Linux高性能編程—哈希表
大家好,這里是物聯網心球。
談到Linux高性能編程,我們繞不開高效數據結構,今天我們來講解哈希表,哈希表是使用非常廣泛的數據結構,很多開源項目都會用到哈希表,Linux內核也大量使用了哈希表。
1.什么是哈希表?
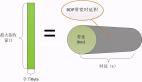
在介紹哈希表之前,我們先來思考一個問題:我們如何通過學生名從學生信息表中快速查找出學生信息?
 圖片
圖片
為了從學生信息表中快速查找學生信息,我們需要借助一種高效數據結構哈希表來完成。
哈希表(Hash table,也叫散列表),是根據關鍵字(Key)直接進行訪問的數據結構。它通過把關鍵字映射到表中一個位置來訪問記錄,以加快查找的速度。這個映射函數叫做哈希函數(也叫散列函數),存放記錄的數組叫做哈希表。
 圖片
圖片
哈希表最大的特點就是可以快速實現查找、插入和刪除操作,由于哈希表直接通過關鍵字映射查找,時間復雜度接近于O(1)。
哈希表廣泛應用于數據庫索引、緩存系統、字典實現、計數器等多種場景。
2.哈希表重要概念
學習哈希表我們需要掌握幾個重要概念:哈希函數,哈希沖突,哈希擴容。
2.1 哈希函數
哈希函數是將任意長度的輸入消息映射為固定長度輸出的函數,哈希函數有很多種構造方法:
- 直接定址法:取關鍵字或關鍵字的某個線性函數值為哈希地址,形式為H(key)=key或H(key)=a*key+b(a、b為常數)。
- 數字分析法:適用于關鍵字位數多且某些位分布不均的情況,通過抽取關鍵字中分布均勻的若干位作為哈希地址。
- 平方取中法:當關鍵字中各位分布不均時,可求其平方值并取中間的幾位作為哈希地址。
- 除留余數法:最常用的方法,形式為H(key)=key mod p(p<m,m為哈希表長)。
- 折疊法:適用于關鍵字位數多且分布均勻的情況,將關鍵字分割后疊加求和作為哈希地址。
- 隨機數法:取關鍵字的隨機函數值作為哈希地址,適用于關鍵字長度不等的情況。
2.2 哈希沖突
哈希沖突是指不同輸入經哈希函數得到相同輸出。
具體來說,在使用哈希函數時,可能會出現兩個或更多的輸入值被映射到同一哈希值的情況,這就是哈希沖突。在哈希表中,這種現象會導致不同的鍵被映射到同一個位置,從而可能引發數據丟失或檢索效率下降的問題,因為需要額外的操作來處理這種沖突。
 圖片
圖片
哈希沖突的發生是由于哈希函數將任意長度的輸入轉換為固定長度的輸出,而輸出空間通常遠小于輸入空間,因此不同的輸入可能會映射到相同的輸出地址上。
解決哈希沖突的方法包括開放尋址法、鏈表法等。
1)開放尋址法
當哈希表中的一個位置被占用時,此方法會尋找下一個可用的位置來存放數據。此方法避免了使用額外的數據結構,如鏈表,來存儲具有相同哈希值的鍵值對。
 圖片
圖片
2)鏈表法
鏈表法通過維護一個鏈表數組來解決哈希沖突。
每個鏈表頭指針存儲在數組的一個槽位中,具有相同哈希值的所有元素都將存儲在同一個鏈表中。
這種方法允許哈希表有更高的裝載因子,因為它不受聚集問題的影響。
 圖片
圖片
2.3 哈希擴容
哈希擴容是哈希表在數據量達到一定閾值時增加其容量的過程。
這里需要引入一個概念裝載因子。
哈希表裝載因子 = 插入表中的元素個數 / 哈希表長度
當哈希表中的元素數量超過設定的裝載因子與表長度的乘積時,會觸發擴容操作。哈希擴容的目的是減少哈希沖突,提高查詢和插入效率。
 圖片
圖片
3.哈希表編程
Linux內核很多模塊使用了哈希表,我們參考Linux內核哈希表(hlist)來設計我們自己的哈希表。
哈希表重要數據結構如下:
struct hlist_node { //哈希節點
struct hlist_node *next, **pprev; //后驅指針,前驅指針
};
struct hlist_head { //哈希鏈表頭
struct hlist_node *first; //first指針
};
typedef struct pack {
struct hlist_node node; //哈希節點
int seq; //關鍵字
} pack_t;
typedef struct hash_table {
char name[24]; //哈希表名稱
int num; //哈希表元素數量
int size; //哈希表大小
struct hlist_head htable[0]; //哈希表
}hash_table_t;1) 創建哈希表
hash_table_t *hash_table_create(int size) {
hash_table_t *t = (hash_table_t *)malloc(sizeof(hash_table_t) + size * sizeof(struct hlist_head));
if (!t) return NULL;
t->num = 0;
t->size = size;
sprintf(t->name, "%d hash table", size);
for (int i = 0; i < size; i++) {
hlist_head_init(&t->htable[i]);
}
return t;
}哈希表采用柔性數組htable[0]表示,malloc申請內存時,除了申請hash_table_t結構大小內存外,還要申請哈希表數組大小內存。
 圖片
圖片
申請完哈希表數組后,需通過hlist_head_init函數對哈希表數組每個鏈表進行初始化。
2)插入節點
void hash_table_insert(struct hlist_node *node, int key, hash_table_t *t) {
int index = key & (t->size - 1); //哈希函數,計算索引值
hlist_add_head(node, &t->htable[index]); //插入節點
t->num++; //鍵值對加1
printf("%s num/size:%d/%d insert key:%d\n", t->name, t->num, t->size, key);
}
pack_t *pkt = malloc(sizeof(pack_t)); //創建數據包節點
hlist_node_init(&pkt->node); //初始化節點
pkt->seq = seq; //設置關鍵字
hash_table_insert(&pkt->node, pkt->seq, t); //插入哈希表哈希表插入節點步驟:
- 通過關鍵字計算出哈希表數組索引值,通過索引值找到鏈表頭。
- 將節點插入鏈表頭。
 圖片
圖片
為了保證哈希表通用性,Linux內核通常會把節點域和數據域進行解耦,節點域只負責完成節點的插入,查找,刪除,數據域可以根據業務需求自行定義。
測試程序中的struct pack結構的node成員為節點域,seq為數據域。
3) 查詢節點
#define hlist_for_each_safe(pos, n, head) \
for (pos = (head)->first; pos && ({ n = pos->next; 1; }); \
pos = n)
hlist_for_each_safe(pos, n, &t->htable[index]) {
if (pos) {
//查詢成功
}
}哈希表查詢節點步驟:
- 通過關鍵字計算出哈希表數組索引值,通過索引值找到鏈表頭。
- 通過for循環輪詢鏈表,直到找到關鍵字匹配成功的節點。
4) 刪除節點
void hlist_del_node(struct hlist_node *node) {
struct hlist_node *next = node->next;
struct hlist_node **pprev = node->pprev;
WRITE_ONCE(*pprev, next);
if (next)
WRITE_ONCE(next->pprev, pprev);
}
void hash_table_del(int key, hash_table_t *t, do_del del) {
int index = key & (t->size - 1);
struct hlist_node *pos, *n;
//查詢鏈表
hlist_for_each_safe(pos, n, &t->htable[index]) {
if (pos) {
hlist_del_node(pos); //從鏈表刪除節點
del(pos); //釋放節點內存
t->num--;
printf("%s num/size:%d/%d del key:%d\n", t->name, t->num, t->size, key);
}
}
}哈希表刪除節點步驟:
- 通過關鍵字計算出哈希表數組索引值,通過索引值找到鏈表頭。
- 通過for循環輪詢鏈表,通過關鍵字找到匹配的節點并刪除節點。
刪除節點的步驟和插入節點的步驟相反。
 圖片
圖片
5)哈希擴容
void hash_table_resize(hash_table_t *t1, hash_table_t *t2, do_move move) {
printf("%s num/size:%d/%d move to %s num/size:%d/%d\n",
t1->name, t1->num, t1->size,
t2->name, t2->num, t2->size);
struct hlist_node *pos, *n;
for (int i = 0; i < t1->size; i++) { //輪詢舊哈希表每個鏈表
hlist_for_each_safe(pos, n, &t1->htable[i]) {
if (pos) { //查找到生效節點
hlist_del_node(pos); //刪除節點
move(pos, t2); //將節點移至新哈希表
t2->num++;
}
}
}
}
if (t->num > t->size) { //判斷負載因子,觸發哈希擴容
t2 = hash_table_create(t->size << 1); //新哈希表擴容至2倍
if (!t2) {
printf("hash table create error\n");
return -1;
}
hash_table_resize(t, t2, pack_move); //開始擴容
hash_table_destroy(t, pack_del); //釋放就哈希表
t = t2;
}當哈希表元素越來越多時,此時整個哈希表的插入,查詢,刪除效率會越來越低,通過裝載因子判斷是否需要進行哈希擴容。
哈希擴容步驟:
- 創建新哈希表,新哈希表的大小為舊哈希表的2倍。
- 將舊哈希表的所有節點通過新哈希函數移至新哈希表。
- 刪除舊哈希表。
6) 釋放哈希表
void hash_table_destroy(hash_table_t *t, do_del del) {
struct hlist_node *pos, *n;
for (int i = 0; i < t->size; i++) { //刪除哈希表生效節點
hash_table_del(i, t, del);
}
free(t); //釋放哈希表內存
}釋放哈希表需要清空哈希表數組每個鏈表中的節點,防止內存泄露,最后釋放哈希表。