驟(4)先于步驟(5)。
可是,仔細想想,數據庫的讀操作的速度遠快于寫操作的(不然做讀寫分離干嘛,做讀寫分離的意義就是因為讀操作比較快,耗資源少),因此步驟(3)耗時比步驟(2)更短,這一情形很難出現。
(4) 還有其他造成不一致的原因么?
答: 如果刪除緩存過程中失敗了就會造成不一致問題。可以使用Canal去訂閱數據庫的binlog,獲得需要操作的數據。另起一個程序,獲得這個訂閱程序傳來的信息,進行刪除緩存操作。
2.Cache Aside Pattern 的缺陷
Cache Aside Pattern是一種常見的緩存更新策略,主要在讀取數據時用于處理緩存的失效和更新。盡管它有很多優點,但也存在一些缺陷:
缺陷1:首次請求數據一定不在 cache 的問題
解決辦法:可以將熱點數據提前放入cache 中。
缺陷2:寫操作比較頻繁的話導致cache中的數據會被頻繁被刪除,這樣會影響緩存命中率 。
- 數據庫和緩存數據強一致場景 :更新DB的時候同樣更新cache,不過我們需要加一個鎖/分布式鎖來保證更新cache的時候不存在線程安全問題。
- 可以短暫地允許數據庫和緩存數據不一致的場景 :更新DB的時候同樣更新cache,但是給緩存加一個比較短的過期時間,這樣的話就可以保證即使數據不一致的話影響也比較小。
四、延時雙刪
Redis的延時雙刪策略主要用于解決分布式系統當中的緩存與數據庫數據一致性問題。以下是其基本步驟:
- 先刪除緩存。
- 再更新數據庫。
- 最后延時再次刪除緩存。
該策略的理念是:如果有其他線程在步驟1和步驟2之間查詢到舊的數據并寫入了緩存,那么步驟3可以保證這部分舊的數據被清除,從而盡可能維持數據庫和緩存之間的數據一致性。
以下是使用Java實現的樣例代碼:
import redis.clients.jedis.Jedis;
public class RedisDoubleDelStrategy {
private Jedis jedis;
private static final long DELAY_MILLIS = 1000L; // 設置為你需要的延時時間
public RedisDoubleDelStrategy(String host, int port) {
this.jedis = new Jedis(host, port);
}
public void updateDBAndCache(String key, String value) {
// Step 1: 刪除緩存
jedis.del(key);
// Step 2: 更新數據庫,此處以打印輸出代替
System.out.println("Update DB with: " + value);
// 延遲任務來完成第二次刪除
new Thread(() -> {
try {
Thread.sleep(DELAY_MILLIS);
} catch (InterruptedException e) {
e.printStackTrace();
}
// Step 3: 延時后再次刪除緩存
jedis.del(key);
}).start();
}
}這段代碼實現了延時雙刪策略,但請注意它仍然不能完全保證數據庫和緩存之間的一致性。
在某些情況下(比如大量并發情況下),可能仍然會出現不一致的問題。例如,在步驟3之后,如果還有其他線程查詢到了舊數據并寫入了緩存,那么數據庫和緩存的數據就會不一致。因此,在使用該策略時,需要根據你的系統特性和一致性需求來進行權衡。
本篇文章到這就結束了,在探討Redis與MySQL雙寫問題的過程中,我們分析了各種可能的場景和解決方案。雙寫系統不僅考驗我們對數據庫原理的理解,也展示了協同工作的復雜性。最終,解決這個問題的關鍵是理解你的用例并根據實際需求選擇適當的策略和工具。
而在實際應用中,再完美的方案也可能會遇到挑戰和困難。因此,持續監控,頻繁測試和及時調整策略都至關重要。希望本文能為你在處理Redis與MySQL雙寫問題上提供一些思路和靈感,同時,我們也期待在未來看到更多精妙的解決方案誕生。