面試基操:MQ怎么保障消息可靠性?

大家好,歡迎來到Tlog4J課堂,我是Jensen。
面試官:在MQ的整個消息生產消費過程中,如何保障消息100%被消費?
候選人:MQ有個ACK機制,確保消息100%被消費。
面試官:好吧,可以回去等通知了……
這道面試題在考察MQ組件時算是老生常談了,不知道你是如何回答的?
我們平時都在使用MQ,但使用技術框架只是第一步,去弄明白它的底層原理、深挖技術真相,才是每一位IT從業者的基操。
這里說明一點,想要回答好面試官的問題,最好還是要有金字塔思維——金字塔思維就是從不同維度上來思考問題的一種方式,不重不漏,集體窮盡。
MQ作為異步通訊的消息中間件,其功能除了解耦生產者與消費者,還能用于大流量的削峰填谷,解決業務的最終一致性問題,那么消息的“可靠性”就顯得尤為重要了,比如說商品出庫后的庫存數據通過MQ同步到財務系統,如果消息的可靠性沒有保障,那財務系統的存貨成本分析數據就無法有效支撐財務團隊。
準確來說,我們需要保障MQ消息的可靠性,需要從三個層面/維度解決:生產者100%投遞、MQ持久化、消費者100%消費,這里的100%消費指的是消息不少消費,也不多消費。
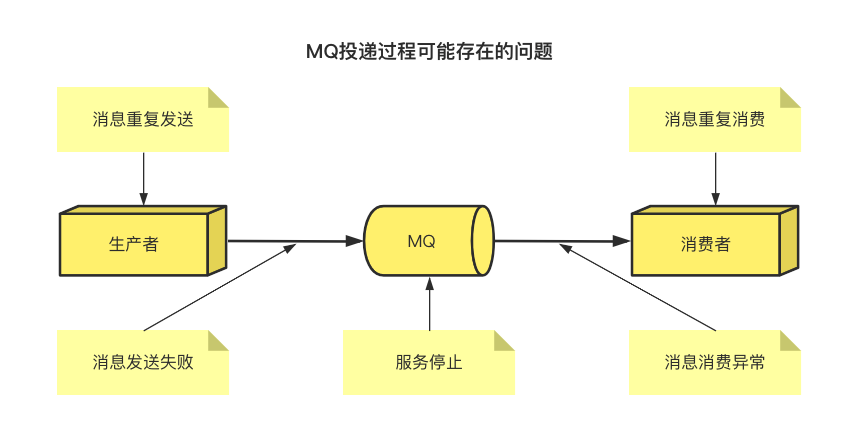
由于MQ是基礎網絡通訊的中間件,網絡通訊必然因丟包、網絡抖動等原因產生數據丟失,MQ組件本身也會由于宕機或軟件崩潰而中止服務,從而造成數據丟失,那么我們就需要從這兩個根本原因著手補償,這里科普一下RabbitMQ和Kafka是怎么解決的。
RabbitMQ
這里我必須先提一提RabbitMQ的消息協議——AMQP(Advanced Message Queuing Protocol,高級消息隊列協議),在面試時我經常問候選人一個問題:RabbitMQ用的是什么消息協議?大部分候選人是回答不出來AMQP的,更不用說AMQP模型是如何設計的了。
在服務器中,三個主要功能模塊連接成一個處理鏈完成預期的功能:
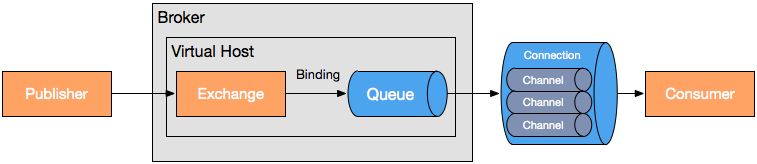
- Exchange:接收發布應用程序發送的消息,并根據一定的規則將這些消息路由到消息隊列。
- Queue:存儲消息,直到這些消息被消費者安全處理完為止。
- Binding:定義了exchange和queue之間的關聯,提供路由規則。
使用這個模型我們可以很容易地模擬出存儲轉發隊列和主題訂閱這些典型的消息中間件概念。
接下來我們看看RabbitMQ的消息確認機制是如何保障消息可靠性的。
一、生產者端
- 通過API將信道(channel)設置為confirm模式,則每條消息會被分配一個唯—ID。
- 如果消息投遞成功,也就是說消息已經到達broker了,信道會發送ack給生產者,回調ConfirmCallback接口,帶上唯一ID。
- 如果發生錯誤導致消息丟失,比如通過某個RoutingKey無法路由到某個Queue,則會發送nack給生產者,回調ReturnCallback接口,并帶上唯一ID和異常信息。
- ack和nack只有一個被觸發,只觸發一次,而且是異步執行,意味著生產者不需要等待,可以繼續發送新消息。
二、消費者端
- 聲明隊列時,指定noack=false, 表示消費者不會自動提交ack,broker會等待消費者手動返回ack、才會刪除消息,否則立刻刪除。
- broker的ack沒有超時機制,只會判斷鏈接是否斷開,如果斷開了(比如消費者處理消息過程中宕機),消息會被重新發送,所以消費者要做好消息冪等性處理。
三、MQ本身
通常來說,消息是在內存中存儲通訊的,而基于內存的都是會有數據丟失的問題產生,服務一重啟,數據就隨之銷毀。
在RabbitMQ中對數據的持久化有三方面:交換機持久化、隊列持久化、消息持久化。
- 交換機持久化:exchange_declare創建交換機時通過參數durable=true指定,如:channel.exchangeDeclare(exchangeName, “direct/topic/header/fanout”, true);第三個參數就是設置durable值。
- 隊列持久化:queue_declare創建隊列時通過參數durable=true指定,如:channel.queueDeclare("queue.persistent.name", true, false, false, null),第二個參數就是設置durable值。
- 消息持久化:new AMPQMessage創建消息時通過參數指定,如:channel.basicPublish("exchange.persistent", "persistent", MessageProperties.PERSISTENT_TEXT_PLAIN, "persistent_test_message".getBytes()),或者設置參數deliveryMode=2來指定:AMQP.BasicProperties.Builder builder = new AMQP.BasicProperties.Builder();builder.deliveryMode(2)。
上面只是說了API層的實現,那RabbitMQ底層又是怎么做消息持久化的呢?
如果指定了持久化參數,它們會以append的方式寫文件,會根據文件大小(默認16M)自動切割,生成新的文件,RabbitMQ啟動時會創建兩個進程,一個負責持久化消息的存儲,另一個負責非持久化消息的存儲(當內存不夠時會用到)。
消息存儲時,會在一個叫ets的表中記錄消息在文件中的映射以及相關信息(包括ID、偏移量、有效數據、左邊文件、右邊文件),消息讀取時根據該信息到文件中讀取,同時更新信息。
消息刪除時只從ets刪除,變為垃圾數據,當垃圾數據超出比例(默認50%),并且文件數達到3個,就會觸發垃圾回收:鎖定左右兩個文件,整理左邊文件有效數據、將左邊文件有效數據寫入左邊,更新文件信息,刪除右邊,完成合并;當一個文件的有效數據等于0時,刪除該文件。
寫入文件前先寫入buffer緩沖區,如果buffer已滿,則寫入文件,注意,此時只是操作系統的頁存,還沒落盤。
每隔25ms刷一次磁盤(比如Linux中的fsync命令),不管buffer(fd的讀、寫緩存區)滿沒滿,都將buffer和頁存中的數據落盤。
還有另外一種落盤機制:每次消息寫入后,如果沒有后續寫入請求,則直接刷盤。
此外,RabbitMQ除了消息確認機制,還有另一種方式——使用事務消息:消息生產端發送commit命令,MQ同步返回commit ok命令,這種方式由于需要同步阻塞等待MQ返回是否投遞成功,才能執行別的操作,性能較差,因此不推薦使用。
Kafka
Kafka在MQ領域以性能高、吞吐能力強、消息堆積能力強等等優勢稱著,常常用于日志收集、消息系統、用戶活動跟蹤、運營指標、流式處理等等場景,講之前先簡單聊聊Kafka的架構設計:
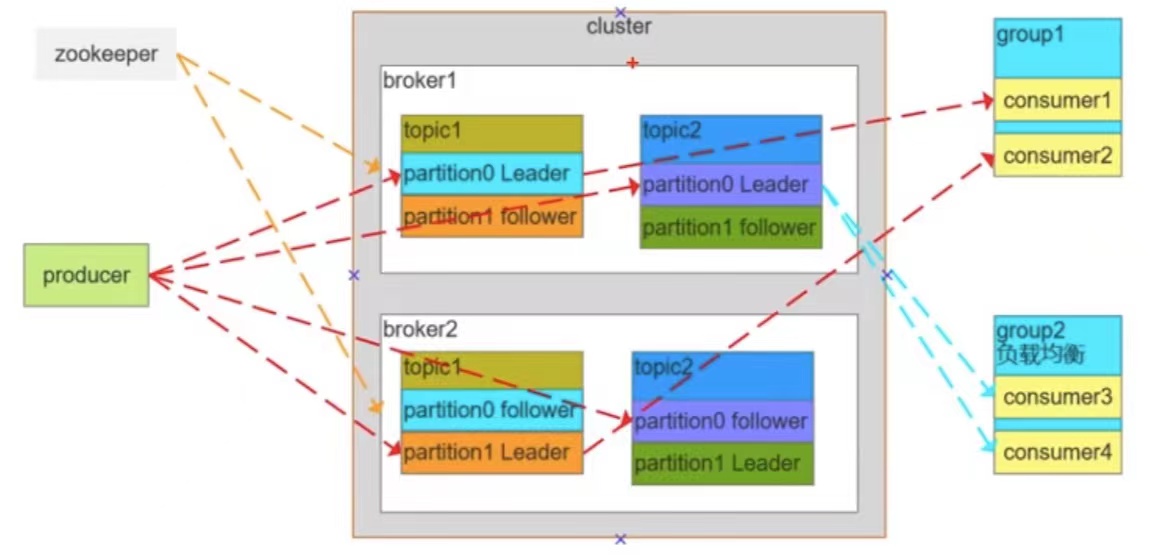
- Consumer Group:消費者組,消費者組內每個消費者負責消費不同分區的數據,提高消費能力,這是邏輯上的一個訂閱者。
- Topic:可以理解為一個隊列,Topic將消息分類,生產者和消費者面向的是同一個Topic。
Partition:為了實現擴展性,提高并發能力,一個Topic以多個Partition的方式分布到多個Broker上,每個Partition是一個有序的隊列,一個Topic的每個Partition都有若干個副本(Replica),一個Leader和若干個Follower;生產者發送數據的對象,以及消費者消費數據的對象,都是通過Leader,Follower負責實時從Leader中同步數據,保持和Leader數據的同步;當Leader發生故障時,某個Follower還會成為新的Leader。
一、生產者端
Kafka消息發送端有個ACK機制。
- 設置ack參數:ack=0,表示不重試,Kafka不需要返回ack,極有可能各種原因造成丟失;ack=1,表示Leader寫入成功就返回ack了,Follower不一定同步成功;ack=all或ack=-1,表示ISR列表中的所有Follower同步完成再返回ack。
- 設置參數unclean.leader.election.enable: false,禁止選舉ISR以外的Follower為Leader,只能從ISR列表中的節點中選舉Leader;可能會犧牲Kafka的可用性,但是能夠提高消息的可靠性。
- 重試機制,設置tries > 1,表示消息重發次數。
- 設置最小同步副本數min.insync.replicas > 1,沒滿足該值前,Kafka不提供讀寫服務,寫操作會異常。
通過設置最小同步副本數和ACK機制,可以讓MQ在性能與可靠性上達到平衡。
二、消費者端
手工提交offset(偏移量):Kafka消費者在拉取消息后,默認會自動提交offset,由于消費者每次都會根據offset來消費消息的,如果消費者處理業務失敗,實際上我們是要重新消費的,所以我們要在消息處理成功后再手工提交offset,確認消息能夠成功消費。
三、MQ本身
很簡單,通過減小broker刷盤間隔來實現高可靠。
要深究其原理,得從Kafka的持久化機制來看。
磁盤的順序讀寫:與RabbitMQ不同,Kafka是基于磁盤讀寫的,那為什么Kafka的吞吐量還這么大呢?原因是Kafka的讀寫是用順序讀寫的,不需要尋址隨機讀寫,而由于是用磁盤來寫數據,消息堆積能力必然比內存型的RabbitMQ更強
- 利用了操作系統的零拷貝技術:避免CPU將數據從一塊存儲拷貝到另外一塊存儲,關于零拷貝這里不詳述,與Java應用不同,Kafka的消息不需要在用戶緩沖區處理磁盤數據再返回,所以才能用零拷貝技術。
- 分區分段+索引:Kafka的消息實際上分布存儲在一個一個小的segment中的,每次文件讀寫也是直接操作segment,為了進一步優化查詢,Kafka又默認為分段后的數據文件建立了索引文件(就是文件系統上的.index文件),這種分區分段+索引的設計,不僅提升了數據讀取的效率,同時也提高了數據操作的并行度(類似ConcurrentHashMap的分段鎖機制)。
- 批量壓縮&批量讀寫:多條消息一起壓縮進行傳輸(比如gzip格式)與讀寫,節省帶寬。
- 直接操作page cache:雖然Kafka是Java寫的,也基于JVM運行,但Kafka的消息讀寫是直接操作操作系統頁存的,而不是在JVM的堆內存,這樣就避免JVM的GC耗時及對象創建耗時,且讀寫速度更高,JVM進程重啟緩存也不會丟失。
理解了Kafka的持久化機制是直接讀寫頁存+定時刷盤的方式,我們只需要設置刷盤策略即可在性能與可靠性上權衡。
Kafka提供3個參數來優化刷盤機制:
- log.flush.interval.messages //多少條消息刷盤1次。
- log.flush.interval.ms //隔多長時間刷盤1次。
- log.flush.scheduler.interval.ms //周期性的刷盤。
總結一下
關于框架類的面試題,最重要是得掌握技術框架的底層實現原理、適用場景,基本上回答出這兩方面就OK了,其它奇奇怪怪的細節問題要是答不出來,咱就引導面試官說出自己對框架的理解即可,畢竟細節的問題太多了。
那怎么才算掌握呢?起碼能通過框架的特性,根據需要實現一個簡易版本,比如說自己實現一個Spring框架、實現一個MQ組件等等。