實時“人臉”模糊!實戰教程
大家好,今天跟大家分享一個實戰的教程。
老規矩,先看效果(明確一下目標):

隨著人臉識別技術的發展,給我們的日常生活帶來了許多的便利,但是同樣的也存在隱私的問題。以及可能被不法分子用于做一些違法事情。
所以很多視頻博主,都會給路人打碼。但是手動打碼是一件非常繁瑣的事情,對于單幀圖片還算簡單,但是假設視頻的幀率是 25FPS,即一秒中有25幀圖片,那么一個幾分鐘的視頻,其工作量也非常的可怕。
因此我們嘗試使用程序自動去執行這樣子的操作!
我們可以使用Opencv、Mediapipe和Python,實現實時模糊人臉。
我們可以分兩步完成:
- 在打碼之前,首先確定人臉位置
- 取出臉,模糊它,然后將處理后的人臉放回到視頻幀中(視頻處理類似)
(留個作業:如何實現對除了本人以外的其他人打碼?)
1、在打碼之前,首先確定人臉位置
老規矩,首先配置一下環境,安裝必要的庫(OpenCV 和 MediaPipe)
pip install opencv-python
pip install mediapipe在 MediaPipe 庫中提供了人臉關鍵點檢測的模塊。
詳細的內容可以參考:https://google.github.io/mediapipe/solutions/face_mesh.html
當然在該項目的代碼中,也提供人臉關鍵點檢測的代碼。
“facial_landmarks.py”的文件:
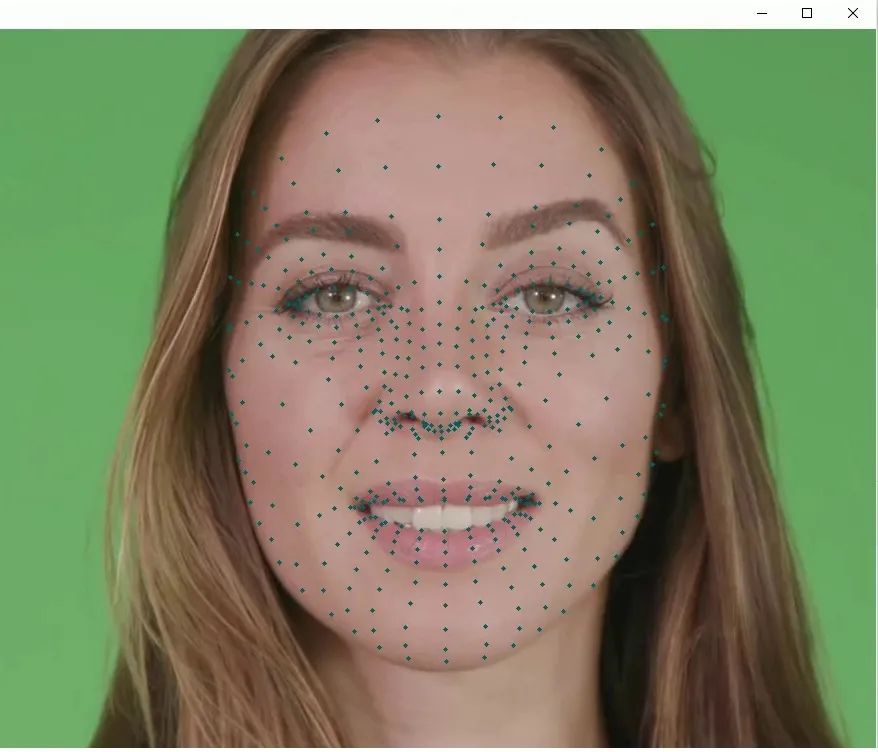
人臉關鍵點檢測效果圖
下面我們就一起來寫一下這部分的代碼:
- 首先導入必要的庫以及用于人臉關鍵點檢測的模塊:
import cv2
import mediapipe as mp
import numpy as np
from facial_landmarks import FaceLandmarks
# Load face landmarks
fl = FaceLandmarks()- 然后使用檢測出來的人臉關鍵點最外圍的一圈關鍵點繪制一個多邊形(臉部輪廓)。這里使用opencv 中的convxhull() 函數可以實現:
# 1. Face landmarks detection
landmarks = fl.get_facial_landmarks(frame)
convexhull = cv2.convexHull(landmarks)繪制完成后的結果如下所示:

之后使用上面所提取到的人臉關鍵點坐標創建mask,用提取我們在視頻幀中感興趣的區域:
# 2. Face blurrying
mask = np.zeros((height, width), np.uint8)
# cv2.polylines(mask, [convexhull], True, 255, 3)
cv2.fillConvexPoly(mask, convexhull, 255)結果如下所示:

得到這個mask,我們就可以進一步對人臉進行模糊(打碼)處理。
打碼的操作,這里使用的是OpenCV 中的cv2.blur() 函數:
# Extract the face
frame_copy = cv2.blur(frame_copy, (27, 27))
face_extracted = cv2.bitwise_and(frame_copy, frame_copy, mask=mask)結果:
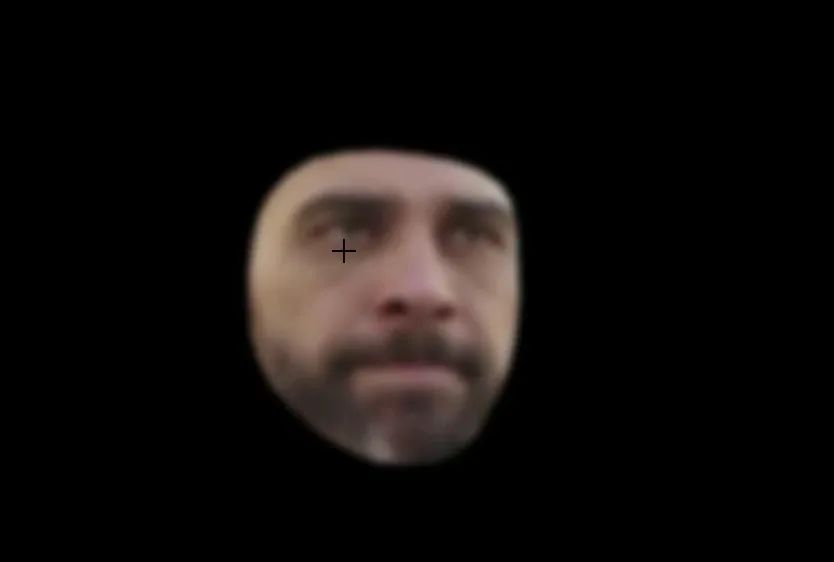
目前,我們已經實現對人臉進行打碼操作,剩下的就是對人臉以外的區域進行提取,并合并成最終的結果即可!
對人臉以外的區域進行提取(背景),實際上對上面的mask 進行取反即可。
背景提取:
# Extract background
background_mask = cv2.bitwise_not(mask)
background = cv2.bitwise_and(frame, frame, mask=background_mask)從圖像的細節可以看出,背景是完全可見的,但面部區域已經變成黑色了。這是我們將在下一步中應用模糊人臉的空白區域。

最后一步,將上面兩步獲取的人臉mask 和背景進行相加即可,這里使用cv2.add() 即可實現我們的目標:
# Final result
result = cv2.add(background, face_extracted)結果:

這是對一幀圖片進行處理。
2、取出臉,模糊它,然后將處理后的人臉放回到視頻幀中
上面的操作都是在單幀圖片上進行處理的,如果我們需要出來的是視頻的話,其實原理是完全一樣的,只不過是將一個視頻拆成一系列的圖片即可。
稍微做一些修改:
(1)輸入文件 (圖片 ---> 視頻)
cap = cv2.VideoCapture("person_walking.mp4")(2)對輸入的視頻幀,做一個循環遍歷:
while True:
ret, frame = cap.read()
frame = cv2.resize(frame, None, fx=0.5, fy=0.5)
frame_copy = frame.copy()
height, width, _ = frame.shape
...