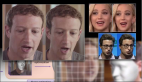
突發!ImageNet 數據集中的人臉全都變模糊了
2012年,人工智能研究人員在計算機視覺方面取得了巨大進步,被稱為ImageNet的數據集至今仍被用于成千上萬的人工智能研究項目和實驗。但是上周ImageNet上的所有人臉都突然消失了,因為數據集管理者為了保護隱私決定模糊處理它們。
ImageNet 數據集的管理者為如今深度學習的進步鋪平了道路。現在,他們在保護人們的隱私方面又邁出了一大步:對數據集模糊處理。
2012年,人工智能研究人員在計算機視覺方面取得了巨大進步,這很大程度歸功于一個異常龐大的圖像集。
這個數據集中有數以千計的日常物體、人物和圖片中的場景,這些圖片都是從網上搜集并用手工標記的。
這些被稱為 ImageNet 的數據集至今仍被用于成千上萬的人工智能研究項目和實驗。
但是上周 ImageNet 上的所有人臉都突然消失了,因為負責管理數據集的研究人員決定模糊它們。
正如 ImageNet 幫助開創了人工智能的新時代,要修復它也面臨很多挑戰,主要是對無數人工智能程序、數據集和產品的影響和挑戰。
普林斯頓大學的助理教授 Olga Russakovsky 是 ImageNet 的負責人之一,他說: 「我們擔心隱私問題。」
在2012年,計算機科學家一直致力于能開發能夠識別圖像中物體的算法,ImageNet 就是為此而創建的。
然后,一種叫做深度學習的技術,通過給神經網絡添加標記的例子來「教」它,而且還被證明比以前的方法效果更好。
從那時起,深度學習推動了人工智能的復興,同時也暴露了這個領域的缺陷。
例如,面部識別已經被證明是深度學習的一個特別流行和有前景的應用,但它也是有爭議的。
出于對侵犯公民隱私的擔憂,美國一些城市已經禁止政府使用這項技術,因為這些程序對非白人臉部的識別精確度較低。
ImageNet 包含了150萬張圖片和大約1000個標簽。它主要用于評估機器學習算法的性能,或者訓練執行特殊計算機視覺任務的算法。
如今,它對243198張照片進行了模糊處理。
Russakovsky 說 ImageNet 團隊想要確定是否有可能在不改變識別對象的能力的情況下模糊數據集中的人臉。
「人們在數據中是偶然出現的,因為他們恰好出現在描述這些物體的網絡照片中,」她說。
換句話說,在一張顯示啤酒瓶的圖片中,即使喝啤酒的人的臉上有一個粉紅色的污點,對啤酒瓶本身來說并無影響。
在 ImageNet 更新的同時,發布了一篇研究論文,數據庫背后的團隊解釋說,他們使用亞馬遜的人工智能服務 Rekognition 模糊了面孔。

然后,他們付錢給 Mechanical Turk 的員工確認并調整他們的選擇。
研究人員說,模糊臉部并不影響在 ImageNet 上訓練的幾種物體識別算法的性能。
他們還表明,用這些物體識別算法構建的其他算法也同樣不受影響。
「我們希望這種概念驗證為該領域更多的隱私意識視覺數據收集實踐鋪平了道路,」魯薩科夫斯基說。
2019年12月,ImageNet 團隊刪除了由人工標簽引入的帶有偏見的貶義詞,因為一個名為挖掘 AI 的項目引起了人們對這個問題的關注。
該研究表明他們可以在數據集中識別個人,包括計算機科學研究人員。他們還發現其中包含色情圖片。
普拉布說,模糊臉是好事,但令人失望的是 ImageNet 團隊沒有承認他和比爾哈恩的工作。Russakovsky 表示,論文的更新版本中將出現一條引文。
模糊人臉仍然可能會對基于 ImageNet 數據訓練的算法產生意外后果。例如,算法可能學會在搜索特定對象時尋找模糊的面孔。
Russakovsky 說: 「需要考慮的一個重要問題是,當你部署一個基于面部模糊數據集的模型時,會發生什么情況。」
例如,在此數據集上訓練的機器人可能會因為不能識別現實世界中的人臉而被拋棄。
麻省理工學院的研究科學家 Aleksander Madry 已經發現了 ImageNet 的局限性。他認為,一個人工智能模型在包含模糊人臉的數據集上訓練,當顯示包含人臉的圖像時,可能會表現得很奇怪。

他說: 「數據中的偏差可能非常微妙,但同時可能會產生重大的后果。這就是為什么在機器學習的背景下考慮魯棒性和公平性如此棘手。」
不過最近國內「315」也在提AI公司侵犯隱私權的問題,還是希望各位AI公司在發展技術的同時,也能思考一下這些附帶來的問題。