













Meta再放「長文本」殺器Llama 2-Long:70B尺寸登頂最強「32k上下文」模型,超越ChatGPT
雖然大型語言模型在處理日常問答、總結文本等任務上表現非常出色,但如何讓LLM在不顯著增加計算需求、不降低短文本性能的前提下,能夠處理「超長文本輸入」仍然是一個難題。
最近,Meta團隊公開了支持長上下文的模型Llama 2 Long的訓練方法,該模型的有效上下文窗口多達32768個token,在各種合成上下文探測、語言建模任務上都取得了顯著的性能提升。

論文鏈接:https://arxiv.org/pdf/2309.16039.pdf
并且,模型在指令調優的過程中不需要借助人工標注的長指令數據,70B參數量的模型就已經在各種長上下文任務中實現了超越gpt-3.5-turbo-16 k的性能。
除了結果外,論文中還對模型的各個組件進行了深入分析,包括Llama的位置編碼,并討論了其在建模長依賴關系的限制;預訓練過程中各種設計選擇的影響,包括數據混合和序列長度的訓練策略。
消融實驗表明,在預訓練數據集中具有豐富的長文本并不是實現強大性能的關鍵,驗證了長上下文持續預訓練比從頭開始長序列預訓練更有效,同樣有效。
LLAMA 2加長版
1、持續訓練(Continual Pretraining)
由于注意力機制需要進行二次復雜度的計算,如果使用更長的輸入序列進行訓練會導致巨大的計算開銷,研究人員通過實驗對比了不同的訓練策略:從頭開始進行長序列(32768)預訓練、以及在不同階段(20%、40%、80%)從4096長度切換到32768的持續學習。
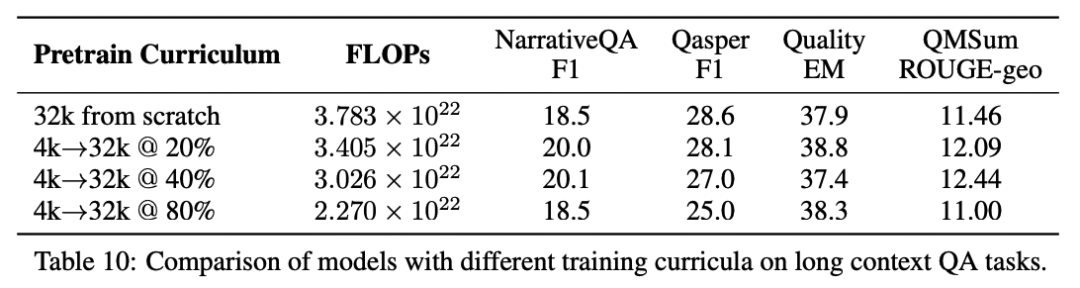
結果發現,在輸入token數量長度相同的情況下,兩個模型的性能幾乎相同,但持續訓練最多可以減少40%的FLOPs
位置編碼(Positional Encoding)
在持續預訓練中,LLAMA 2的原始架構基本沒有變化,僅針對長距離信息捕獲需求對位置編碼進行了修改。
通過對7B尺寸LLAMA 2模型的實驗,研究人員發現了LLAMA 2的位置編碼(PE)的一個關鍵局限性,即阻礙了注意力模塊匯集遠處token的信息。

為了進行長上下文建模,研究人員假設該瓶頸來源于LLAMA 2系列模型使用的RoPE位置編碼,并控制超參數基礎頻率(base frequency)從10, 000增加到500, 000來減少RoPE位置編碼中每個維度的旋轉角度,從而降低了RoPE對遠處token的衰減效應。

從實驗結果來看,RoPE ABF在所有位置編碼變體中取得了最好的效果,證明了簡單修改RoPE即可有效提升模型的上下文長度。
并且,研究人員也選擇沒有選擇稀疏注意力,考慮到LLAMA 2-70B的模型維h為8192,只有當輸入序列長度超過6倍h(即49,152)個token時,注意力矩陣計算和值聚合的成本才會成為計算瓶頸。
數據混合(Data Mix)
在使用改良版位置編碼的基礎上,研究人員進一步探索了不同預訓練數據的組合,通過調整 LLAMA 2 的預訓練數據比例或添加新的長文本數據來提高長上下文能力。

實驗結果發現,在長上下文、持續預訓練的設置下,數據質量往往比文本長度發揮著更關鍵的作用。
優化細節
研究人員持續增加預訓練LLAMA 2檢查點的輸入序列長度,同時保持與LLAMA 2相同的每批token數量;
對所有模型進行了100,000步共計400B個token的訓練;
使用Flash-Attention,當增加序列長度時,GPU 內存開銷幾乎可以忽略不計,使用70B模型的序列長度從4,096增加到 16,384 時,可以觀察到大約17%的速度損失;
對于7B/13B模型,使用學習率2e^-5和余弦學習率調度,預熱步驟為 2000 步;
對于較大的34B/70B模型,必須設置較小的學習率1e^-5才能獲得單調遞減的驗證損失。
2、指令微調(Instruction Tuning)
為LLM對齊收集人工演示和偏好標簽是一個繁瑣而耗時耗力的過程,在長上下文場景下,往往會涉及到復雜的信息流和專業知識,例如處理密集的法律/科學文檔,標注成本還會更高,所以目前大多數開源指令數據集主要由短樣本組成。
在這項工作中,研究人員發現一種簡單且容易實現的方法,可以利用預先構建的大型多樣化短提示數據集,在長語境基準測試中效果也出奇地好。
具體來說,首先使用LLAMA 2-Chat中使用的RLHF數據集,并用LLAMA 2-Chat本身生成的自指導(self-instruct)長數據對其進行擴充,預期模型能夠通過大量RLHF數據學習到一系列不同的技能,并通過自指導數據將知識轉移到長上下文的場景中。
數據生成過程側重于QA格式的任務:從預訓練語料庫中的長文檔開始,隨機選擇一個文本塊,并提示LLAMA 2-Chat根據文本塊中的信息編寫問答對,通過不同的提示收集長短格式的答案。
除此之外,生成過程還包括自我批判(self-critque)步驟,即提示LLAMA 2-CHAT驗證模型生成的答案。
給定生成的 QA 對,使用原始長文檔(已截斷以適應模型的最大上下文長度)作為上下文來構建訓練實例。
對于短指令數據,將其連接為16,384個token序列;對于長指令數據,在右側添加填充token以便模型可以單獨處理每個長實例,而無需截斷。
雖然標準指令微調只計算輸出token的損失,但同時計算長輸入提示的語言建模損失也可以提升下游任務的性能。
實驗結果
1、預訓練評估
短任務
要使長上下文LLM具備普遍實用性,一個重要的要求是確保其在標準短上下文任務中的強大性能。

在短任務實驗中,可以看到其結果與LLAMA 2相當,而且在大多數情況下比LLAMA 2要更強,在編碼、數學和知識密集型任務(如 MMLU)上的結果有明顯改善,優于GPT-3.5

相比其他長上下文方法在短任務的不佳表現,研究人員將該模型的性能改進歸功于額外的計算FLOPs以及從新引入的長數據中學到的知識。
長任務
之前的方法大多依靠易錯性和合成任務來衡量模型在長上下文場景下的性能,與此不同,研究人員使用真實世界的語言任務來進行長上下文的評估:
在NarrativeQA上評估零樣本性能,在QuALITY和Qasper上評估2-shot性能,在QMSum上評估1-shot性能,具體的樣本數根據每個數據集的平均樣本長度決定。
使用的提示非常簡單「{Context} Q: {Question}, A:」,可以減少評估誤差;如果提示語超過模型的最大輸入長度或16,384個詞組,輸入提示語將從左側截斷。

對比其他開源長上下文模型,在 7B 尺度上,只有Together-7B 32k可以與該模型的性能相媲美。
有效利用上下文(Effective Context Utilization)
為了驗證該模型能夠有效利用增加的上下文窗口,從實驗中可以看到,隨著上下文長度的增加,每個長任務的結果都在單調地改善。

除此之外,模型的語言建模損失與上下文長度呈冪律加常數的比例關系,結果表明,盡管收益遞減,但該模型在 32,768 個文本token以內仍然顯示出性能增益(語言建模損失),更大的模型可以更有效地利用上下文。

2、指令微調結果
研究人員在ZeroSCROLLS基準上對指令微調模型進行測試,包含10個長上下文數據集,如摘要、問題回答和多文檔聚合任務。
為了進行公平比較,模型設置為相同的提示、截斷策略和最大生成長度等。
實驗結果顯示,在不使用任何人類標注的長上下文數據的情況下,70B的chat模型在10項任務中的7項都優于gpt-3.5-turbo-16k
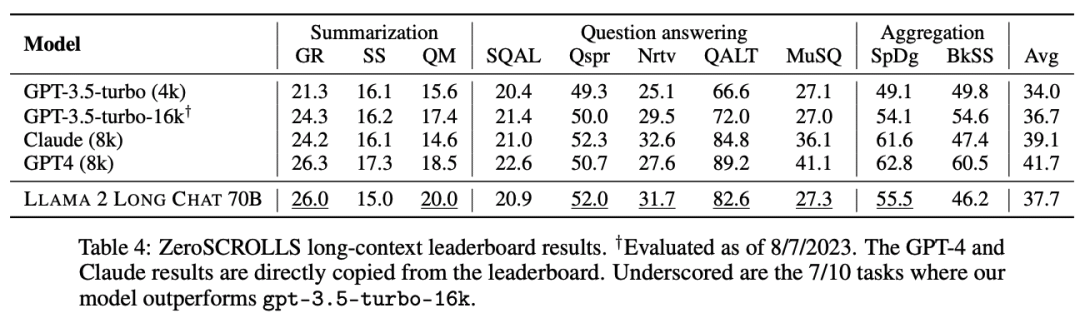
如果使用更多不同的數據進行微調,研究人員預計其性能還會進一步提高。
值得一提的是,評估長上下文LLM是一項比較困難的任務,基準中使用的自動指標在很多方面都有局限性,例如只有單個參考的文本摘要,n-gram也不一定符合人類偏好。
3、人類評估
作為自動評估基準結果的補充,通過詢問標注人在有用性、誠實性和無害性等方面,更喜歡來自文中提出的指令微調模型,還是來自MPT-30B-chat、GPT-4、GPT-3.5-turbo-16k和Claude-2等專有模型的生成來進行人工評估。
與自動度量不同,人類更擅長評估長上下文模型的模型響應質量,因為可接受答案的空間很大。
研究人員主要關注兩個應用場景,評估模型利用信息(檢索到的文檔)來回答給定查詢的能力。
1)多回合對話數據,每個提示都是聊天歷史,模型需要基于聊天歷史生成一致的響應;
2)多文檔搜索查詢應答應用,該模型提供了從搜索會話中檢索到的幾個最相關的文檔以及相應的搜索查詢。
總共2352個樣本,其中每個樣本由3個不同的人類標注人員進行評估,模型相對于其他模型的標準勝率是通過平均每個比較示例的結果來計算的。
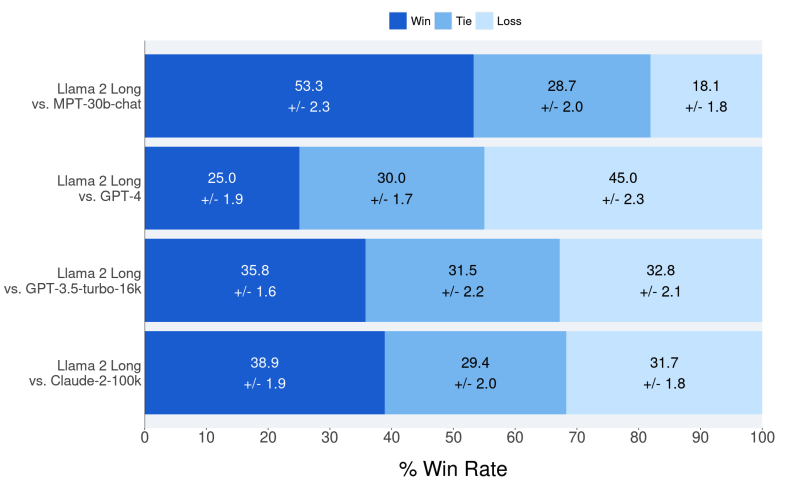
可以看到,Llama 2 Long只需要很少的指令數據就可以實現與MPT-30B-chat、GPT-3.5-turbo-16k和Claude-2相近的性能。



























