













深入理解序列化:概念、應用與技術
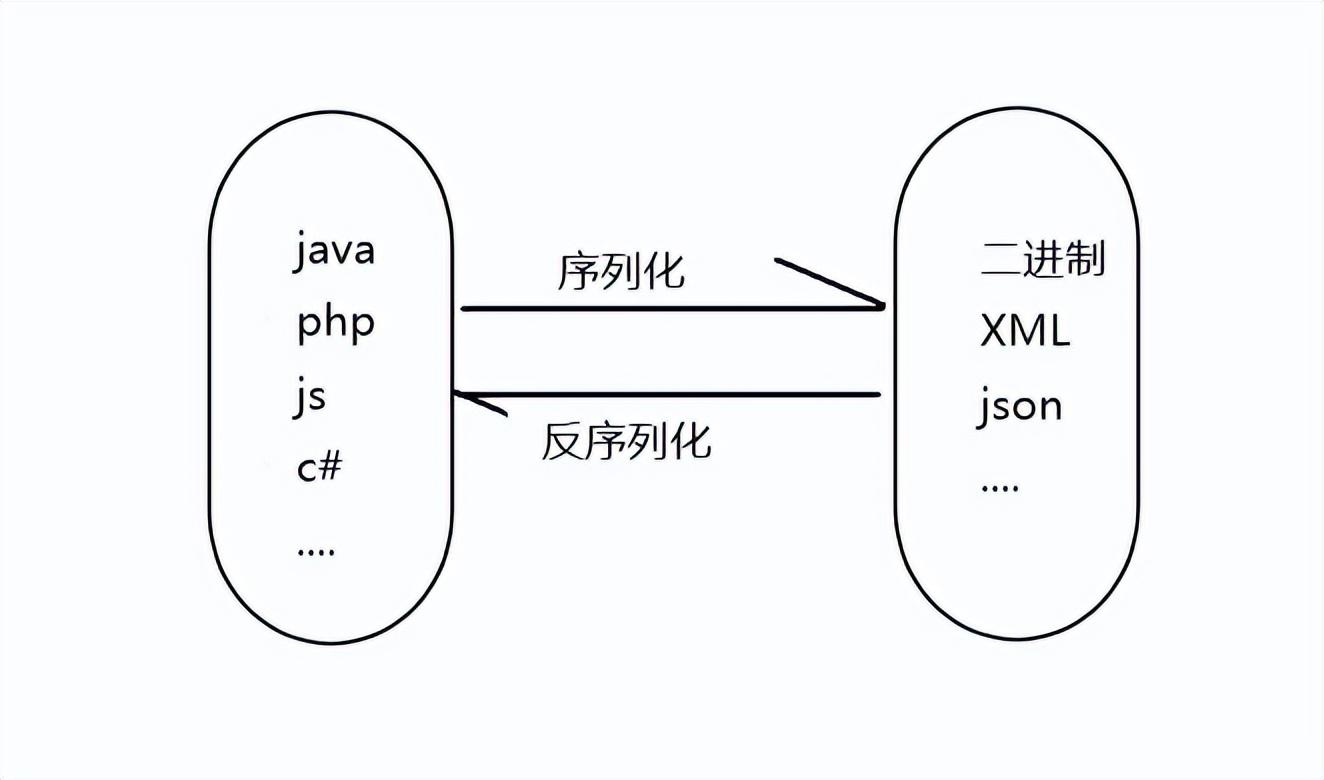
在計算機科學中,序列化(Serialization)是指將數據結構或對象狀態轉換為可存儲或傳輸的格式的過程。這個過程允許將數據保存到文件、內存緩沖區,或通過網絡傳輸至其他計算機環境,不受原始程序語言的限制。相對地,反序列化(Deserialization)則是將這種格式變回原來的數據結構或對象的過程。

序列化的形式和目的
序列化在現代軟件工程中無處不在,但其形式和目的根據應用場景而異。
形式
- 二進制序列化:將數據轉換為緊湊的二進制表示形式,常用于性能敏感的系統或低帶寬的網絡通信中。
- 文本序列化:將數據轉換成如XML、JSON、YAML等文本格式,可讀性好,易于調試,適合 Web API 和配置文件。
- 目的
- 持久化:長期保存對象的狀態,使其可以在程序重啟后恢復。
- 通信:跨進程或網絡傳輸數據時,需要將對象狀態序列化為標準格式,以便在接收端正確反序列化。
序列化的挑戰和考慮因素
數據完整性
數據必須被完整且精確地序列化,以保證反序列化后對象狀態的一致性。比如,在序列化包含循環引用的對象圖時,需要特別注意引用的處理,以防止無限循環或丟失鏈接。
安全性
安全性問題主要出現在反序列化環節。如果反序列化未經驗證的數據,可能會遭受注入攻擊,導致代碼執行或數據泄露。因此,輸入驗證和沙盒環境等安全措施是必要的。
性能
序列化和反序列化過程需要占用CPU資源,并影響I/O性能。特別是在大數據量或高頻率調用的情況下,選擇高效的序列化方法和庫顯得尤為重要。
版本兼容性
隨著業務發展,數據結構可能會變化。良好的序列化策略應該能夠處理數據模型的版本差異,提供向后兼容性支持。
反序列化時的對象圖重建
反序列化不僅僅是簡單地讀取數據,還需要重新構建對象間的關系。這需要序列化機制有能力表達和重建復雜的對象引用網絡。
常見的序列化技術
JSON
JSON 是一種輕量級的數據交換格式,能夠被人和機器輕松讀寫。它已經成為 Web API 中的事實標準,用于客戶端和服務器之間的數據交換。
XML
XML 是早期Web開發中廣泛使用的數據交換格式,它具有自我描述性,并且通過Schema定義了嚴格的結構,非常適合復雜的數據交換需求。
Protocol Buffers
Protocol Buffers 是由Google開發的一種序列化協議,提供了跨多種編程語言的接口描述語言。它通過預定義的數據結構,提供了一種更緊湊、更高效的數據序列化方式。
Apache Avro
Apache Avro 是一個支持RPC的序列化框架。它使用JSON來定義數據類型和協議,并且存儲序列化數據的元數據,這樣即使沒有代碼也能進行反序列化。
實踐建議
要有效地利用序列化和反序列化,以下是一些最佳實踐:
- 明確需求:分析應用場景,選擇滿足需求的序列化方式。
- 安全防護:對反序列化的數據進行驗證,防止潛在的安全風險。
- 性能優化:基于應用場景選擇合適的序列化庫和格式,考慮壓縮與緩存策略。
- 測試:確保對序列化和反序列化的流程進行充分的單元和集成測試。
- 文檔和維護:保持良好的文檔記錄,定期更新序列化協議及相關代碼。
總結
序列化是連接各種計算環境的紐帶,是數據持久化和互操作性的關鍵。無論是在分布式系統、微服務架構還是普通的數據存儲中,理解并妥善運用序列化及其相關技術,都將對構建高效、安全、可維護的軟件系統產生深遠影響。





















