













譯者 | 陳峻
審校 | 重樓
您也許沒有注意到,數據建模錯誤往往是導致系統性能出現問題的根本原因之一。人們往往簡單地認為,只需根據應用的訪問模式,對NoSQL數據建模即可。然而,事實上,在真正處理對于性能極其敏感的工作負載時,應用就很容易出現性能瓶頸。
例如:如果您的數據建模從根本上就效率低下的話,那么一旦被擴展到某個臨界點,應用的性能就會受到嚴重影響。即使您在強大的基礎架構上采用了最快的數據庫,也無法充分利用其潛力。本文將和您探討三種影響NoSQL數據庫性能的最常見建模方式,以及避免或解決這些問題的技巧。
不處理大分區(Large Partition)
在您的開發團隊著手擴展分布式數據庫時,大分區通常會隨之出現。此處的大分區是指:那些可能會在整個集群的副本中,產生性能問題的過大分區。具體而言,它往往取決于:
- 延遲預期:通常,分區越大,檢索所需的時間也就越長。為此,我們需要考慮頁面的大小、以及完整掃描一個分區所需的客戶端與服務器往返交互的次數。
- 平均載荷大小:較大的載荷通常會導致較高的延遲。畢竟,它們需要更多的服務器端處理時間,來進行序列化和反序列化,同時也會產生更高的網絡數據傳輸開銷。
- 工作負載需求:有時候,一些工作負載需要比平時用到更大的載荷。例如,Web3區塊鏈公司可能會將多個交易存儲為單鍵之下的BLOB,其每個鍵的大小就很容易超過1兆字節。
- 從分區中讀取數據的方式:例如,時間序列用例通常會包含時間戳聚類組件。在這種情況下,與掃描整個分區相比,僅從特定時間窗口讀取的數據就少得多。
鑒于上述方面,下表展示了大分區在不同載荷大小(如1、2和4KB)下的影響。
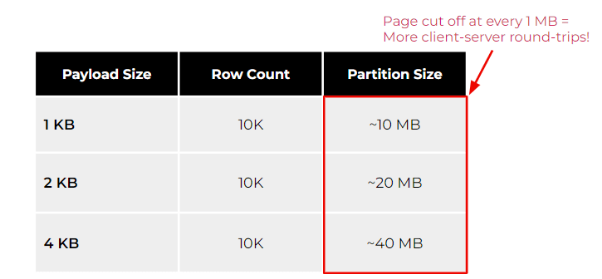
可以看出,在相同行數的情況下,負載越高,分區就越大。不過,如果您的應用需要經常掃描整體分區的話,那么請注意對數據庫予以限制,以防止內存被無限制地消耗。例如,ScyllaDB在每隔1MB就會切分開不同頁面。這正是為了防止系統內存的耗盡。其他數據庫(甚至是關系型數據庫)也有類似的保護機制,以防止無限制的查詢,導致數據庫資源的枯竭。
若要使用ScyllaDB檢索大小為4KB和1萬行數的負載,您需要檢索至少40頁,才能通過單次查詢掃描完整個分區。起初,這似乎不是什么大問題。但是,隨著時間的推移,客戶端的整體延遲會逐漸受到影響。
另一個值得考慮的因素是:在ScyllaDB和Cassandra等數據庫中,寫入數據庫的數據往往會被存儲在提交日志(commit log)和名為“memtable”的內存數據結構中。
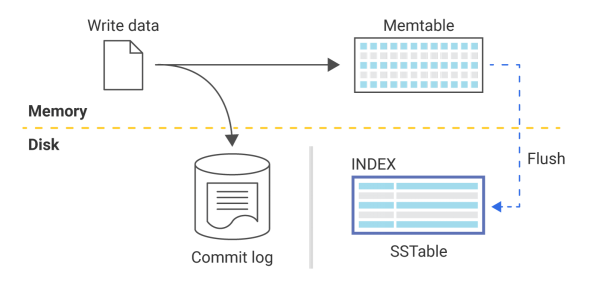
如上圖所示,提交日志是一個提前寫入的日志,除非服務器崩潰或服務中斷,否則它不會被真正地讀取到。由于memtable存在于內存中,因此最終它會被填滿。因此,為了釋放內存空間,數據庫會將內存表刷到磁盤上。這一過程會產生排序字符串表(Sorted Strings Tables,SSTables),這就是數據被持久化的過程。
那么這些又與大分區有何關系呢?實際上,SSTables有著一些需要在數據庫啟動時,保存在內存中的特定組件。它們可以確保讀取效率,并在查找數據時盡量減少存儲磁盤I/O的浪費。因此,當您擁有超大分區時(例如,2.5Terabyte的分區),這些SSTable組件就需要減少沉重的內存壓力,從而縮小數據庫的緩存空間,進一步限制延遲。
具體而言,我們該如何通過數據建模,來解決大分區問題呢?通常,我們可以從主鍵入手。畢竟主鍵決定了數據在集群中的分布方式,可以被用來提高性能和資源利用率。如您所知,一個好的分區鍵應該具有基數性(Cardinality)且能夠大致均勻地分布。例如,User Name、User ID或Sensor ID等基數性較高的屬性,都可能是很好的分區鍵。而像“State(州)”這樣的屬性則不太合適,畢竟像加利福尼亞州和德克薩斯州這樣的州,可能會比懷俄明州和佛蒙特州之類人口較少的州,擁有更多的數據。
讓我們來看一個例子。下表可被用于帶有多個傳感器的分布式空氣質量監測系統:
CREATE TABLE air_quality_data (
sensor_id text,
time timestamp,
co_ppm int,
PRIMARY KEY (sensor_id, time)
);由于time是該表格的聚類鍵(clustering key),因此不難想象,每個傳感器的分區可能會變得非常大,尤其是在每幾毫秒就收集一次數據的情況下。長此以往,這個看似無害的表最終會變得大到無法使用。而在本例中,我們只需要約 50 天。
一個標準的解決方案是修改數據模型,以減少每個分區鍵的聚類鍵數量。下面,讓我們來看看更新后的air_quality_data表:
CREATE TABLE air_quality_data (
sensor_id text,
date text,
time timestamp,
co_ppm int,
PRIMARY KEY ((sensor_id, date), time)
);完成更改后,一個分區僅保存一天內收集的數據值。這樣就不容易溢出了。由于它允許我們控制分區中存儲的數據量,因此這種技術被稱為“分桶(Bucketing)”。如果您對此方面感興趣的話,請參考鏈接--https://discord.com/blog/how-discord-stores-trillions-of-messages,以了解如何應用分桶技術,來避免出現大分區。
引入熱點(Hot Spot)
如果您有一個大分區(即存儲了絕大部分的數據集),那么您的應用訪問模式,很可能會更頻繁地訪問該分區。因此,當有問題的數據訪問模式,導致集群中的數據訪問方式失衡時,就會出現熱點。此類熱點很可能會給大分區帶來副作用。而其中一個罪魁禍首就源于:應用程序未能在客戶端采取任何限制,以至于允許“租戶”側對給定的鍵進行“大肆”訪問。
例如,某個消息應用中的機器人經常在某個頻道中發送大量信息。那么,不穩定的客戶端配置就會以重試風暴(Retry Storms)的形式引入熱點。也就是說,客戶端在嘗試著查詢特定數據時,會在數據庫超時之前,以及在數據庫仍在處理上一次查詢的同時,進行反復地重試。
通過監控儀表盤,您可以輕松地找到集群中的熱點。如下圖所示,該儀表盤顯示了讀取量過大的20個碎片。
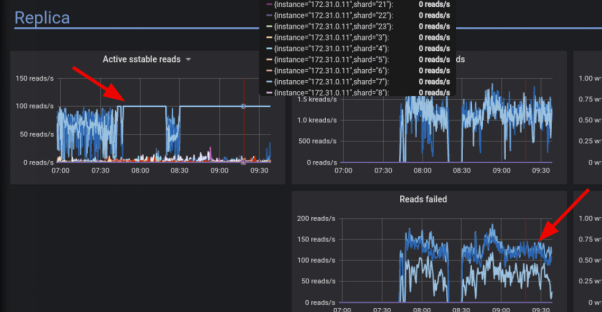
再比如,下圖展示了三個利用率較高的分片,它們都與針對鍵空間配置的三個復制因子有關。

由上圖可知,大量的讀寫傳播,給碎片 7 帶來了更高的負載。
那么,我們該如何解決熱點問題呢?首先,我們可以在其中一個受影響的節點上,對最常被命中的鍵進行取樣。同時,您也可以使用概率跟蹤(Probabilistic Tracing)等跟蹤工具,來分析有哪些查詢會命中哪些分片,以便后續采取行動。一旦發現了熱點,我們就應當考慮如下方面:
- 審查應用程序的訪問模式。您可能會發現前面提到的桶技術等需要改變的數據模型。如果需要重新排序,您可以使用諸如Snowflake之類的單調遞增組件,或是采用并發限制器,來限制不良因素。
- 指定每個分區的速率限制,以便數據庫拒絕那些訪問同一分區的查詢。
- 確保客戶端超時高于服務器端超時,以防止客戶端在服務器有機會處理之前,不斷地發出重試查詢(也就是“重試風暴”)。
濫用集合
雖然不常被使用,但是團隊往往無法恰當地使用集合。集合是指那些用于存儲和規范化相對較小的數據量。由于被存儲在單個單元格中,因此它們序列化與反序列化的成本極高。
在使用集合時,我們可以定義相關問題字段為:凍結和非凍結。凍結的集合只能作為一個整體被寫入,不能向其中添加或刪除元素。而非凍結的集合則可以被追加,而這正是人們最常濫用的集合類型。而且,更糟糕的是,人們甚至可以嵌套集合。比如:讓一個映射包含另一個映射,而后者又包含了一個列表等結構。
由于濫用集合會比大分區更快地帶來性能問題,因此集合不應過大。例如,我們創建了一個簡單的鍵/值(key:value)表,其中的鍵是sensor_id,值是在一段時間內記錄到的樣本集合。那么一旦我們開始捕獲數據,性能就會逐漸下降。
CREATE TABLE IF NOT EXISTS {table} (
sensor_id uuid PRIMARY KEY,
events map<timestamp, FROZEN<map<text, int>>>,
)下圖的監控快照顯示了,該應用同時向集合追加多個項目時發生的情況。
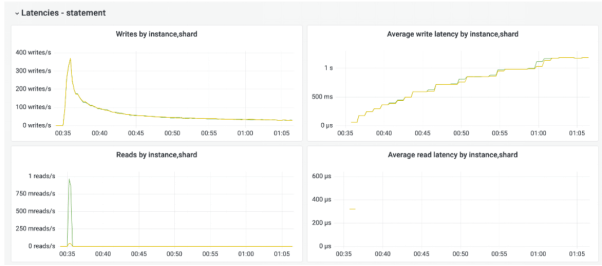
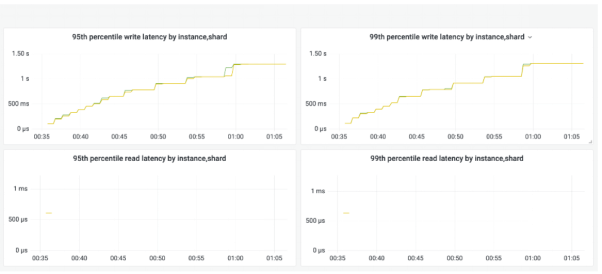
如您所看,在整體吞吐量降低的同時,99%的延遲卻在增加。其根本原因就可能來自如下方面:
- 集合單元以分類矢量的形式存儲在內存中。
- 添加元素需要合并兩個新舊集合。
- 添加元素的成本與整個集合的大小成正比。
- 樹(Tree,非矢量Vector)雖然可以提高性能,但是會降低小型集合的效率。
回到上述例子,由于不再需要向其追加數據,我們的解決方法是將時間戳移至聚類鍵,并將映射轉換為凍結的集合。如下代碼所示,如下面這樣非常簡單的更改,就能大幅提高用例的性能。
CREATE TABLE IF NOT EXISTS {table} (
sensor_id uuid,
record_time timestamp,
events FROZEN<map<text, int>>,
PRIMARY KEY(sensor_id, record_time)
)譯者介紹
陳峻(Julian Chen),51CTO社區編輯,具有十多年的IT項目實施經驗,善于對內外部資源與風險實施管控,專注傳播網絡與信息安全知識與經驗。
原文標題:NoSQL Data Modeling Mistakes that Ruin Performance,作者:Felipe Cardeneti Mendes



















