













八張3090,1天壓縮萬億參數大模型!3.2TB驟降至160GB,壓縮率高達20倍
隨著GPT-4的架構被知名業內大佬「開源」,混合專家架構(MoE)再次成為了研究的重點。

GPT-4擁有16個專家模型,總共包含1.8萬億個參數。每生成一個token需要使用大約2800億參數和560TFLOPs。
然而,模型更快、更準確的代價,則是巨大的參數量,和隨之而來的高昂成本。
比如,1.6萬億參數的SwitchTransformer-c2048模型,需要3.2TB的GPU顯存才能有效運行。
為了解決這一問題,來自奧地利科技學院(ISTA)的研究人員提出了一種全新的壓縮和執行框架——QMoE。

論文地址:https://arxiv.org/abs/2310.16795
通過采用專門設計的GPU解碼內核,QMoE具備了高效的端到端壓縮推理——不僅可以實現高達20倍的壓縮率,而且只會產生輕微的精度損失。
具體而言,QMoE僅需單個GPU服務器,就可以在一天內將1.6萬億參數的SwitchTransformer-c2048模型壓縮至不到160GB,相當于每參數只有0.8位。
如此一來,就可以在4張英偉達RTX A6000或8張英偉達RTX 3090 GPU上運行,而推理時的開銷還不到未壓縮模型的5%。

MoE模型量化
混合模型(MoE)的核心理念是通過增加模型參數量,來提高網絡的建模能力,同時與標準的前饋架構相比,保持計算成本幾乎不變。
由于處理每個輸入token時僅需調用網絡中的一小部分,因此這種設計可以利用100個甚至1000個「專家」來構建超大規模的模型,并進行高效的訓練和推理。
事實證明,在推理速度相當的情況下,MoE可以大幅提高準確率和訓練速度。但如此龐大的體積,也就意味著需要大量的顯存才能讓模型跑起來。
壓縮MoE的一個主要挑戰是需要維持龐大的激活集。
對此,可以通過精心安排模型執行的方式,將需要計算的中間數據控制在一小部分。從而把主存儲從GPU卸載到價格更便宜、數量更多的CPU內存中。
具體來說就是,維持一個大型緩沖區B,并按照以下步驟對Transformer塊的稠密部分進行更新:
1. 從CPU到GPU,抓取一個包含有幾百個token的「樣本」X;
2. 通過對應的稠密層,得到結果Y;
3. 計算并存儲Y中token的專家分配;
4. 將Y發送回CPU并覆蓋B中的X。
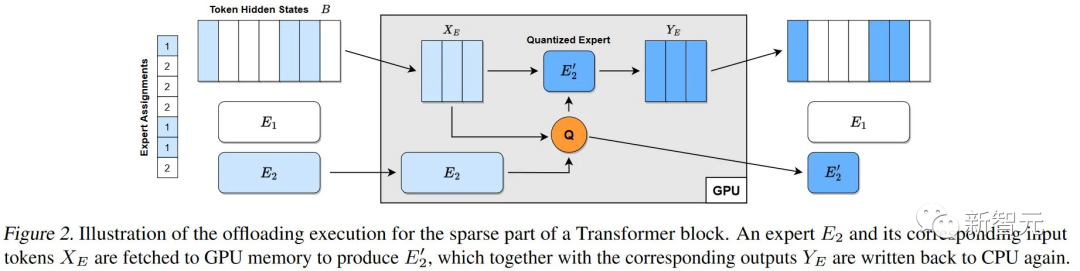
對于稀疏部分:
1. 從CPU到GPU,抓取B中所有已分配給專家E的token,用X_E表示。
2. 利用它們生成壓縮的專家E'(例如,使用GPTQ)。
3. 通過E'運行X_E,得到Y_E'。
4. 將Y_E'送回CPU并覆蓋B中的X_E。
如圖2所示,這個過程最小化了內存消耗和傳輸成本:只需一個B的副本,每個token在每個Transformer塊中只被讀寫了兩次。
更進一步的,研究人員設計了一個編碼方案和一個CUDA內核,實現了每權重低于1位的壓縮,并將推理的GPU執行開銷降至最低。

壓縮效果
精度
首先,研究人員將所有SwitchTransformer模型量化到2位和三元精度,然后評估其驗證損失。
對于128個專家,默認的校準樣本數為10K;對于2048個專家,默認的校準樣本數為160K。同時,研究人員也測試了0.5倍和2倍的樣本數。
結果顯示,使用數據依賴的量化,2位模型可以在最小的損失下實現(相對于c2048,損失為1.7%),而三元精度下的損失增加也很小(相對于c2048,損失為6.7%)。
這不僅證明了所提出的先進量化方法的有效性,而且還表明極低位寬的壓縮確實適用于大規模的MoE。

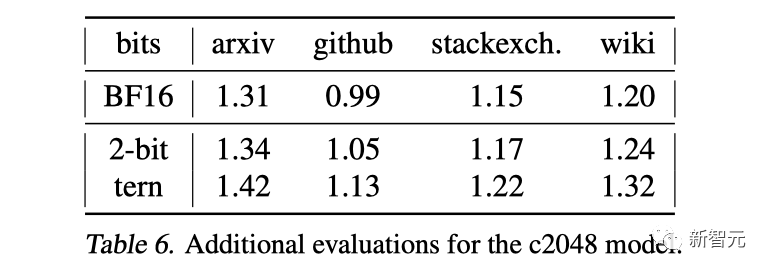
此外,研究人員還在來自RedPajama的arXiv、GitHub、StackExchange和Wikipedia的數據上進行了評估。
雖然校準數據中只有<0.01%來自這些網站,但壓縮后的模型依然保持了幾乎與核心分布相同的性能。
就校準數據而言,增加樣本數量通常會略微提高性能,在三元量化時最為明顯。但在此過程中也會出現一些噪聲,尤其是在2位時。
壓縮
測試中,研究人員同時考慮了僅MoE模塊的壓縮,以及相對于整個模型及其所有元數據的壓縮。
僅MoE本身的而言,所有規模都實現了>16倍的壓縮率,相當于每個參數的存儲空間都<1位。
在c2048上,即使是包括所有未壓縮的稠密層在內,整體的壓縮率也達到了19.81倍,相當于每個參數0.807位,從而將檢查點大小從3142GB減少到158.6GB。
此外,還可以觀察到壓縮率隨模型大小的增加而增加,這有兩個原因:
(a)自然稀疏性增加,且研究人員針對c2048優化了編碼字典;
(b)層越大,權重分布越接近獨立。

運行時間
最后,研究人員評估了針對不同數量的校準數據,在單個A6000 GPU上生成壓縮模型所需的時間。
結果顯示,較小的模型可以在一小時內壓縮完成,即便是c2048也能在不到一天的時間內完成,這證實了QMoE的高效性。
從large128到c2048,運行時間的增加與大小的差異基本成正比,盡管后者使用了多16倍的樣本。這是因為每個專家的樣本數量保持不變,而專家規模僅略有增加。

運行結果
首先,將壓縮的矩陣-向量積內核與PyTorch標準的(未壓縮)bfloat16 cuBLAS內核進行直接(孤立)比較。
圖 5(左)顯示了壓縮內核與bfloat16內核相比,在兩款不同的GPU上,MoE發現矩陣形狀所耗費的時間。
雖然研究人員使用的儲存性能較差,但執行壓縮內核所需的時間,依然比接近理想的bfloat16基線少。在特定矩陣形狀下,速度最多可提高35%。
而這些操作的延遲也非常低,其中,最小的矩陣耗時<0.02毫秒,最大的耗時<0.05毫秒。
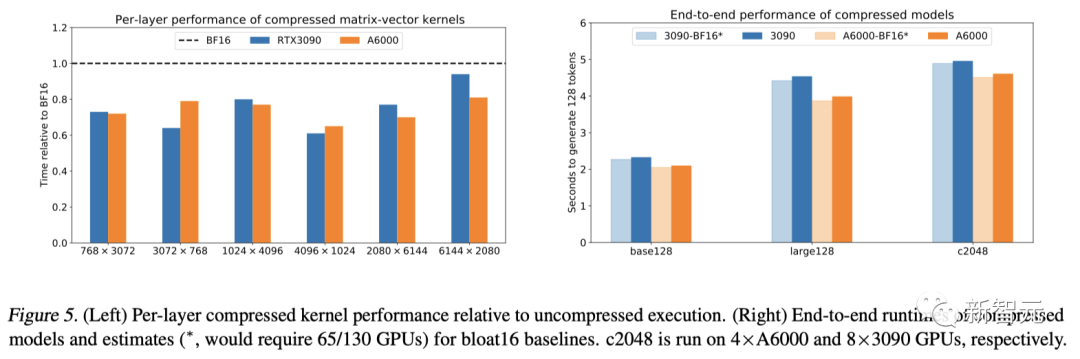
隨后,研究人員在HuggingFace中,利用壓縮MoE模型的實際權重,對內核進行了端到端的基準測試。
結果如圖5(右)所示,壓縮模型的端到端執行速度只比標準(未壓縮)的慢了<5%。
盡管每層時序更快,但速度仍略有下降,這是因為編碼器有時會將多個token路由到同一個專家。
目前的實現方式是,對每個token執行單獨的矩陣向量乘積,而基線執行的是更高效的聯合矩陣乘法。
在一些應用中,這是一個很大的瓶頸。對此,可以在內核中引入token內循環,或者在token數量較多的情況下,先進行完全解壓縮,然后再執行標準的矩陣乘法。
討論與局限性
總結而言, QMoE是一個開源的端到端壓縮和推理框架,用于解決MoE在推理過程中,內存開銷過大的問題。
研究人員首次證明了,像SwitchTransformer c2048這樣的萬億參數模型,可以精確壓縮到每個參數小于1位,壓縮率接近20倍。并且,首次在單個消費級GPU服務器上,實現了此類模型的高效端到端執行。
不過,由于只有少數大規模且精確的MoE可以被公開獲得,因此研究的模型集十分有限。
此外,由于其規模龐大,大多數MoE都是在不同的定制框架中訓練和部署的,這就需要復雜的手動集成才能用于進一步研究。
盡管如此,研究人員還是涵蓋了一些規模最大、精度最高的MoE,特別是SwitchTransformer。


























