Python 哈希表的實現——字典
哈嘍大家好,我是咸魚
接觸過 Python 的小伙伴應該對【字典】這一數據類型都了解吧
雖然 Python 沒有顯式名稱為“哈希表”的內置數據結構,但是字典是哈希表實現的數據結構
在 Python 中,字典的鍵(key)被哈希,哈希值決定了鍵對應的值(value)在字典底層數據存儲中的位置
那么今天我們就來看看哈希表的原理以及如何實現一個簡易版的 Python 哈希表
ps:文中提到的 Python 指的是 CPyhton 實現
何為哈希表(hash table)
哈希表(hash table)通常是基于“鍵-值對”存儲數據的數據結構
哈希表的鍵(key)通過哈希函數轉換為哈希值(hash value),這個哈希值決定了數據在數組中的位置。這種設計使得數據檢索變得非常快
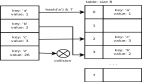
舉個例子,下面有一組鍵值對數據,其中歌手姓名是 key,歌名是 value
 圖片
圖片
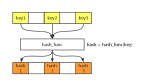
如果我們想要將這些鍵值對存儲在哈希表中,首先需要將鍵的值轉換成哈希表的數組的索引,這時候就需要用到哈希函數了
哈希函數是哈希表實現的主要關鍵,它能夠處理鍵然后返回存放數據的哈希表中對應的索引
一個好的哈希函數能夠在數組中均勻地分布鍵,盡量避免哈希沖突(兩個鍵返回了相同的索引)
 圖片
圖片
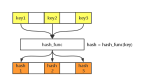
哈希函數是如何處理鍵的,這里我們創建一個簡易的哈希函數來模擬一下(實際上哈希函數要比這復雜得多)
 圖片
圖片
這個簡易版哈希函數將歌手名(即 key)首字母的 ASCII 值與哈希表大小取余,得出來的值就是歌名(value)在哈希表中的索引
那這個簡易版哈希函數有什么問題呢?聰明的你一眼就看出來了:容易出現碰撞。因為不同的鍵的首字母有可能是一樣的,就意味著返回的索引也是一樣的
例如我們假設哈希表的大小為 10 ,我們以上面的歌手名作為鍵然后執行 simple_hash(key, 10) 得到索引
 圖片
圖片
可以看到,由于Juice WRLD 和 J.cole 的首字母都一樣,哈希函數返回了相同的索引,這里就發生了哈希碰撞
雖然幾乎不可能完全避免任何大量數據的碰撞,但一個好的哈希函數加上一個適當大小的哈希表將減少碰撞的機會
當出現哈希碰撞時,可以使用不同的方法(例如開放尋址法)來解決碰撞
應該設計健壯的哈希函數來盡量避免哈希碰撞
我們再來看其他的鍵,Kanye 通過 simple_hash() 函數返回 index 5,這意味著我們可以在索引 5 (哈希表的第六個元素)上找到 其鍵 Kanye 和值Come to life
 圖片
圖片
哈希表優點
在哈希表中,是根據哈希值(即索引)來尋找數據,所以可以快速定位到數據在哈希表中的位置,使得檢索、插入和刪除操作具有常數時間復雜度 O(1) 的性能
與其他數據結構相比,哈希表因其效率而脫穎而出
不但如此,哈希表可以存儲不同類型的鍵值對,還可以動態調整自身大小
Python 中的哈希表實現
在 Python 中有一個內置的數據結構,它實現了哈希表的功能,稱為字典
Python 字典(dictionary,dict)是一種無序的、可變的集合(collections),它的元素以 “鍵值對(key-value)”的形式存儲
字典中的 key 是唯一且不可變的,這意味著它們一旦設置就無法更改
 圖片
圖片
在底層,Python 的字典以哈希表的形式運行,當我們創建字典并添加鍵值對時,Python 會將哈希函數作用于鍵,從而生成哈希值,接著哈希值決定對應的值將存儲在內存的哪個位置中
所以當你想要檢索值時,Python 就會對鍵進行哈希,從而快速引導 Python 找到值的存儲位置,而無需考慮字典的大小
 圖片
圖片
可以看到,我們通過方括號[key]來訪問鍵對應的值,如果鍵不存在,則會報錯
 圖片
圖片
為了避免該報錯,我們可以使用字典內置的 get() 方法,如果鍵不存在則返回默認值
 圖片
圖片
在 Python 中實現哈希表
首先我們定義一個 HashTable 類,表示一個哈希表數據結構
 圖片
圖片
在構造函數 __init__() 中:
- size 表示哈希表的大小
- table是一個長度為 size 的數組,被用作哈希表的存儲結構。初始化時,數組的所有元素都被設為 None,表示哈希表初始時不含任何數據
在內部函數 _hash() 中,用于計算給定 key 的哈希值。它采用給定鍵 key 的第一個字符的 ASCII 值,并使用取余運算 % 將其映射到哈希表的索引范圍內,以便確定鍵在哈希表中的存儲位置。
然后我們接著在 HashTable 類中添加對鍵值對的增刪查方法
 圖片
圖片
其中,set() 方法將鍵值對添加到表中,而 get() 該方法則通過其鍵檢索值。該 remove() 方法從哈希表中刪除鍵值對
現在,我們可以創建一個哈希表并使用它來存儲和檢索數據:
 圖片
圖片
前面我們提到過,哈希碰撞是使用哈希表時不可避免的一部分,既然 Python 字典是哈希表的實現,所以也需要相應的方法來處理哈希碰撞
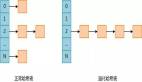
在 Python 的哈希表實現中,為了避免哈希沖突,通常會使用開放尋址法的變體之一,稱為“線性探測”(Linear Probing)
當在字典中發生哈希沖突時,Python 會使用線性探測,即從哈希沖突的位置開始,依次往后查找下一個可用的插槽(空槽),直到找到一個空的插槽來存儲要插入的鍵值對。
這種方法簡單直接,可以減少哈希沖突的次數。但是,它可能會導致“聚集”(Clustering)問題,即一旦哈希表中形成了一片連續的已被占用的位置,新元素可能會被迫放入這片區域,導致哈希表性能下降
為了緩解聚集問題,假若當哈希表中存放的鍵值對超過哈希表長度的三分之二時(即裝載率超過66%時),哈希表會自動擴容
最后總結一下:
- 在哈希表中,是根據哈希值(即索引)來尋找數據,所以可以快速定位到數據在哈希表中的位置
- Python 的字典以哈希表的形式運行,當我們創建字典并添加鍵值對時,Python 會將哈希函數作用于鍵,從而生成哈希值,接著哈希值決定對應的值將存儲在內存的哪個位置中
- Python 通常會使用線性探測法來解決哈希沖突問題