作者 | 崔皓
審校 | 重樓
摘要
本文介紹了OpenAI的最新進展,重點關注其在多模態技術領域的突破。文章首先探討了GPT-4 Turbo模型的優化和多模態功能的融合,如圖像生成和文本到語音轉換。隨后,作者深入解析多模態技術的工作原理,特別是文本到圖像的轉換過程。通過實際應用和編程實例,展示了如何利用這些技術對圖像和視頻內容進行識別,以及將識別內容轉換為語音,體現了多模態技術在實際應用中的廣泛潛力和影響力。
開篇
OpenAI最近在其平臺上宣布了一系列引人注目的新增和改進功能,這些更新旨在進一步推動人工智能的邊界擴展。這些更新不僅包括了性能更強大且成本更低的新型GPT-4 Turbo模型,而且還引入了多模態能力,這將極大地擴展開發者和研究人員的創新空間。以下是這些更新的要點:
1.GPT-4 Turbo模型:這個新模型代表了大規模語言模型的最新進展。它不僅性能更強大,而且價格更親民。這一模型支持高達128K的上下文窗口,意味著可以處理更長的對話和文本。GPT-4 Turbo的出現,顯著提升了開發者利用大型語言模型潛能的能力,讓模型成為了一個真正的“全才”。
2.多模態功能:在多模態領域的最新進展尤為引人注目。OpenAI平臺上的新功能包括了視覺能力的提升、圖像創造(DALL·E 3)以及文本到語音(TTS)技術。這些多模態功能的結合不僅開啟了新的應用場景,還為用戶提供了一個更加豐富和互動的體驗。
3.助手API(Assistants API):OpenAI新推出的助手API讓開發者更加便捷地構建目標明確的AI應用。這個API提供了調用模型和工具的簡化方式,從而使開發復雜的輔助性AI應用成為可能,無論是為了業務流程自動化,還是為了增強用戶體驗。
看到這些功能的加入,讓人熱血澎湃,我迫不及待地登陸GPT嘗鮮這些功能。特別是多模態的功能讓我印象深刻,這里我將實踐操作以及代碼的分析與大家做一個分享。
多模態初探
多模態技術是一個日益流行的領域,它結合了不同類型的數據輸入和輸出,如文本、聲音、圖像和視頻,以創造更豐富、更直觀的用戶體驗。以下是多模態技術的幾個關鍵方面:
1.綜合多種感知模式:多模態技術整合了視覺(圖像、視頻)、聽覺(語音、音頻)、觸覺等多種感知模式。這種集成使得AI系統能夠更好地理解和解釋復雜的環境和情境。
2.增強的用戶交互:通過結合文本、圖像和聲音,多模態技術提供了更自然、更直觀的用戶交互方式。例如,用戶可以通過語音命令詢問問題,同時接收圖像和文本形式的答案。
3.上下文感知能力:多模態系統能夠分析和理解不同類型數據之間的關系,從而提供更準確的信息和響應。例如,在處理自然語言查詢時,系統能夠考慮相關的圖像或視頻內容,從而提供更為豐富的回答。
4.創新應用:多模態技術的應用范圍廣泛,包括但不限于自動化客服、智能助手、內容創作、教育、醫療和零售等領域。它允許創建新型的應用程序,這些應用程序能夠更好地理解和響應用戶的需求。
5.技術挑戰:雖然多模態技術提供了巨大的潛力,但它也帶來了諸如數據融合、處理不同數據類型的復雜性以及確保準確性和效率的挑戰。
6. OpenAI的多模態實例:在OpenAI的框架下,多模態功能的一個顯著例子是DALL·E 3,它是一個先進的圖像生成模型,可以根據文本描述創建詳細和創造性的圖像。此外,文本到語音(TTS)技術則將文本轉換為自然 sounding的語音,進一步豐富了人機交互的可能性。
多模態原理解析
前面我們對多模態進行了基本的描述,多模態是指能夠理解和處理多種類型數據(如文本、圖像、聲音等)的技術。實現文本-圖片-聲音-視頻之間的轉換。轉化是表象,實質需要理解。
在人工智能領域,多模態方法通常結合了自然語言處理(NLP)、計算機視覺(CV)和其他信號處理技術,以實現更全面的數據理解和處理能力。
為了說明多模態的工作原理,我們這里舉一個從文字轉圖片的例子,幫助大家理解。我們將整個過程展示如下:
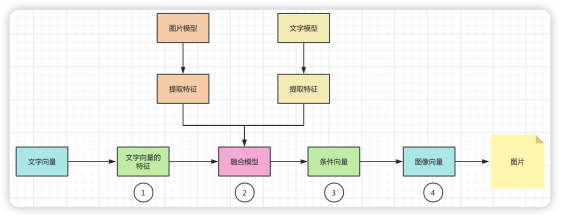
1. 文本特征提取:
首先,文本輸入通過一個文本模型(例如一個預訓練的語言模型)來提取文本特征。這個過程涉及將文本轉換成一個高維空間的向量,這個向量能夠表示文本的語義內容。
2. 融合模型:
在某些情況下,確實會存在一個專門的融合模型,它是在訓練階段通過學習如何結合不同模態的數據而得到的。這個融合模型將在推理階段使用。
在其他情況下,融合模型可能是隱含的。例如,在條件生成模型中,文本特征向量直接用作生成圖像的條件,而不需要顯式的融合步驟。
3.條件生成:
融合模型(或者直接從文本模型得到的特征向量)用于為圖像生成模型設定條件。這個條件可以理解為指導生成模型“理解”文本內容,并據此生成匹配的圖像。
4.圖像生成:
最后,圖像生成模型(如DALL·E或其他基于生成對抗網絡的模型)接收這個條件向量,并生成與之相匹配的圖像。這個過程通常涉及到大量的內部計算,模型會嘗試生成與條件最匹配的圖像輸出。
整個流程可以簡化為:文本輸入 → 文本特征提取 → 特征融合(如果有)→ 條件生成 → 圖像輸出。在這個過程中,“融合模型”可能是一個獨立的模型,也可能是條件生成模型的一部分。關鍵點是,推理時的特征融合是基于在訓練階段學到的知識和參數進行的。
多模型體驗
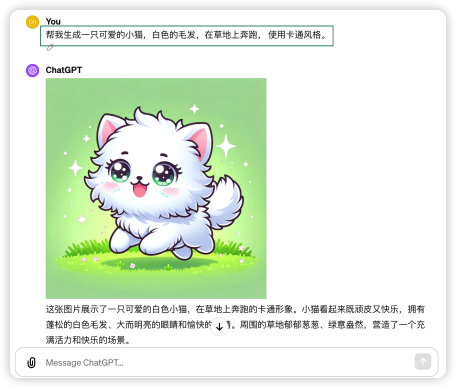
了解了多模型實現原理之后,我們來登陸ChatGPT體驗一下,現在在ChatGPT4中已經集成了DALLE 3 的功能,我們只需要輸入指令就可以生成對應的圖片。如下所示,我們通過文字描述一只可愛的貓咪,ChatGPT 就能夠幫我完成圖片的生成。
不止于此,OpenAI還能夠識別圖片,當你提供圖片之后,OpenAI會根據圖片描述其中的內容,如下圖我們從網絡上找到一張小貓的圖片,丟給OpenAI讓它識別一下。

這次我們通過調用OpenAI的API,來實現上述功能。畢竟作為程序員不敲敲代碼,只是用工具輸入文字還是不太過癮。
這段代碼使用 Python 和 OpenAI 庫來與 OpenAI 的 GPT-4 API 交互。目的是創建一個聊天會話,其中用戶可以向模型發送圖像地址。代碼通過URL地址,讀取圖像并且對其進行識別,最終輸出理解的文字。
import os
import openai
# 導入所需庫:os 用于讀取環境變量,openai 用于與 OpenAI API 交互。
openai.api_key = os.getenv('OPENAI_API_KEY')
# 從環境變量獲取 OpenAI 的 API 密鑰并設置。這樣可以避免將密鑰硬編碼在代碼中,提高安全性。
response = openai.ChatCompletion.create(
model="gpt-4-vision-preview",
# 指定使用的 GPT-4 模型版本。這里用的 'gpt-4-vision-preview' 表示一個特別的版本,可能包含處理圖像的能力。
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "這張圖片表達了什么意思?"},
{
"type": "image_url",
# 用戶消息 (messages),包括一段文本和一個圖像的 URL
"image_url": "http://www.jituwang.com/uploads/allimg/160327/257860-16032H3362484.jpg"
},
],
}
],
# 響應的最大長度 (max_tokens)
max_tokens=200,
)
print(response.choices[0])雖然代碼比較簡單,我們這里還是解釋一下。
導入庫:代碼首先導入 os 和 openai。os 庫用于讀取環境變量中的 API 密鑰,而 openai 庫用于執行與 OpenAI API 的交互。
創建聊天請求:
- Model:指定了要使用的 OpenAI 模型為 "gpt-4-vision-preview",這個版本的大模型具備處理圖像的能力。
- Messages:這是一個字典列表,模擬了用戶與 AI 聊天的過程。在這個例子中,用戶通過文本詢問一張圖片的含義,并提供了圖片的 URL。
- max_tokens:定義了模型回答的最大長度,這里設置為 200 tokens。
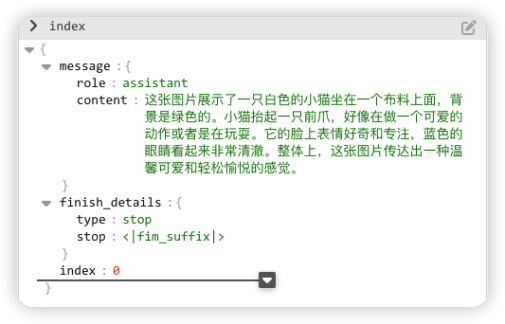
執行之后,結果是一段JSON文本,我們使用編輯器打開,如下圖所示,程序識別出圖片的內容,是一只白色的小貓,并且對動作和表情都進行了精確的描述。
從識別圖片到識別視頻
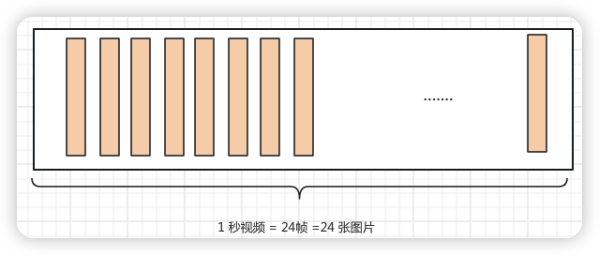
實際上OpenAI這次提供的功能不只是對圖片的識別,還可以對其進行擴展,將對圖片識別的能力推廣到視頻上。如下圖所示,假設一段1秒鐘的視頻是由24幀圖片組成,如果我們能夠將每張圖片進行識別,并且將識別的信息進行總結生成摘要是不是就可以對視頻進行識別了呢?
這個想法不錯,但是需要通過實踐去驗證,我們使用一段代碼加入早已準備好的視頻,通過OpenCV組件加載視頻,并且對視頻的內容進行讀取。將讀取之后的視頻內容,分成一幀一幀的圖片,通過對圖片的識別達到對視頻識別的目的。
代碼如下:
1.導入組件庫
# 導入IPython用于顯示功能
from IPython.display import display, Image, Audio
# 導入cv2,我們使用OpenCV庫來讀取視頻文件
import cv2
# 導入base64庫用于數據編碼
import base64
# 導入time庫用于控制顯示時間
import time
# 導入openai庫,用于調用OpenAI的API
import openai
# 導入os庫,用于操作系統級別的接口,如環境變量
import os
# 導入requests庫,用于發起HTTP請求
import requests當然,我會按照您的要求調整代碼注釋的位置,使其位于相關代碼行的上方。
視頻處理
打開一個視頻文件("the-sea.mp4"),讀取其中的每一幀,并將這些幀轉換成 JPEG 格式后編碼為 base64 字符串。這種處理方式在需要以文本格式存儲或傳輸圖像數據的場景中非常有用,如在網絡通信中發送圖像數據。
import cv2
# 導入 OpenCV 庫
video = cv2.VideoCapture("the-sea.mp4")
# 使用 OpenCV 打開視頻文件 "the-sea.mp4"
base64Frames = []
# 初始化一個空列表,用于存儲轉換為 base64 編碼的幀
while video.isOpened():
# 當視頻成功打開時,循環讀取每一幀
success, frame = video.read()
# 讀取視頻的下一幀,'success' 是一個布爾值,表示是否成功讀取幀,'frame' 是讀取的幀
if not success:
break
# 如果未能成功讀取幀(例如視頻結束),則退出循環
_, buffer = cv2.imencode(".jpg", frame)
# 將讀取的幀(frame)編碼為 JPEG 格式,'_' 是一個占位符,表示我們不需要第一個返回值
base64Frames.append(base64.b64encode(buffer).decode("utf-8"))
# 將 JPEG 編碼的幀轉換為 base64 編碼,并將其解碼為 UTF-8 字符串,然后添加到列表 'base64Frames' 中
video.release()
print(len(base64Frames), "frames read.")導入和初始化:首先導入所需的 OpenCV 庫,并創建一個空列表 base64Frames 用于存儲編碼后的幀。
讀取視頻幀:通過 while 循環和 video.read() 方法逐幀讀取視頻。如果讀取成功,將幀編碼為 JPEG 格式,然后將這些 JPEG 格式的幀轉換為 base64 編碼,并添加到列表中。
資源管理和輸出:循環結束后,使用 video.release() 釋放視頻文件,隨后打印出讀取的幀數,作為處理的結果。這提供了對視頻內容處理情況的直觀了解。
顯示視頻幀
遍歷一個包含 base64 編碼的圖像幀列表,連續顯示這些幀,從而實現視頻播放的效果。
from IPython.display import display, Image
import time
# 導入必要的庫:IPython.display 中的 display 和 Image 用于顯示圖像,time 用于控制播放速度
display_handle = display(None, display_id=True)
# 創建一個顯示句柄,用于在之后更新顯示的圖像。'display_id=True' 允許之后通過該句柄更新顯示的內容
for img in base64Frames:
# 遍歷包含 base64 編碼圖像幀的列表
display_handle.update(Image(data=base64.b64decode(img.encode("utf-8"))))
# 使用 display 句柄更新顯示的圖像。首先將 base64 編碼的字符串解碼回二進制數據,然后創建一個 Image 對象并顯示
time.sleep(0.025)
# 在每幀之間暫停 0.025 秒,以便模擬視頻播放的效果初始化顯示句柄:首先創建一個 display_handle,它是一個可以更新的顯示對象。這樣做可以在之后循環中更新顯示的圖像,而不是創建新的圖像顯示。
遍歷和顯示圖像幀:使用 for 循環遍歷 base64Frames 列表中的每一個 base64 編碼的圖像幀。在循環內部,使用 display_handle.update() 方法來更新當前顯示的圖像。這里涉及將 base64 編碼的字符串解碼為二進制數據,并使用 Image 對象將其轉換為可顯示的圖像。
控制播放速度:在每次更新圖像后,使用 time.sleep(0.025) 來暫停一段時間(0.025秒),這樣可以在圖像幀之間創建短暫的延遲,使得連續播放的視頻效果更加平滑。
查看視頻效果如下,我們截取了視頻中的一張圖片,可以看出是一段描述海上日落的視頻。

識別視頻內容
使用 OpenAI 的 API 來描述一個視頻幀的內容。首先設置請求的參數,包括模型、API 密鑰、請求的提示信息,然后調用 API 并打印返回的內容。
import os
import openai
# 導入所需的庫:os 用于訪問環境變量,openai 用于與 OpenAI 的 API 進行交互
PROMPT_MESSAGES = [
{
"role": "user", # 標記消息的發送者角色為用戶
"content": [
"這是我想上傳的視頻幀。能否幫我描述這張視頻幀的內容。",
{"image": base64Frames[0], "resize": 768}, # 選擇列表中的第一幀圖像,縮放尺寸為 768 像素
],
},
]
# 設置提示信息,以指導模型進行視頻幀的內容描述
params = {
"model": "gpt-4-vision-preview", # 指定使用的模型版本
"messages": PROMPT_MESSAGES, # 使用前面設置的提示信息
"api_key": os.environ["OPENAI_API_KEY"], # 從環境變量中獲取 API 密鑰
"headers": {"Openai-Version": "2020-11-07"}, # 設置 API 版本頭信息
"max_tokens": 300, # 設定請求的最大令牌數
}
# 設置 API 調用的參數
result = openai.ChatCompletion.create(params)
# 使用提供的參數發起 API 調用
print(result.choices[0].message.content)
# 打印 API 返回的內容,即模型對視頻幀內容的描述設置提示信息:PROMPT_MESSAGES 包含了 API 請求的核心信息,其中包括用戶角色標記和要處理的內容。這里的內容是請求模型描述視頻幀的內容,視頻幀作為 base64 編碼的字符串傳入。
配置 API 調用參數:在 params 字典中配置了 API 調用所需的所有參數,包括模型名稱、提示信息、API 密鑰、API 版本和請求的最大令牌數。
發起 API 調用:使用 openai.ChatCompletion.create 方法發起 API 調用,傳入之前配置的參數。這個調用將請求模型根據提供的視頻幀內容進行描述。
輸出結果:最后,打印出 API 返回的結果,即模型對視頻幀內容的描述。
展示最終結果,如下:
這張圖片展示了一幅美麗的日落景象。太陽正從水平線上緩緩下降,天空被染成了橙色和紅色的溫暖色調。太陽的余暉在云層間穿透,形成了壯觀的光線和陰影效果。海面平靜,太陽的反射在水面上畫出了一道閃耀的光路。遠處的群山輪廓在天空的對比下顯得剪影般的輪廓分明。整體上,這是一幅寧靜、和諧、引發深思的圖像。看來OpenAI不僅描繪了視頻中的畫面,還對其的內涵進行了引申,這是要趕超人類的節奏了。
從識別內容到語音播報
好了到現在,我們已經完成了從圖片到文字,視頻到文字的轉換了。假設我們要將視頻上傳到網站時,并且對視頻進行解釋,此時不僅需要文字更需要一段專業的語音播報。好吧!我是想展示下面的功能,如何將視頻識別的文字轉化成語音播報。
下面這段代碼使用 Python 和 OpenAI 的語音合成 API 來將文本轉換為語音,即將視頻生成的文本(描述日落景象的文本)轉換成語音。然后,它接收并匯總響應中的音頻數據,并使用 Audio 對象來播放這段音頻。
import requests
from IPython.display import Audio
import os
# 導入所需的庫:requests 用于發起 HTTP 請求,Audio 用于在 Jupyter Notebook 中播放音頻,os 用于讀取環境變量
# 向 OpenAI 的語音合成 API 發送 POST 請求
response = requests.post(
"https://api.openai.com/v1/audio/speech",
headers={
"Authorization": f"Bearer {os.environ['OPENAI_API_KEY']}",
},
json={
"model": "tts-1", # 指定使用的語音合成模型
"input": result.choices[0].message.content, # 要轉換為語音的文本
"voice": "onyx", # 選擇的語音類型
},
)
audio = b""
# 初始化一個空字節串,用于累積音頻數據
# 逐塊讀取響應中的音頻數據
for chunk in response.iter_content(chunk_size=1024 * 1024):
audio += chunk
# 使用 response.iter_content 方法按塊讀取音頻內容,每塊最大為 1 MB,并將其累加到 audio 變量中
Audio(audio)
# 使用 IPython 的 Audio 對象播放累加的音頻數據準備和發起請求:首先導入所需的庫,并準備發起一個 POST 請求到 OpenAI 的語音合成 API。請求頭部包含了 API 密鑰(從環境變量獲取),請求體包含了模型名稱、要轉換的文本內容以及語音類型。
接收音頻數據:從 API 響應中逐塊讀取音頻數據。這里使用了 1 MB 作為每個數據塊的大小限制。通過循環,將這些數據塊累加到一個字節串 audio 中。
播放音頻:最后,使用 Audio 對象來播放累積的音頻數據。這允許在 Jupyter Notebook 環境中直接播放音頻。
音頻結果如下:
大家可以嘗試上面的代碼,生成自己的語音文件。
總結
文章通過詳盡地探討OpenAI的多模態功能,展示了人工智能領域的最新進展。從GPT-4 Turbo模型的介紹到多模態技術的應用實例,不僅提供了技術的理論背景,還通過具體的代碼示例,展現了如何將這些技術實際應用于圖像生成、視頻內容識別和語音轉換。這不僅彰顯了AI技術的前沿動向,也為讀者提供了實踐AI技術的洞見和啟發。
作者介紹
崔皓,51CTO社區編輯,資深架構師,擁有18年的軟件開發和架構經驗,10年分布式架構經驗。