













作者 | 崔皓
審校 | 重樓
摘要
AutoGen是基于AI Agent的框架,通過模擬人類決策過程來解決復雜問題。它利用AI Agent來處理大量數據,做出快速決策,并優化用戶交互。具備數據處理、自動化決策、用戶交互和復雜問題解決能力的AutoGen,為用戶提供了處理復雜問題的新思路。通過構建包含多個AI代理的應用程序,AutoGen簡化了LLM應用程序的構建過程,并支持多樣化的對話模式,提升了效率和生產力。

本文中,我們通過一個具體的例子——A股小助手,展示了如何使用AutoGen框架。在這個示例中,用戶通過代理發起請求,助手代理通過自動生成和驗證代碼的方式,協助用戶完成了股票數據的下載、分析和圖表繪制任務。
從AI Agent開始
在當今時代,人工智能技術已深入滲透到我們生活和工作的方方面面,從簡化日常任務到優化復雜的業務流程,AI的影響無處不在。然而,盡管AI技術的發展迅速,但在處理一些特別復雜的問題時,它仍然面臨挑戰。這些問題往往涉及到大量數據的處理、復雜決策的制定,以及對動態環境的快速適應,這些都是傳統AI系統難以克服的難題。
正是在這種背景下,AI Agent的概念應運而生。AI Agent是一種特殊類型的人工智能系統,它通過模擬人類的決策過程來處理復雜的任務。這些智能代理能夠處理和分析大量數據,提供快速且準確的解決方案,從而在那些對人類來說過于耗時或復雜的任務中大放異彩。AI Agent的核心優勢在于其能夠極大地提高處理這些復雜問題的效率和生產力,從而推動技術的進一步發展和應用。
AI Agent解決的具體問題包括:
數據處理和分析:AI Agent能夠快速處理和分析大量數據,提供有洞察力的結果,這對于人類來說可能既費時又費力。
自動化決策:在需要快速響應的場景中,AI Agent可以自動做出決策,減少了人為干預的需要。
用戶交互:通過聊天機器人等形式,AI Agent能夠提供7*24小時的客戶服務,改善用戶體驗。
復雜問題解決:AI Agent能夠解決復雜的問題,如預測分析優化問題等,這些通常超出了人類的直接處理能力。
什么是AutoGen
AI Agent為我們提供了一種處理復雜問題的思路,那么如何實現AI Agent呢?那就是AutoGen, AutoGen作為一個框架,提供了創建和管理AI Agent的必要工具和結構。它不僅僅是一個簡單的代理實現,而是一個全面的解決方案,使得開發者能夠構建復雜的基于多個AI代理的應用程序。
Microsoft AutoGen,用于開發使用多個代理進行對話以解決任務的大型語言模型(LLM)應用程序。AutoGen的代理是可定制的、可對話的,并且無縫地允許人類參與。它們可以在使用LLM人類輸入和工具的組合的各種模式下操作。
主要特點:
AutoGen使構建基于多代理對話的下一代LLM應用程序變得簡單,它簡化了復雜LLM工作流的編排自動化和優化。
它支持復雜工作流的多樣化對話模式,并提供了不同復雜度的工作系統示例,展示了AutoGen如何輕松支持多樣化的對話模式。
AutoGen提供了增強的LLM推理功能,包括API統一緩存以及高級使用模式,如錯誤處理多配置推理上下文編程等。
AutoGen不僅功能強大,而且安裝簡單,通過pip安裝:
pip install pyautogen接下來,我們想通過AutoGen示例,讓大家對其有更加全面的了解。
A股小助手:用戶代理與智能助手
在快節奏的職場環境中,經常會遇到需要對公開的商業數據進行匯總和分析的任務。想象一下,您的老板要求您收集和分析某些關鍵數據,比如股票市場的表現。這項任務不僅包括搜索和下載相關數據,還涉及到對數據的深入分析,并且需要將分析結果以可視化的形式呈現。這個過程不僅繁瑣,而且在處理數據時還存在潛在的風險和偏差,因此,一個能夠有效協助您的工具變得至關重要。
在這種情境下,讓我們以一個具體的例子來展示如何使用AutoGen來簡化這一過程。假設您需要比較中國A股市場中兩只知名股票——萬科A和招商銀行的表現。具體任務是下載這兩只股票的歷史數據,對它們的收益情況進行比較,并生成相應的分析圖表。這不僅需要對數據進行準確的提取和處理,還要求能夠以一種清晰直觀的方式展示結果。
使用AutoGen,您可以構建一個流程,其中包括多個AI代理,每個代理負責處理流程的不同部分。例如,一個代理可以負責從金融數據庫中下載所需的股票數據,另一個代理則專注于數據的分析和處理,最后一個代理則將分析結果轉化為易于理解的圖表。通過這種方式,AutoGen不僅大大減輕了您的工作負擔,還提高了整個分析過程的準確性和效率。最終,您可以向老板展示一份既全面又直觀的股票表現對比報告,這份報告不僅基于最新的數據,而且以一種易于理解的圖形方式呈現。
思路整理
在開始實現上述功能之前,先讓我們把參與者和流程整理一下,如下圖所示:
AutoGen處理股票數據比較的過程,有用戶、用戶代理、用戶助手三個參與者。用戶負責提出問題。用戶代理由AutoGen的對象扮演,它負責理解用戶提出的問題,并向用戶助手發出命令,如果在執行過程中用戶助手遇到問題,用戶代理需要對其進行解釋。用戶助手負責拿出解決方案,生成執行代碼,同時還需要評估代碼的正確性。最終,將執行的代碼交給用戶代理執行。
流程的步驟如下:
- 用戶提出問題,需要將股票的比較信息通過畫圖的方式展示出來。
- 用戶助手收到問題后,進行理解和解釋,隨后判斷問題的性質,并且轉交給用戶助手進行執行。
- 用戶助手采取相應的處理措施,按照得到的方案生成執行任務,在模擬代碼執行的時候發現問題。
- 針對問題,用戶助手進行自我修復,再次模擬執行代碼。在代碼通過執行之后,將其交給用戶代理執行。
- 用戶代理執行代碼之后,將結果返回給用戶。
 股票比較流程圖
股票比較流程圖
代碼編寫
清楚流程之后我們來看看代碼,如下:
# 導入autogen模塊。這個模塊可能是一個自動生成某些配置的庫。
import autogen
# 使用autogen模塊中的config_list_from_json函數。
# 此函數的作用是從一個JSON格式的配置文件中創建配置列表。
config_list = autogen.config_list_from_json(
# 第一個參數是JSON配置文件的名稱,這里指定的是"OAI_CONFIG_LIST.json"。
# 這個JSON文件包含了一些配置數據。
"OAI_CONFIG_LIST.json",
# 第二個參數是一個字典,它用于過濾配置文件中的內容。
# 這里的字典指定了只選擇模型為"gpt-4"的配置。
filter_dict={
"model": ["gpt-4"],
},
)這段代碼用于導入AutoGen 的模塊并調用其中的 config_list_from_json 函數加載與大模型相關的配置信息。下面按照要求進行解釋:
1. 導入模塊:
import autogen:導入名為 autogen 的Python模塊。這個模塊的具體功能未在代碼中說明,但根據名稱推測,它可能與自動生成配置或代碼有關。
2. 函數調用:
config_list_from_json 函數從JSON文件中讀取配置,并根據提供的過濾條件生成一個配置列表。
過濾字典:
3. filter_dict:用于過濾JSON文件中的內容。在這個例子中,它指定了["gpt-4"] 作為AutoGen要使用的模型。
接下來看看 OAI_CONFIG_LIST.json文件長什么樣子。文件包含了一個JSON數組,每個元素是一個JSON對象,代表一個API配置。這個文件可能被用于存儲不同API環境的配置信息,如API密鑰和基礎URL。
[
{
#大模型的名字
'model': 'gpt-4',
#對應的API的Key
'api_key': '<your OpenAI API key here>',
},
{
'model': 'gpt-4',
'api_key': '<your Azure OpenAI API key here>',
'base_url': '<your Azure OpenAI API base here>',
'api_type': 'azure',
'api_version': '2023-06-01-preview',
},
{
'model': 'gpt-4-32k',
'api_key': '<your Azure OpenAI API key here>',
'base_url': '<your Azure OpenAI API base here>',
'api_type': 'azure',
'api_version': '2023-06-01-preview',
},
]接著重頭戲上演,我們創建了兩個對象:assistant 和 user_proxy。它們用來創建用戶代理和用戶助手。用于模擬用戶代理和用戶助手之間的交互。下面是對代碼的逐行解釋:
1.創建用戶助手 (assistant)
# 創建一個名為'assistant'的AssistantAgent對象,這個對象可能代表一個智能助手。
assistant = autogen.AssistantAgent(
name="assistant", # 名字屬性被設置為'assistant'。
llm_config={ # llm_config是一個字典,用于配置助手的行為。
"cache_seed": 42, # 'cache_seed'可能用于初始化隨機數生成器,以保持結果的一致性。
"config_list": config_list, # 'config_list'是之前從JSON文件中得到的配置列表。
"temperature": 0, # 'temperature'設置為0,可能用于控制生成內容時的隨機性或創造性。
},
)2.創建用戶代理 (user_proxy)
# 創建一個名為'user_proxy'的UserProxyAgent對象,這個對象可能代表一個用戶界面或代理。
user_proxy = autogen.UserProxyAgent(
name="user_proxy", # 名字屬性被設置為'user_proxy'。
human_input_mode="NEVER", # 'human_input_mode'被設置為'NEVER',表明不預期會有來自真人的輸入。
max_consecutive_auto_reply=10, # 'max_consecutive_auto_reply'設定在需要用戶輸入而沒有輸入時,自動回復的最大次數。
is_termination_msg=lambda x: x.get("content", "").rstrip().endswith("TERMINATE"), # 'is_termination_msg'是一個函數,用于判斷消息內容是否表示終止對話。
code_execution_config={ # 'code_execution_config'配置代碼執行的環境。
"work_dir": "coding", # 'work_dir'設定工作目錄為'coding'。
"use_docker": False, # 'use_docker'表明在執行代碼時不使用Docker容器。
},
)3.初始化聊天和發送消息
# user_proxy使用initiate_chat方法向助手發起聊天,并發送一條消息。
user_proxy.initiate_chat(
assistant, # 指定要發送到的助手。
message="""今天是幾號? 請幫我比較萬科A股票和招商銀行股票的收益情況,用圖表的形式對兩者進行比較。""", # 發送的消息內容。
)assistant 是一個配置了特定參數的助手代理,可能用于執行某種自動化任務或處理。
user_proxy 是一個模擬用戶的代理,配置了自動回復和終止對話的條件。
user_proxy 通過 initiate_chat 方法與 assistant 開啟對話,并發送了一個關于比較股票收益的任務描述。
結果展示
在執行代碼之后可以產生結果,由于結果內容比較長,涉及到方案的提出,代碼生成,代碼驗證,代碼修改等過程。這是一個復雜的自我修正過程,主要體現了用戶代理與助手之間的互動中,我把結果的輸出整理成如下內容,方便大家閱讀:
提問-用戶代理To助手:
用戶詢問了當前的日期,并請求比較萬科A股票與招商銀行股票的收益情況,并要求以圖表形式展示。
得出方案-助手To用戶代理:
助手提出了一個解決方案,該方案分為三個主要步驟:
1. 使用Python的datetime庫獲取當前日期。
2. 利用pandas_datareader庫從Yahoo Finance獲取股票的歷史數據。
3. 使用matplotlib庫將數據繪制成圖表形式,比較兩只股票的收益情況。
然而,當嘗試執行獲取Yahoo財經數據的代碼時遇到了問題,錯誤提示表明類型錯誤,字符串索引必須是整數。
再次執行代碼-助手To用戶代理:
助手建議使用yfinance庫來替代pandas_datareader,以解決從Yahoo財經獲取數據的問題。在成功安裝yfinance庫后,助手提供了新的代碼片段來重新獲取股票數據,并將數據保存到CSV文件中。然后,又提供了另一段代碼來創建圖表,這次的代碼執行成功。
最終得到結果-助手To用戶代理:
助手確認萬科A和招商銀行的歷史價格數據已成功獲取,并且圖表已創建。由于環境限制,助手指出無法直接顯示圖表,并建議用戶在本地環境中運行代碼以查看圖表。最終,通過發送“TERMINATE”,結束了對話。
AutoGen任務代碼
在整個過程中,用戶代理與助手之間的交互主要集中在解決問題和代碼執行上。助手在診斷并解決問題時表現出適應性和靈活性,最終提供了滿足用戶請求的結果。
下面我們把用戶助理生成的代碼放在下面,大家可以參考。這段Python代碼用于比較兩只股票(萬科A和招商銀行)的每日收益情況,并將結果以圖表形式展示。下面是對每一部分代碼的詳細解釋:
# 導入必要的Python庫。
import datetime # 用于處理日期和時間。
import pandas as pd # 用于數據分析和操作。
import matplotlib.pyplot as plt # 用于數據可視化。
import yfinance as yf # 用于從Yahoo Finance下載股票數據。
# 獲取當前日期并打印。
today = datetime.date.today()
print("今天是:", today)
# 設置獲取股票數據的起始和結束日期。
start_date = '2020-01-01' # 設置起始日期為2020年1月1日。
end_date = today # 設置結束日期為當前日期。
# 使用yfinance下載萬科A和招商銀行的股票數據。
vanke = yf.download('000002.SZ', start=start_date, end=end_date) # 下載萬科A的數據。
cmb = yf.download('600036.SS', start=start_date, end=end_date) # 下載招商銀行的數據。
# 計算每日收益率。收益率是通過將每日的收盤價與前一日的收盤價進行比較計算得出的。
vanke['Daily Return'] = vanke['Close'].pct_change() # 計算萬科A的每日收益率。
cmb['Daily Return'] = cmb['Close'].pct_change() # 計算招商銀行的每日收益率。
# 使用matplotlib創建圖表并設置圖表大小。
plt.figure(figsize=(12,6))
# 設置圖表的標題。
plt.title('Daily Return Comparison')
# 繪制兩只股票的每日收益率曲線。
vanke['Daily Return'].plot(label='Vanke A') # 繪制萬科A的收益率曲線。
cmb['Daily Return'].plot(label='CMB') # 繪制招商銀行的收益率曲線。
# 添加圖例。
plt.legend()
# 顯示圖表。
plt.show()代碼整體比較簡單,其執行過程如下:
1. 導入所需的庫。
2. 獲取并打印當前日期。
3. 定義獲取股票數據的時間范圍。
4. 從Yahoo Finance下載指定日期范圍內的萬科A和招商銀行股票數據。
5. 計算并添加每日收益率到下載的數據中。
6. 繪制并顯示兩只股票的每日收益率對比圖表。
代碼中使用的yfinance庫是一個流行的金融數據接口,可從Yahoo Finance下載歷史市場數據。Matplotlib是一個廣泛使用的Python繪圖庫,可以創建多種靜態動態和交互式圖表。.pct_change()函數用于計算數據幀中元素的百分比變化,常用于金融數據分析中計算收益率。plt.show()函數調用會打開一個窗口展示生成的圖表。在Jupyter Notebook或其他交互式環境中,圖表通常會直接顯示。
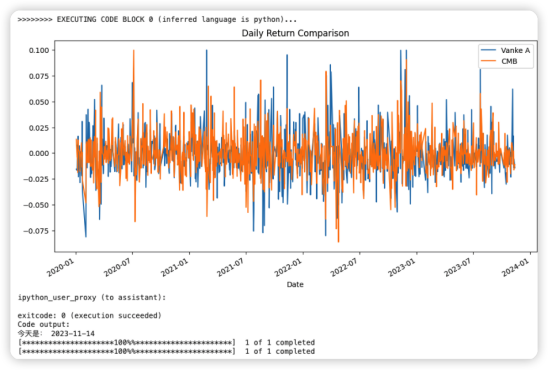 兩只股票收益的比較圖
兩只股票收益的比較圖
總結
本文介紹了AutoGen框架及其在金融數據分析中的應用。用戶通過代理請求幫助,AutoGen框架的助手代理接收任務后,使用Python代碼處理股票數據并繪制比較圖表。這個過程展示了AutoGen在處理數據下載、分析和可視化方面的能力。
通過實現一個簡單的A股小助手,AutoGen減輕了用戶的工作負擔,提高了任務執行的準確性和效率。使用AutoGen,即使是復雜的任務,也可以通過構建流程、分配代理和自動化代碼執行來簡化,從而使用戶能夠以更直觀的方式呈現數據和分析結果。
作者介紹
崔皓,51CTO社區編輯,資深架構師,擁有18年的軟件開發和架構經驗,10年分布式架構經驗。














