Bigkey問題的解決思路與方式探索

一、背景
在Redis運維過程中,由于Bigkey的存在,會影響業(yè)務程序的響應速度,嚴重的還會造成可用性損失,DBA也一直和業(yè)務開發(fā)方強調(diào) Bigkey 的規(guī)避方法以及危害,但是Bigkey一直沒有完全避免。全網(wǎng)Redis集群有2200個以上,實例數(shù)量達到4.5萬以上,在當前階段進行一次全網(wǎng) Bigkey檢查,估計需要以年為時間單位,非常耗時。我們需要新的思路去解決Bigkey問題。
二、Bigkey 介紹
2.1、什么是 Bigkey
在Redis中,一個字符串類型最大可以到512MB,一個二級數(shù)據(jù)結(jié)構(gòu)(比如hash、list、set、zset等)可以存儲大約40億個(2^32-1)個元素,但實際上不會達到這么大的值,一般情況下如果達到下面的情況,就可以認為它是Bigkey了。
- 【字符串類型】: 單個string類型的value值超過1MB,就可以認為是Bigkey。
- 【非字符串類型】:哈希、列表、集合、有序集合等, 它們的元素個數(shù)超過2000個,就可以認為是Bigkey。
2.2 Bigkey是怎么產(chǎn)生的
我們遇到的Bigkey一般都是由于程序設計不當或者對于數(shù)據(jù)規(guī)模預料不清楚造成的,比如以下的情況。
- 【統(tǒng)計】:遇到一個統(tǒng)計類的key,是記錄某網(wǎng)站的訪問用戶的IP,隨著時間的推移,網(wǎng)站訪問的用戶越來越多,這個key的元素數(shù)量也會越來越大,形成Bigkey。
- 【緩存】: 緩存類key一般是這樣的邏輯,將數(shù)據(jù)從數(shù)據(jù)庫查詢出來序列化放到Redis里,如果業(yè)務程序從Redis沒有訪問到,就會查詢數(shù)據(jù)庫并將查詢到的數(shù)據(jù)追加到Redis緩存中,短時間內(nèi)會緩存大量的數(shù)據(jù)到Redis的key中,形成Bigkey。
- 【隊列】:把Redis當做隊列使用,處理任務,如果消費出現(xiàn)不及時情況,將導致隊列越來越大,形成Bigkey。
這三種情況,都是我們實際運維中遇到的,需要謹慎使用,合理優(yōu)化。
2.3 Bigkey ?的危害
我們在運維中,遇到Bigkey的情況下,會導致一些問題,會觸發(fā)監(jiān)控報警,嚴重的還會影響Redis實例可用性,進而影響業(yè)務可用性,在需要水平擴容時候,可能導致水平擴容失敗。
2.3.1內(nèi)存空間不均勻
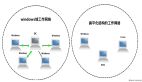
內(nèi)存空間不均勻會不利于集群對內(nèi)存的統(tǒng)一管理,有數(shù)據(jù)丟失風險。下圖中的三個節(jié)點是同屬于一個集群,它們的key的數(shù)量比較接近,但內(nèi)存容量相差比較多,存在Bigkey的實例占用的內(nèi)存多了4G以上了。

可以使用使用Daas平臺“工具集-操作項管理”,選擇對應的slave實例執(zhí)行分析,找出具體的Bigkey。
2.3.2 超時阻塞
Redis是單線程工作的,通俗點講就是同一時間只能處理一個Redis的訪問命令,操作Bigkey的命令通常比較耗時,這段時間Redis不能處理其他命令,其他命令只能阻塞等待,這樣會造成客戶端阻塞,導致客戶端訪問超時,更嚴重的會造成master-slave的故障切換。造成阻塞的操作不僅僅是業(yè)務程序的訪問,還有key的自動過期的刪除、del刪除命令,對于Bigkey,這些操作也需要謹慎使用。
超時阻塞案例
我們遇到一個這樣超時阻塞的案例,業(yè)務方反映程序訪問Redis集群出現(xiàn)超時現(xiàn)象,hkeys訪問Redis的平均響應時間在200毫秒左右,最大響應時間達到了500毫秒以上,如下圖。

hkeys是獲取所有哈希表中的字段的命令,分析應該是集群中某些實例存在hash類型的Bigkey,導致hkeys命令執(zhí)行時間過長,發(fā)生了阻塞現(xiàn)象。
1.使用Daas平臺“服務監(jiān)控-數(shù)據(jù)庫實例監(jiān)控”,選擇master節(jié)點,選擇Redis響應時間監(jiān)控指標“redis.instance.latency.max”,如下圖所示,從監(jiān)控圖中我們可以看到
(1)正常情況下,該實例的響應時間在0.1毫秒左右。
(2)監(jiān)控指標上面有很多突刺,該實例的響應時間到了70毫秒左右,最大到了100毫秒左右,這種情況就是該實例會有100毫秒都在處理Bigkey的訪問命令,不能處理其他命令。
通過查看監(jiān)控指標,驗證了我們分析是正確的,是這些監(jiān)控指標的突刺造成了hkeys命令的響應時間比較大,我們找到了具體的master實例,然后使用master實例的slave去分析下Bigkey情況。


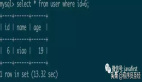
2.使用Daas平臺“工具集-操作項管理”,選擇slave實例執(zhí)行分析,分析結(jié)果如下圖,有一個hash類型key有12102218個fields。

3. 和業(yè)務溝通,這個Bigkey是連續(xù)存放了30天的業(yè)務數(shù)據(jù)了,建議根據(jù)二次hash方式拆分成多個key,也可把30天的數(shù)據(jù)根據(jù)分鐘級別拆分成多個key,把每個key的元素數(shù)量控制在5000以內(nèi),目前業(yè)務正在排期優(yōu)化中。優(yōu)化后,監(jiān)控指標的響應時間的突刺就會消失了。
2.3.3 網(wǎng)絡阻塞
Bigkey的value比較大,也意味著每次獲取要產(chǎn)生的網(wǎng)絡流量較大,假設一個Bigkey為10MB,客戶端每秒訪問量為100,那么每秒產(chǎn)生1000MB的流量,對于普通的千兆網(wǎng)卡(按照字節(jié)算是128MB/s)的服務器來說簡直是滅頂之災。而且我們現(xiàn)在的Redis服務器是采用單機多實例的方式來部署Redis實例的,也就是說一個Bigkey可能會對同一個服務器上的其他Redis集群實例造成影響,影響到其他的業(yè)務。
2.3.4 遷移困難
我們在運維中經(jīng)常做的變更操作是水平擴容,就是增加Redis集群的節(jié)點數(shù)量來達到擴容的目的,這個水平擴容操作就會涉及到key的遷移,把原實例上的key遷移到新擴容的實例上。當要對key進行遷移時,是通過migrate命令來完成的,migrate實際上是通過dump + restore + del三個命令組合成原子命令完成,它在執(zhí)行的時候會阻塞進行遷移的兩個實例,直到以下任意結(jié)果發(fā)生才會釋放:遷移成功,遷移失敗,等待超時。如果key的遷移過程中遇到Bigkey,會長時間阻塞進行遷移的兩個實例,可能造成客戶端阻塞,導致客戶端訪問超時;也可能遷移時間太長,造成遷移超時導致遷移失敗,水平擴容失敗。
遷移失敗案例
我們也遇到過一些因為Bigkey擴容遷移失敗的案例,如下圖所示,是一個Redis集群水平擴容的工單,需要進行key的遷移,當工單執(zhí)行到60%的時候,遷移失敗了。
1. 進入工單找到失敗的實例,使用失敗實例的slave節(jié)點,在Daas平臺的“工具集-操作項管理”進行Bigkey分析。

2. 經(jīng)過分析找出了hash類型的Bigkey有8421874個fields,正是這個Bigkey導致遷移時間太長,超過了遷移時間限制,導致工單失敗了。

3.和業(yè)務溝通,這些key是記錄用戶訪問系統(tǒng)的某個功能模塊的ip地址的,訪問該功能模塊的所有ip都會記錄到給key里面,隨著時間的積累,這個key變的越來越大。同樣是采用拆分的方式進行優(yōu)化,可以考慮按照時間日期維度來拆分,就是一段時間段的訪問ip記錄到一個key中。
4.Bigkey優(yōu)化后,擴容的工單可以重試,完成集群擴容操作。
三、Bigkey的發(fā)現(xiàn)
Bigkey首先需要重源頭治理,防止Bigkey的產(chǎn)生;其次是需要能夠及時的發(fā)現(xiàn),發(fā)現(xiàn)后及時處理。分析Bigkey的方法不少,這里介紹兩種比較常用的方法,也是Daas平臺分析Bigkey使用的兩種方式,分別是Bigkeys命令分析法、RDB文件分析法。
3.1 scan命令分析
Redis4.0及以上版本提供了--Bigkeys命令,可以分析出實例中每種數(shù)據(jù)結(jié)構(gòu)的top 1的Bigkey,同時給出了每種數(shù)據(jù)類型的鍵值個數(shù)以及平均大小。執(zhí)行--Bigkeys命令時候需要注意以下幾點:
- 建議在slave節(jié)點執(zhí)行,因為--Bigkeys也是通過scan完成的,可能會對節(jié)點造成阻塞。
- 建議在節(jié)點本機執(zhí)行,這樣可以減少網(wǎng)絡開銷。
- 如果沒有從節(jié)點,可以使用--i參數(shù),例如(--i 0.1 代表100毫秒執(zhí)行一次)。
- --Bigkeys只能計算每種數(shù)據(jù)結(jié)構(gòu)的top1,如果有些數(shù)據(jù)結(jié)構(gòu)有比較多的Bigkey,是查找不出來的。
Daas平臺集成了基于原生--Bigkeys代碼實現(xiàn)的查詢Bigkey的方式,這個方式的缺點是只能計算每種數(shù)據(jù)結(jié)構(gòu)的top1,如果有些數(shù)據(jù)結(jié)構(gòu)有比較多的Bigkey,是查找不出來的。該方式相對比較安全,已經(jīng)開放出來給業(yè)務開發(fā)同學使用。
3.2 RDB文件分析
借助開源的工具,比如rdb-tools,分析Redis實例的RDB文件,找出其中的Bigkey,這種方式需要生成RDB文件,需要注意以下幾點:
- 建議在slave節(jié)點執(zhí)行,因為生成RDB文件會影響節(jié)點性能。
- 需要生成RDB文件,會影響節(jié)點性能,雖然在slave節(jié)點執(zhí)行,但是也是有可能造成主從中斷,進而影響到master節(jié)點。
Daas平臺集成了基于RDB文件分析代碼實現(xiàn)的查詢Bigkey的方式,可以根據(jù)實際需求自定義填寫N,分析的top N個Bigkey。該方式相對有一定風險,只有DBA有權(quán)限執(zhí)行分析。
3.3 Bigkey 巡檢
通過巡檢,可以暴露出隱患,提前解決,避免故障的發(fā)生,進行全網(wǎng)Bigkey的巡檢,是避免Bigkey故障的比較好的方法。由于全網(wǎng)Redis實例數(shù)量非常大,分析的速度比較慢,使用當前的分析方法很難完成。為了解決這個問題,存儲研發(fā)組分布式數(shù)據(jù)庫同學計劃開發(fā)一個高效的RDB解析工具,然后通過大規(guī)模解析RDB文件來分析Bigkey,可以提高分析速度,實現(xiàn)Bigkey的巡檢。
四、 Bigkey處理優(yōu)化
4.1 Bigkey拆分
優(yōu)化Bigkey的原則就是string減少字符串長度,list、hash、set、zset等減少元素數(shù)量。當我們知道哪些key是Bigkey時,可以把單個key拆分成多個key,比如以下拆分方式可以參考。
- big list:list1、list2、...listN
- big hash:可以做二次的hash,例如hash%100
- 按照日期拆分多個:key20220310、key20220311、key202203212
4.2 Bigkey分析工具優(yōu)化
我們?nèi)W(wǎng)Redis集群有2200以上,實例數(shù)量達到4.5萬以上,有的比較大的集群的實例數(shù)量達到了1000以上,前面提到的兩種Bigkey分析工具還都是實例維度分析,對于實例數(shù)量比較大的集群,進行全集群分析也是比較耗時的,為了提高分析效率,從以下幾個方面進行優(yōu)化:
- 可以從集群維度選擇全部slave進行分析。
- 同一個集群的相同服務器slave實例串行分析,不同服務器的slave實例并行分析,最大并發(fā)度默認10,同時可以分析10個實例,并且可以自定義輸入執(zhí)行分析的并發(fā)度。
- 分析出符合Bigkey規(guī)定標準的所有key信息:大于1MB的string類型的所有key,如果不存在就列出最大的50個key;hash、list、set、zset等類型元素個數(shù)大于2000的所有key,如不存在就給出每種類型最大的50個key。
- 增加暫停、重新開始、結(jié)束功能,暫停分析后可以重新開始。
4.3 水平擴容遷移優(yōu)化
目前情況,我們有一些Bigkey的發(fā)現(xiàn)是被動的,一些是在水平擴容時候發(fā)現(xiàn)的,由于Bigkey的存在導致擴容失敗了,嚴重的還觸發(fā)了master-slave的故障切換,這個時候可能已經(jīng)造成業(yè)務程序訪問超時,導致了可用性下降。
我們分析了Daas平臺的水平擴容時遷移key的過程及影響參數(shù),內(nèi)容如下:
(1)【cluster-node-timeout】:控制集群的節(jié)點切換參數(shù),master堵塞超過cluster-node-timeout/2這個時間,就會主觀判定該節(jié)點下線pfail狀態(tài),如果遷移Bigkey阻塞時間超過cluster-node-timeout/2,就可能會導致master-slave發(fā)生切換。
(2)【migrate timeout】:控制遷移io的超時時間,超過這個時間遷移沒有完成,遷移就會中斷。
(3)【遷移重試周期】:遷移的重試周期是由水平擴容的節(jié)點數(shù)決定的,比如一個集群擴容10個節(jié)點,遷移失敗后的重試周期就是10次。
(4)【一個遷移重試周期內(nèi)的重試次數(shù)】:在一個起遷移重試周期內(nèi),會有3次重試遷移,每一次的migrate timeout的時間分別是10秒、20秒、30秒,每次重試之間無間隔。
比如一個集群擴容10個節(jié)點,遷移時候遇到一個Bigkey,第一次遷移的migrate timeout是10秒,10秒后沒有完成遷移,就會設置migrate timeout為20秒重試,如果再次失敗,會設置migrate timeout為30秒重試,如果還是失敗,程序會遷移其他新9個的節(jié)點,但是每次在遷移其他新的節(jié)點之前還會分別設置migrate timeout為10秒、20秒、30秒重試遷移那個遷移失敗的Bigkey。這個重試過程,每個重試周期阻塞(10+20+30)秒,會重試10個周期,共阻塞600秒。其實后面的9個重試周期都是無用的,每次重試之間沒有間隔,會連續(xù)阻塞了Redis實例。
(5)【遷移失敗日志】:遷移失敗后,記錄的日志沒有包括遷移節(jié)點、solt、key信息,不能根據(jù)日志立即定位到問題key。
我們對這個遷移過程做了優(yōu)化,具體如下:
(1)【cluster-node-timeout】:默認是60秒,在遷移之前設置為15分鐘,防止由于遷移Bigkey阻塞導致master-slave故障切換。
(2)【migrate timeout】:為了最大限度減少實例阻塞時間,每次重試的超時時間都是10秒,3次重試之間間隔30秒,這樣最多只會連續(xù)阻塞Redis實例10秒。
(3)【重試次數(shù)】:遷移失敗后,只重試3次(重試是為了避免網(wǎng)絡抖動等原因造成的遷移失敗),每次重試間隔30秒,重試3次后都失敗了,會暫停遷移,日志記錄下Bigkey,去掉了其他節(jié)點遷移的重試。
(4)【優(yōu)化日志記錄】:遷移失敗日志記錄遷移節(jié)點、solt、key信息,可以立即定位到問題節(jié)點及key。
五、總結(jié)
本文通過對Bigkey的分析,重點介紹了在運維中對bigkey問題的處理思路、解決方式。首先是需要從源頭治理,防止Bigkey形成,DBA應該加強對業(yè)務開發(fā)同學bigkey相關問題的宣導;其次是需要具備及時發(fā)現(xiàn)的能力,這個也是我們現(xiàn)在的不足之處。我們后面會從Bigkey巡檢、Bigkey分析工具的這兩個方面,提高Bigkey發(fā)現(xiàn)能力。
參考資料: