千億級數據防丟指南:存儲系統的可靠性保障實踐
一、溯源——vivo存儲服務介紹
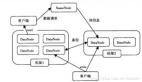
1.產品矩陣
 圖片
圖片
當前我們的團隊主要負責兩大板塊內容,一是存儲和數據庫產品矩陣,二是周邊工具及接收類服務。
這兩部分內容的區別主要是,周邊工具和接入類服務幾乎是無狀態的,用戶對這類服務提出可用性的需求,比如我們平時接觸到的SLA;而存儲及數據庫產品等引擎,主要面向對象存儲、文件存儲、表格存儲等專門的服務業務,包括可用性和可靠性的指標。
2.存儲框架
云存儲領域的黃金數字是11個9,接下來就以存儲服務為切入點,向大家介紹11個9能否量化?如何量化?
 圖片
圖片
如上圖所示,存儲框架的核心思路是以自研的存儲引擎為核心,輔以阿里、騰訊等公有云的存儲,獲得統一的存儲底座,在上方形成對應存儲的統一網關,進而提供一套混合云的存儲系統。然后,存儲系統進行協議轉換、衍生產品開發,為業務提供存儲服務和衍生的生態服務。
比如,我們會利用自己的SDK和AWS S3 SDK,提供原生的對應重組產品,向前封裝文件的存儲網關,兼容posix協議,為用戶提供文件的存儲產品。除此之外,還會封裝企業網盤,進行專項服務,為用戶提供相應的衍生產品。
3.運營數據
當前,基于跨機房的糾刪碼相關優化,對可靠性提出了挑戰。如下圖所示,我們線上的集群容量達到400億(此數據尚未包括Hadoop的數據容量),存儲數量已超1,000億。
 圖片
圖片
二、歸因:存儲可靠性原因分析
1.數據丟失影響因素
 圖片
圖片
數據丟失的五大原因包括:軟件故障、數據損壞、惡意竊取、人為失誤、硬件故障,其中硬件故障的占比較高。
2.軟件故障和數據損壞
 圖片
圖片
軟件故障的主要原因是軟件設計不規范、測試不完善及運維發布的操作爆炸半徑太高。
這些問題的通用解決方案是:
- 設計標準規范化,比如,AWS引入了TLA+、Plusal等形式化規范語言來設計系統;
- 要達到測試自動化;
- 做好版本向前版本兼容、版本回滾、讀寫分離等操作。
數據損壞的行業通用解決方案相對成熟,因為在處理傳輸與存儲的過程中,都有一定概率遇到數據損壞的問題。
解決方案:
- 通過HTTPS協議,保證傳輸的安全;
- 然后通過MD5校驗,記錄交易數據的完整性;
- 最后通過定期的scrubbing處理機制,快速掃描是否具有靜默錯誤。
3.惡意竊取和人為失誤
 圖片
圖片
人為失誤主要包括兩類問題,第一類是運維人員操作失誤,第二類是用戶自己的誤殺或誤覆蓋。
- 針對運維的解決方案:運維自動化、運維白屏化、遵循POLP的最小權限原則。
- 針對用戶的解決方案:自動存儲方面,可以利用多版本的特性,保證用戶可以找回誤刪的這種數據;文件方面,提供回收站功能可以達到相同效果。
惡意竊取主要是內外部人員相關竊取或刪除數據,其解決方案包括:
- 進行權限控制和生命周期管控;
- 可以鎖定對象粒度為只讀模式;
- 針對刪除操作,可以提供這種多因素的、健全的雙因子論證,管控刪除操作。
4.硬件故障
硬件故障是需要重點關注的存儲可靠性原因,因為它占比較高,樣本量比較大,所以有一定概率進行量化。
1)原因
- 硬盤故障:最常見最重要的,驅動器、磁頭、溫度、機械臂故障
- 主機故障:服務器各部件故障導致服務器無法啟動
- 機柜故障:由于電源、溫度、網絡等原因導致整機柜服務器停機
- 機房故障:整個機房由于自然災害或供電原因癱瘓
- AZ故障:同一地理區域獨立電力和網絡的機房故障
- Region故障:不同地理區域的一個Region故障
2)硬件故障的解決方案
- 數據冗余技術【RAID5/6、副本、糾刪碼】
- 多AZ數據冗余部署【vivo 3 AZ 部署】
- 跨區域復制功能【功能具備,vivo還沒多地域機房】
- 故障預測+故障發現+故障修復
如果我們只按照傳統方式,增加K,減少M,修復帶寬就會非常高。并且,多AZ之間的修復帶寬本身成本較高,所以給可靠性帶來了很大壓力。因此,我們設計了一個低冗余度、支持多AZ部署、且修復帶寬較少的糾刪碼優化方案。
 圖片
圖片
上方右圖來自2021年亞馬遜AWS S3關于可靠性保障的演講,這幅圖提供了兩個重要的信息。
- 第一個信息:11個9是通過可靠性模型量化得到的,它與磁盤的故障率、故障發現的時間和消費時長是強相關的。
- 第二個信息:可靠性評估模型,用于指導線上環境的修復策略,以及指導跨AZ糾刪碼技術存儲系統的設計。
三、建模:存儲可靠性量化模型
1.11個9的由來
11個9是亞馬遜在2006年提出的可靠性標準,所有云存儲提供商都像軍備競賽一樣,聲稱自己能提供多少個9,但行業內幾乎沒有任何一家云廠商能提供權威的量化模型。
這11個9如何量化?
 圖片
圖片
亞馬遜的官方文檔提供了兩種定義:
- 第一個定義是,存儲一千萬個對象預期平均每1萬年發生一個對象丟失。這個定義很好理解,但它實際上并不好量化;
- 第二個定義是,平均每年對象的丟失率預計為0.000000001%。這個定義具體到每年的對象丟失率,進入到統計學概率的層面,為量化提供可能。
回顧那張AWS演講里的圖,它引入了兩個比較重要的參考指標:硬件的平均故障時間、故障的平均修復時長,對應到年平均指標的層面上,就是年平均故障率和年平均修復率。
2.可靠性模型影響因素
接下來,介紹建立模型的具體影響因素。如下圖所示,如果第一個磁盤爆炸,后面磁盤的數據需要對它進行修復,這個過程可能涉及到修復帶寬,所以修復帶寬的大小一定會對可靠性產生影響。這個磁盤本身的數據量、系統節點數目也影響了修復時間,這三個指標實際上影響了修復率的值。
 圖片
圖片
副本的數量、磁盤故障率對可靠性也是有影響的,這比較好理解,如何理解數據分布系數對可靠性的影響?
如上圖左下角所示,備份有兩種數據分布方式。在第一種備份的數據分布狀況下,如果第一個磁盤掛了,只能依靠第二個磁盤進行修復,即只有一個盤進行修復,所以速度較慢。
第二種備份將數據分塊打散,其他三個磁盤都存儲一部分數據。第一個磁盤掛掉后,就有多個磁盤并行修復,速度會更快。
這是不是說明第二種備份方式就是最好的?也不一定。因為第一種備份雖然修復速度慢,但正好修復了掛掉的數據。用第二種備份方式,修復的數據可能不是掛掉的數據,實際存在數據丟失情況,因此,數據分布系數對可靠性也有影響。
3.MTTDL可靠性模型
 圖片
圖片
以下介紹幾個重要的存儲可靠性量化模型。第一個是MTTDL(平均系統數據丟失時間),它和磁盤的MTTF的區別在于,MTTDL用于衡量系統平均數據丟失時間。
MTTDL模型在1994年被提出,1.0版本基于Markov鏈推導而來,上圖列出了一個簡化版的計算公式。相對于1.0版本,最近幾年出現的MTTDL的2.0版本,引入了剛才講到的數據分布系數。
MTTDL有幾個缺點:第一個缺點是,它基于Markov鏈的方式;第二個缺點是,基于當前整個系統的故障平均時間,它是服從指數分布的。
另外,前期的MTTDL模型沒有考慮扇區錯誤,所以近期的MTTDL優化版本屏蔽了Markov鏈的劣勢,不使用這種方式建模;將指數分布優化成,故障率可以動態調整的Weibull分布;考慮獨立扇區、相關性扇區的錯誤;考慮修復時長等NORMAL指標。
MTTDL模型對不同系統設計的可靠性進行優劣評估,起到了非常大的作用。
4.EAFDL可靠性模型
 圖片
圖片
MTTDL的定義是,平均系統的丟失數據的時長。它有兩個特點:第一,MTTDL越高,丟數據頻率越低;第二,它只關注丟失的頻率,不關注每次丟失數據的數量。
EAFDL的定義是,預期每年數據的丟失比例。EAFDL的定義更接近11個9的定義,因為11個9的定義是平均每年對象的丟失率,所以EAFDL會比MTTDL會更貼近11個9的計算。
EAFDL的計算公式如上圖,它在MTTDL的基礎上,引入了丟失的平均數據量,它在mtdl的基礎之上,引入了丟失平均數據量在用戶總數的占比。
但在真實的場景下,EAFDL模型不一定會比MTTDL模型更好。
例如,Facebook曾經公開了一篇論文,講到在大規模idc部署的情況之下,他們更傾向于控制丟失的頻率,而非丟失事件的數據量。因為每次因為丟失事件都會產生固定成本,而固定成本的影響較大。所以真實情況下,EAFDL模型不能完全替代MTTDL模型。
如果側重丟失的頻率,那么在平時系統設計時,可以不斷提高MTTDL。如果大家設計的MTTDL都差不多,下一步才會考慮是否應該讓EAFDL最小化。
如果側重丟失的數量,在系統測試時,可以不斷讓EAFDL最小化,同時讓MTTDL最大化。
四、實踐:存儲可靠性評估實踐
1.vivo可靠性建模思路
 圖片
圖片
我們的建模思路對上述模型進行取舍,取的是什么?我們將MTTDL的頻率維度、EAFDL的丟失量維度和數據分布系數,納入到建模思路。
舍的是什么?我們屏蔽了MTTDL的指數分布、扇區錯誤的建模,舍去了Markov鏈的建模。
2.vivo可靠型模型
 圖片
圖片
上圖是整體建模的參數引入,和之前的參數是類似的。
區別在于,平時磁盤硬件廠商對外報AFR參數有兩個指標:一個是MTBF,一個是AFR,我們將AFR引入到建模。同時,我們也參照了一家云端廠商Backblaze的公開模型介紹,他們利用泊松分布,模擬年度硬盤故障數量的分布。基于這兩個角色,我們制作了副本和糾刪碼的可靠性模型。
 圖片
圖片
建模同時,我們也使用了EAFDL的模型,并引入了丟失的數據量在整個用戶數據量的占比。
上圖右下角的表格,是我們基于副本模式進行的實驗數據。實驗目的主要是,充分驗證不同建模參數對可靠性的影響,進而得出結論。部分結論可以從原理層面推斷,比如,AFR越小,可靠性越高;存儲利用率低,可靠性越高;修復帶寬越高,可靠性越高;副本和檢驗位數越高,可靠性越高。
但是,機器數量越多,它的可靠性不一定越高;數據分布因子越大,可靠性會降低,需要我們在整個系統中進行權衡。
3.可靠性評估平臺化建設
 圖片
圖片
評估平臺的建設基于兩個原則:第一,需要評估新老方案的可靠性優劣;第二,需要近實時地評估線上系統可靠性的風險。
五、思考:存儲可靠性評估思考
1.方向思考
 圖片
圖片
我們有兩個呼吁:
- 共享數據:現在各大提供分布式存儲的廠商之所以沒公開相關可靠性計算模型,是因為統計樣本數據不足。如果全行業能夠分享各自的部分統計數據,樣本量足夠大,就有希望建設最真實的評估模型。
- 統一標準:云存儲領域相關的牽頭企業,基于公司內部的海量樣本數據,能夠分享一個比較權威的考勤評估模型,為業界提供指引。
IliasIliadis的論文非常有價值,他從2000年左右開始,在CTRQ發表眾多關于云存儲系統的可靠性模型研究。大家如果感興趣,可以搜索看看。
2.未來規劃
未來,我們可能會引入扇區錯誤因素,重新建模。
當前沒有引入扇區錯誤,是因為目前業界提供的均值指標,權威性還有待考證。扇區錯誤是磁盤里比較常見的錯誤,不一定是獨立的,可能具有相關性。所以后續等相應指標的真實性足夠后,我們會考慮進行重新監管。
- 軟件故障:自動化測試框架
- 數據損壞:自適應Data-scrubbing
- 惡意竊取:MFA-Delete特性
- 人為失誤:運維自動化率進一步提升、遵循POLP
- 硬件故障:進一步提升故障預測+故障檢測+故障修復能力,進一步設計糾刪碼方案使得可靠性+成本兼顧
Q&A
Q1:您覺得提升可靠性的工作中,近期哪一部分改進的影響最大?
A1:近期我們建立了可靠性模型,為什么要建模?因為我們目前在進行糾刪碼的相關優化,如果糾刪碼的冗余度偏低,就無法保證可靠性,所以我們建立了一套模型去評估。
當然這個模型本身的量級不一定能達到11個9,但相對于線上這套系統,它可以看出好還是壞。建立這個模型,方便我們后續算法優化時進行參考。如果你的算法比較極端,比如下降的量級比較大,可能就要推翻算法,重新設計。
作者介紹
龔兵,vivo云存儲研發負責人。工作10余年,先后就職于華為、騰訊、百度,現在vivo擔任云存儲研發負責人,研究方向:對象存儲、文件存儲、NOSQL存儲等分布式存儲領域。