建立屬于你的智能客服
背景
很多人問,對話式交互系統就是語音交互么?當然不是。語音交互本身真的算不上新概念,大家可能都給銀行打過電話,“普通話服務請按1,英文服務請按2……返回上一層請按0” 這也算對話式交互系統,我想大家都清楚這種交互帶來的用戶體驗有多低效。那么對話式交互系統已經可以取代人類提供服務了么?也沒有,圖靈測試還沒有過呢,著什么急啊。
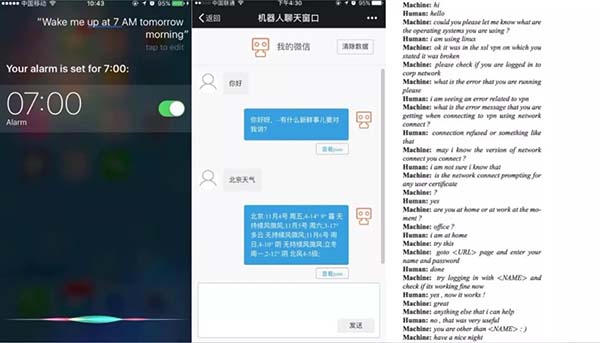
不過,隨著人工智能的發展,對話式交互穿著語音和文本的外衣,攜手模糊搜索引擎,懷抱計算科學和語言學的內核,帶著定制化推薦的花環,駕著深度學習和大數據的馬車乘風破浪而來——我們就知道,大約是時候了。至少,我們已經可以在十分鐘內創造自己的對話式客服了。
今天的文章大致分為三部分:歷史,今天(chatbot api)和未來(深度學習和智能問答)。
先定義一下交互系統,wiki給出的定義是:
| Interaction is a kind of action that occurs as two or more objects have an effect upon one another. |
即雙方或者多方相互影響的過程,那么在咱們的上下文中,我們不妨限定為人機交互。先來講講是什么,再來講講怎么做吧。
歷史和現在
廣義上的對話式交互實際上包括所有一問一答形式的人機交互,自始至終,我們都需要從機器拿到信息。在最早的時代用的是文本交互系統TUI,其實直到今天,我相信程序員們在Linux下面完成大部分操作時還是會選用Terminal,這種文本交互非常簡潔高效,但是有一個缺點:不熟悉操作的人上手非常困難,需要記住大量的指令和規則,才可以有效的告訴機器想要它做什么——正如一個笑話:“問:如何生成一個隨機的字符串? 答:讓新手退出VIM”。
直觀的,既然“以機器的交流方式告訴機器想要做什么”這件事情給人類帶來了很差的用戶體驗,那我們可以讓機器提供可能的選項來讓人類選擇。所以,人類用了幾十年,把交互系統升級成了圖形化交互GUI。大家今天看到的桌面系統就是特別典型的一個體現。包括后來的觸摸屏幕和智能手機的發展,其實都是圖形化交互的不同表現。

現在一切都好了么?并沒有。雖然機器可以在瞬間呈現大量的信息,但是人類在同一時刻可注意到的信息卻極為有限。心理學研究發現,人類的注意廣度其實只有5-9個對象。想象一下上面那張圖,如果我在桌面上放100個應用程序呢?1000個呢?隨著數據量的發展。如何在大量的信息中,迅速呈現出有效的信息呢?
搜索系統,或者再具體一點——推薦系統,在選項過多的時候,承擔起了給用戶盡可能高效率的提供想要的信息的任務。如果我們做好了智能搜索,我們就能做好智能交互。本質上都是一樣的:在浩瀚的已知數據里,基于一定模型和經驗,總結出用戶最想要的答案并及時的呈現出來。我問Google一個問題,Google將我想要的答案排在***個位置返回給我,誰又能說這不是對話式交互呢?
當然,我們希望的對話式UI不僅是一問一答,我們希望對話系統能夠有自己的知識數據庫,希望它保有對上下文的記憶和理解,希望它具有邏輯推演能力,甚至,頗有爭議的,希望它具有一定的感情色彩。
所以,我們有了今天的Conversational UI,對話式交互只是一個殼子。其中的本質是智能和定制化服務,在一段時間的訓練之后,你拿起電話撥給銀行,應答的智能客服和人類的交互方式是一樣的。拋開繁瑣的從1按到9的決策路徑,直接告訴他你要做什么,銀行會直接給你提供***你需求的服務。而完成這個任務,我們主要有兩條路可以走,一條是專家系統,這里也會給大家介紹幾個網絡上的引擎,爭取在十分鐘之內讓大家學會建立一個屬于自己的智能客服系統。而另外一條,則是智能問答系統,需要一點機器學習和深度學習的知識——教機器理解規則,比教機器規則,要有趣的多。
輸入和輸出
前面都在講輸入,就是機器如何理解人類的指令。是因為輸出這個問題,可以說已經被解決了很久了。文本、圖像和語音三大交流方式中,語音被解決的最晚,但是20年前的技術就已經足夠和人類進行交流了,雖然我們還是能很容易的聽出來語料是不是電子合成的,但是這一點音色上的損失并不影響我們交流的目的。
而語音到文本的識別便要復雜得多。這類工作確切來說始于1952年。從讀識數字從1到0,然后把數字的聲音譜線打出來,識別說的是哪個數字開始。這個模型雖然達到了98%的精度,但是其實并不具有通用性:數據源空間和目標空間都實在是太小了。
我們都知道當下***或者說***用的語音識別模型是深度學習模型。但是在此之前呢?舉一個典型例子:開復老師的博士論文,隱馬爾科夫模型,大約三十年前發表,如下圖所示:

簡單說就是一個時間序列模型。有時間狀態,隱藏狀態,然后有觀測狀態。比如我有兩個色子,一個六面體色子,從1到6。一個四面體的,從1到4。兩個色子之間進行轉換的概率都是0.5。現在給出一段極端一點的序列 111122224441111555566666666,大家覺得哪一段是四面體色子、哪一段是六面體色子呢?同理,聽到一個語音,我想知道后面隱藏起來的那句話,原理也是和扔色子一樣的:根據觀測到的狀態(聲音)來推理后面隱藏的狀態(文本)。這類概率模型的效果相當不錯,以至于今天還有許多人在用。
Chatbot API
按照人工干預的多少,推理引擎的實現大致可以分為兩類。一類是人工定義規則,一類是機器從數據里面自動學習規則。對于前者,我們都知道wit.ai和api.ai這兩個著名的chatbot開放api, 分屬于Facebook和Google兩大巨頭。先來看一下實現的效果:

這里的+表示得分,機器準確的理解了人類的意圖。o表示不得分,機器并沒有理解。我們可以看到,其實表現并沒有想象中的那么好,一些很簡單的案例‘i would like to order pizza’ 都沒有得分,離普通人類的智能還有些距離。
那么背后的邏輯是怎樣的呢?舉一個api.ai的例子,我們會定義不同的類型和變量,然后把他們和相關的值與回答鏈接起來。從而在和用戶進行交互的時候,能夠按照已知的(人類定義的)規則來存儲相應的值,并調用相應的方法。
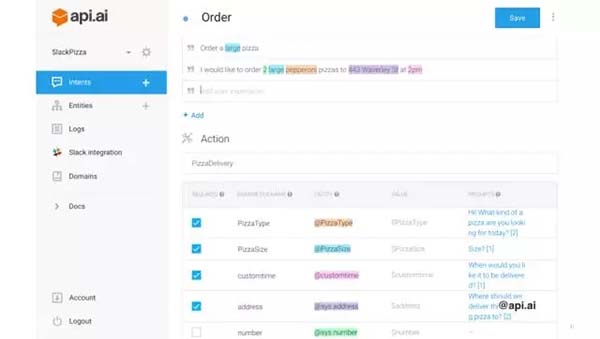
可能大家會覺得英文讀起來比較慢,這里介紹一個中文版api.ai——yige.ai. 并不是廣告,我了解這個平臺還得益于我的朋友——有一天他跑來跟我說:夭壽啦!你知道嗎,有個相親網站,拿人工智能代替女性用戶和人聊天!之后,官方辟謠說并不會這么做。但是yige.ai在新手入門方面的友善程度,實在是我見過中文chatbot API中數一數二好的。
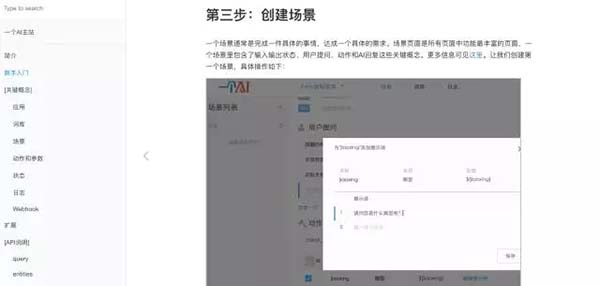
但是也正如圖中所示,我們依舊需要人工定義很多事情包括詞庫,場景,規則,動作,參數等等。在買鞋這樣一個小的場景和確定范圍的交互期待里面,這樣做還是可以為大部分人群所接受的。畢竟簡單而直觀,精準的實現了“十分鐘制作屬于自己的chatbot”這一需求,更不需要強大的計算資源和數據量。但我們并不太可能在這樣的系統里面,得到定義好的域以外的知識。如果我們的時間和人力足夠多的話,能夠有專門的一些領域專家來完善這個提問庫,將會使得搜索的精度非常高。因為所有可能的提問都已經有了專業的答案。但是,當場景復雜之后,這樣做的工作量就會變成很大的壓力了。
所以,我們需要深度學習。
深度學習想要達到一個好的表現,需要有兩個前提。一個是足量的計算資源,一個是大量的數據。
計算資源不用說,如果沒有GPU,圖片/語音這種非結構化的原始數據訓練的時間基本需要以“周”來作單位。
數據集設計
關于大數據,一個很常見的問題就是,多大才算大,學術一點的說法是:大到包含區分目標值所需要的所有特征就可以了——我們都知道在實踐中,這句話基本屬于廢話。那么舉個例子,一般來說訓練一個語音識別的模型,數據是以千小時為單位計算的。
而且很抱歉的是,很多商業公司的數據集基本是不公開的。那么對于小型的創業公司和自由研究者,數據從哪里來呢?筆者整理了一些可以用來做自然語言處理和智能問答的公開數據集,這里由于篇幅和主題所限,就不展開講了。改天會專門開主題介紹免費可用的公開數據,以及在公開數據集上所得到的模型應該如何遷移到自己的問題域當中來。
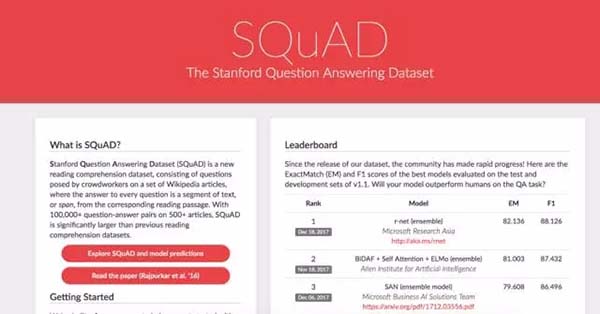
這里用斯坦福大學的著名問答數據集作為例子,SQuAD,可以被稱為業內用于衡量問答系統的最棒最典型的數據集。我們可能在高中時代都做過閱讀理解,一篇文章帶有幾個問題,答案來自于文章的信息。那么有了這樣一個數據集,我們能做的事情是什么呢?這樣一個數據集所訓練出的模型可以解決什么樣的問題?在各個問題中,人類的表現和機器的表現有什么樣的差異?為什么?
我們很高興的看到,在***發表的一篇基于r-net的論文中,機器的表現已經可以和人類媲美了。人類在這個數據集所得到的EM得分約82.3,F1得分約91.2。而微軟發表的框架EM得分高達82.1,和人類相差不足0.2%。
深度學習
好的,現在數據有了,計算資源有了,模型從哪里來呢?我們很高興的看到算法正在進化,人工的干預隨著技術的進步越來越少。在DeepMind于2017年12月5日發表的***版本中,AlphaZero沒有用到任何人工的特征就打敗了用了一堆特征的前任AlphaGo,也打敗了人類歷經千年沉淀下來的珍瓏棋譜。
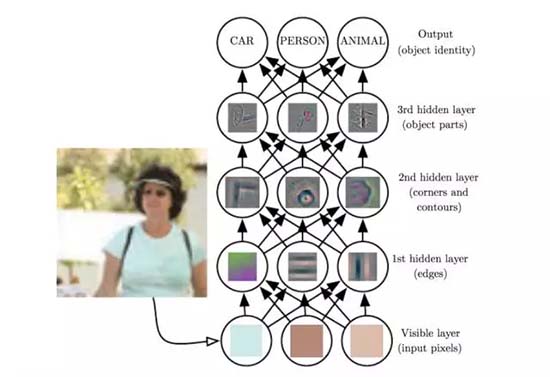
直觀一點,在圖像識別的深度網絡中,計算機難以理解原始圖像像素值的含義,然而神經網絡每層的權重實際上學習到了圖像的高級特征。越高層的神經網絡,成分越具體。***層可以通過比較像素的亮度來識別邊緣,基于此,第二層可以檢測邊角的集合,第三層可能是小的色泡或者面,第四層可能是嘴巴這類更復雜的對象,再往下可能是更具體的特征,直到物體本身。 神經網絡和人腦一樣,將原始信號經過逐層的處理,最終從部分到整體抽象為我們感知的物體。圖中所示的是一個從圖像到物體的感知過程,或者說是一個圖像到標簽列表的映射模型。
語音轉文本或者問題到答案,也是一樣的,可以用sequence2sequence作為學習的模型設計。前面說到的api.ai也好,yige.ai也好,規則和變量都是傾向于人工定義的。機器會對未經定義的語法規則給出一些通用的支持,但是正如我們看到的,一旦遇到定義域之外的交互場景,表現就很難盡如人意。
而在端到端的識別中,我們不關心所有的語法和語義規則,所有的輸入直接定向為問題,所有的輸出直接是答案。當數據足夠多,我們就可以做到端到端的識別,而不受人工定義的語義規則的干擾。這件事情,既是好事情,也是壞事情。基于人工規則的機器永遠都不可能超過人類的表現,但是純基于數據的機器學習模型,卻可以打敗人類——這點在AlphaGo的所向披靡之中,已經被證實過了。
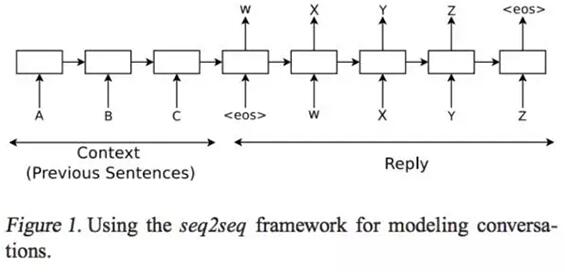
如同圖示,seq2seq的模型可以基于Sutskever在2014年發表于NIPS的一篇文章設計 ,模型用recurrent neural network每次讀入一個token作為輸入,并預測應答的token。我們假設***個人說了ABC,而第二個人回答了WXYZ,那么模型將會建立一個從ABC到WXYZ的映射。模型的隱變量,我們可以叫他“thought vector”,表明在這里機器理解了這個ABC的想法,或者說概念。這個模型在簡化程度和通用程度上都是極好的,后面的實驗也證明了這一點。
下圖是LSTM(一種神經網絡)所產生的翻譯結果樣例,大家可以參考一下效果,并和百度翻譯以及谷歌翻譯對比一下。
所產生的翻譯結果樣例")
深度學習Chatbot開源實現
相信通過前面的介紹,大家對于對話式交互系統,以及現有的api都有了初步了解,那么對于剩下一部分想要自己實現模型的人們,感謝github和arxiv,我們在源代碼和原理級別都可以知道當今最聰明的那批人在做什么。
這里是一個頗具代表性的開源框架,純基于seq2seq,由機器學習實現,并沒有任何人工規則干預。
和Google一直以來的風格相符,整個代碼都是在TensorFlow和python3.5上實現,支持各種開源數據庫以及定制化對話數據庫,甚至擁有本地的web界面。有現成的權重文件可以下載(無需自己耗時訓練),通過 TensorBoard我們也可以輕松監測系統的表現,雖然在部分對話的表現上差強人意,有著諸如在上下文中對同一個問題的回答不統一這種明顯的bug,離通過圖靈測試更是很遙遠,但是其設計原理和實現方式對入門者實在是再友好不過。至少,這個模型告訴了我們,深度學習模型是可以自動從有噪聲的開放領域內提取相應知識,并全自動生成答案的。
總結與展望
總結一下,如果我們有更多的領域專家和業務分析師,并且業務上需要進行對話式交互設計的場景相對有限,變量關系都比較簡單,那么毫無疑問,各式各樣的chatbot API將會是你***的選擇——它設計直觀,接口簡單,集成容易,而且大多數時候,它在特定問題下的精度將會比端到端的深度學習要高。如果我們有更多的數據科學家和大數據工程師,對和機器一起學習數據中的規則有很大的興趣,同時業務場景又比較復雜,需要支持更多非結構化的原始數據以及自動化提取特征和規則,那么建議大家借勢深度學習,搭建屬于自己的智能問答系統。
【本文是51CTO專欄作者“ThoughtWorks”的原創稿件,微信公眾號:思特沃克,轉載請聯系原作者】