基于ChatGPT的智能客服助手
導讀
傳統客服領域,具有大量依賴人工,數據密集等特點。面對大量的用戶提問,人工客服需要根據用戶的問題,從大量數據中找出與用戶問題相關的數據,再組織語言進行回答。響應時間受限于人工客服的工作經驗和業務場景的復雜程度,耗時較長時會嚴重影響用戶的購物體驗。
智能客服,是指借助Large Language Model(LLM)擁有的出色的自然語言處理與理解能力,融合私有數據構建特定場景的智能客服系統,為人工客服提供有力支持,提高人工客服的服務效率與服務質量。
1.應用場景與系統框圖
用戶看到的商品展示界面有詳細的商品參數和質檢報告,商品參數包含商品的基本信息,質檢報告為轉轉質檢部門出具的權威檢測報告,方便用戶了解二手商品的真實狀況。
 商品詳情頁
商品詳情頁
用戶在轉轉App上與客服的談話內容大致可分成:商品參數咨詢,質檢報告咨詢,優惠活動咨詢,平臺政策咨詢,售后咨詢,閑聊問候六大類。人工客服在遇到用戶咨詢商品參數和質檢報告時,需要從種類繁多的商品詳情和質檢項中找到客戶問題相關的項,再給出用戶相應的解答。從用戶點擊商品的全部數據中搜索答案是比較耗時的,需要人工客服對用戶咨詢的商品參數較為了解,以便快速響應用戶的問題。
讓我們利用ChatGPT的自然語言處理與理解能力,輔助人工客服實現從大段的商品詳情和質檢報告中找出用戶感興趣的項,并解答用戶的問題吧。
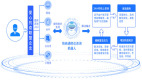
整個智能客服系統的框圖如下圖所示:用戶發起人工咨詢對話,首先分配客服,用戶的點擊商品信息同步給客服,然后智能客服系統給出輔助信息,客服決定采納與否,給用戶提供解答,一次會話結束。
 系統框圖
系統框圖
智能客服系統分為三個模塊:用戶問題分類模塊,知識篩選模塊和ChatGPT智能客服模塊。一期系統只有ChatGPT智能客服模塊,二期和三期優化增加了用戶問題分類模塊和知識篩選模塊。讓我們一起來看看它的創建流程吧。
2.搭建基于ChatGPT的智能客服助手
2.1 ChatGPT原理
ChatGPT為Open AI開發的LLM,GPT的全稱是Generative Pre-Trained Transformer。ChatGPT屬于GPT系列的預訓練語言模型,GPT系列模型包括GPT-1,GPT-2和GPT-3,GPT系列模型的參數量見下表。
模型 | 發布時間 | 層數 | 參數量 |
GPT-1 | 2018-06 | 12 | 1.17億 |
Bert | 2018-10 | 12 | 1.15億 |
GPT-2 | 2019-02 | 48 | 15億 |
GPT-3 | 2020-05 | 96 | 1750億 |
模型規模的指數級擴張,帶來了模型理解能力質的躍升。但是模型的理解并沒有與用戶的意圖做對齊。ChatGPT以GPT-3為基礎,訓練網絡采用了提示學習(Prompt Learning)和人類反饋的強化學習來訓練網絡,使模型可以聽從指令,輸出對人類有用,可信和無害的回答[1-2]。提示學習屬于元學習的一種,通過將任務信息告訴模型,訓練網絡學會學習(learn to learn)。這種方式將NLP各種任務都歸一為文本生成任務。提示學習挖掘模型本身已經學到的知識,指令(Prompt)可以激發模型的補全能力。而基于人類反饋的強化學習,根據人類對預測內容的偏好,訓練了一個獎勵函數,將這個反應人類偏好的獎勵函數作為強化學習的獎勵,通過最近策略優化(proximal policy optimization)訓練網絡策略使獎勵最大。
2.2 Prompt設計
ChatGPT好比一個知識庫,想要從這個知識庫獲取我們需要的知識,需要清晰的指令。通過清晰指令告訴ChatGPT它要完成的工作是什么,以及要完成工作需要的詳細步驟,同時給出一些簡單的示例,可以幫助ChatGPT更好地理解并執行我們的指令。一個標準的指令由以下五部分組成:
(1)任務描述
(2)背景知識注入
(3)輸出格式地約定
(4)舉例說明,包括樣例輸入,樣例輸出
(5)給出輸入數據
這里以轉轉智能客服為例,設計這個場景的Prompt:
現在你的身份是一個電商客服,請根據下面給出的商品信息和質檢信息,回答用戶的問題,回答問題時要根據商品信息和質檢信息相關項給出精簡的答案。商品參數:{$product_info},質檢信息:{$quality_info}。
AI:請問您有什么問題要咨詢的嗎?
user:電池有維修更換嗎?
AI:根據質檢報告電池檢測項,該電池由平臺更換,更換電池品牌為全新海斯電池。
User:電池容量是多大?
整個Prompt可劃分為四部分,第一部分介紹任務,第二部分做知識注入,變量product_info和quality_info分別對應商品詳情和質檢報告,第三部分做任務舉例,第四部分給出用戶問題。LLM具有few-shot學習能力,通過幾個簡單的例子告訴模型期待的答案是什么,可以引導LLM按照我們預期的方式完成任務。此時我們得到的ChatGPT的答復是電池容量為2815mAh。
這里以人工客服采納智能客服建議的接納度來衡量智能客服的服務質量。商品參數咨詢問題的采納度為20%,質檢項咨詢的采納度為6.4%,而閑聊問候和優惠活動這種類型的咨詢更偏好人工客服。基于ChatGPT的智能客服,用戶問題的響應耗時在5-10s,人工客服的響應耗時在30s左右,智能客服的響應速度更快。ChatGPT API的調用按token收費。目前智能客服運行成本0.12元/會話。
3.智能客服系統二期優化之用戶問題分類
不同類型的用戶咨詢,智能客服給出建議的采納度也有較大差異。在商品參數咨詢和質檢項咨詢問題上,智能客服意見的采納度較高,幫助人工客服提高用戶問題的響應速度。而對于閑聊問題等問題,智能客服給出的建議采納度較低。
在ChatGPT智能客服模塊前置一個用戶問題分類模型,將分類結果為商品參數咨詢和質檢報告咨詢的問題送至基于ChatGPT的智能客服系統,進一步降本增效。用戶問題分類模型采用 Bert做文本分類任務。接下來簡要介紹Bert分類在該場景的應用。
3.1 Bert簡介
Bert為2018年谷歌提出的預訓練語言模型[3],模型采用了Transformer的Encode端,基于多頭自注意力機制捕獲句子中的上下文信息。預訓練階段采用完形填空任務和上下句判斷任務訓練網絡。應用于下游任務時,可采用CLS位的特征向量作為句向量,在網絡后接入Linear層進行句子的分類。
 Bert結構圖
Bert結構圖
Bert模型在預訓練階段采用了33億文本語料進行訓練,網絡對自然語言已有基本認知。基于Bert預訓練模型,去微調下游任務,在很多領域都取得了很好的效果。
3.2 用戶問題分類網絡訓練數據
人工標注用戶問題分類的數據耗時較長,這里采用ChatGPT給出用戶問題的分類,作為Bert 微調階段的訓練數據。
設計分類任務的Prompt:
請對用戶問題進行文本分類,需要按照要求將用戶的問題分類到:[ '商品參數咨詢', '質檢報告咨詢','售后咨詢', '平臺政策', '活動優惠', '閑聊問候']類別中。
User:這個手機內存是多大?
AI:商品參數咨詢
User:電池有拆修嗎?
AI:質檢報告咨詢
User:下單后從哪里發貨?
AI:售后咨詢
User:支持7天無理由退貨嗎?
AI:平臺政策
User:你好
AI:閑聊問題
User:謝謝!
AI:閑聊問候
User:待機時長是多久?
3.3訓練分類模型
訓練數據集準備好后,開始微調Bert。網絡的輸入為句子,文本經過分詞器進行分詞后,得到切分好的token序列。Bert輸入token的最大長度不得超過512,對于超長的序列,進行截斷操作。在文本的頭尾加入”[cls]”和”[sep]”后,會進行padding操作,方便網絡進行批量化訓練。根據Bert的字典將處理好的序列映射為對應的id,就可以送入網絡進行訓練。由于自注意力無法捕捉位置信息,Bert在token embedding上疊加了位置embedding。
 Bert輸入組成
Bert輸入組成
接下來定義模型的結構,代碼如下:
Import torch.nn as nn
from transformers import BertModel
class Classifier(nn.Module):
def __init__(self,bert_model_path,num_classes):
super(Classifier,self).__init__()
self.bert = BertModel.from_pretrained(bert_model_path)
self.dropout = nn.Dropout(0.1)
self.fc = nn.Linear(768, num_classes)
def forward(self,tokens,masks):
_, pooled_output = self.bert(tokens, attention_mask=masks,return_dict=False)
x = self.dropout(pooled_output)
x = self.fc(x)
return xBert模型產出的特征維度為768,經過Dropout層隨機mask一定比例的權重,送至Linear層,將特征向量映射到Label空間,num_classes對應了Label空間的維度,這里我們要分類的種類有6類。訓練采用AdamW優化器,學習率為1e-5,訓練了10輪。測試集上準確率76.6%,f1 0.754。商品參數咨詢的f1 0.791,質檢報告咨詢的f1 0.841。
 圖片
圖片
訓練loss與準確率
通過前置的用戶問題分類模型,幫助智能客服系統篩選掉了一些采納度低,適合人工客服回答的問題,智能客服系統響應用戶會話的成本降到了0.033元/會話,運行費用降低了72.5%。
4.智能客服系統三期優化之商詳和質檢項相關知識篩選
搭建智能客服時Prompt包含了商品的全部商品詳情和質檢項信息,并未考慮這些項與用戶問題的相關性。比如用戶問題是電池相關的,做商品詳情和質檢項的知識注入時,可以只注入電池相關的知識。token數量越長,ChatGPT處理所需時間也會越長。通過篩選與用戶問題相關的商詳和質檢項做知識注入,可以進一步壓縮完成一次會話所需token的數量,降低智能客服的運行成本的同時,也提升智能客服的響應速度。
Bert計算兩個句子相似度時,把兩個句子同時輸入Bert,進行信息交互,計算速度是比較慢的,無法事先計算好句向量,語義搜索時比較慢。Sentence-Bert借鑒了孿生網絡的框架,將兩個句子送入兩個Bert模型中,這兩個模型的參數是共享的,網絡結構[4]如下圖所示。Bert網絡輸出每個token的embedding向量,通過pooling策略生成句向量的表征。論文中分別用"[CLS]"位,平均池化,最大池化生成句向量的表征,實驗表明pooling策略采用平均方式效果最好。得到的句向量計算兩者的余弦相似性,用來衡量這兩個句子的相似度。
 SBert結構圖
SBert結構圖
假設用戶問客服“電池具體多少?”,客服拿到的用戶點擊商品的詳情:95新 iPhone 12 128G 紫色 移動5G 聯通5G 電信5G 國行;網絡制式:全網通;購買渠道:國行;保修情況:過保或小于30天;電池健康值:85%-90%;系統版本:iOS 16.5.1;充電次數:562;SIM卡:支持雙卡;來源:二手優品;IMEI:352***833;履約服務信息:真的官方驗、7天無理由、一年平臺質保、順豐包郵、手機服務權益卡、寄存于長沙流轉中心,現在下單預計8月17日送達;CPU型號:蘋果 A14;電池容量:2815mAh;CPU主頻:3.0GHz;解鎖方式:面部識別;是否支持快充:支持;充電峰值功率:20W;分辨率:2532*1170;屏幕尺寸:6.1英寸;主屏材質:OLED;上市時間:2020-10;操作系統:iOS;屏幕類型:全面屏;后置攝像頭:1200萬像素+1200萬像素;前置攝像頭:1200萬像素;攝像頭總數:三攝像頭(后二);機身重量:162g;機身尺寸:146.7*71.5*7.4mm;機身類型:直板。
客服拿到的用戶點擊商品的質檢報告樣例(省略部分質檢項):外殼外觀的情況-碎裂:無;外殼外觀的情況-劃痕:無;外殼外觀的情況-磨損:無;外殼外觀的情況-變形:無;外殼外觀的情況-脫膠/縫隙:無;外殼外觀的情況-外殼/其他:正常;外殼外觀的情況-刻字/圖:無;外殼外觀的情況-磕碰/掉漆:無;攝像頭外觀的情況-閃光燈:正常;攝像頭外觀的情況-前置攝像頭:正常;拆修浸液的情況-主板:無維修;拆修浸液的情況-機身:無維修更換;拆修浸液的情況-零件維修/更換:無維修更換;拆修浸液的情況-零件缺失:無缺失;拆修浸液的情況-浸液痕跡:無浸液痕跡;充電的情況-無線充電:正常;充電的情況-有線充電:正常;電池檢測的情況-電池:無維修更換;包裝及配件的情況-包裝盒:1;包裝及配件的情況-數據線:無;包裝及配件的情況-充電器:無。
可以看到商品詳情和質檢項里只有少數項與用戶問題相關,全部商詳和質檢項做知識注入會浪費很多token,導致ChatGPT需要在很長的序列里找相關信息回答用戶問題,響應速度較慢,效率不高。這里通過Sentence-Bert計算用戶問題和商詳、質檢項的句向量,根據余弦相似性挑選出最相關的top5商詳和質檢項做知識的注入,ChatGPT基于該商品電池相關的知識給出用戶響應。Top5商詳如下:電池容量:2815mAh,電池健康值:85%-90%,充電次數:562,充電峰值功率:20W,機身尺寸:146.771.57.4mm,top5質檢項如下:充電的情況-有線充電:正常,電池檢測的情況-電池:無維修更換,充電的情況-無線充電:正常,按鍵的情況-電源鍵:正常,包裝及配件的情況-充電器:無。此時ChatGPT智能客服給出的響應為“電池容量為2815mAh”。原始知識注入token數為1228,經過相關知識篩選,token數降為132,token數下降了89%。
 知識篩選
知識篩選
5.總結
LLM具有的出色自然語言理解能力可以為各行各業賦能。傳統人工客服領域具有高度依賴人工,數據密集等特點,大量未被充分處理的數據為LLM在這個場景落地提供了沃土。這里基于ChatGPT搭建的智能客服系統已上線,助力客服提高服務質量與服務效能。
6.參考文獻
[1] Ouyang L , Wu J , Jiang X ,et al.Training language models to follow instructions with human feedback[J].arXiv e-prints, 2022.DOI:10.48550/arXiv.2203.02155.
[2] Brown T B , Mann B , Ryder N ,et al.Language Models are Few-Shot Learners[J]. 2020.DOI:10.48550/arXiv.2005.14165.
[3] Devlin J , Chang M W , Lee K ,et al.BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding[J]. 2018.DOI:10.48550/arXiv.1810.04805.
[4] Reimers N , Gurevych I .Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks[J]. 2019.DOI:10.18653/v1/D19-1410.
關于作者
王安,資深NLP算法專家,負責搜索場景的用戶意圖理解,基于ChatGPT的智能客服的落地,在文本分類,實體識別,關系配對,問答場景有豐富落地經驗。微信號:tiantian_375699720,歡迎建設性交流。