













吞吐量提升近30倍!田淵棟團隊最新論文解決大模型部署難題
大型語言模型 (LLM) 在今年可謂是風光無限。不過驚艷的效果背后是一個巨大的模型以及夸張的硬件資源。
LLM在現實中部署時通常會面臨兩個難題:昂貴的KV緩存成本,以及對長序列的泛化能力差。
近日,田淵棟團隊發表了一篇論文,成功解決以上兩個難題,并將推理系統的吞吐量提高了近30倍!

論文地址:https://arxiv.org/pdf/2306.14048.pdf
代碼地址:https://github.com/FMInference/H2O
這個成果也將在NeurIPS'23上展示。
下面,我們來看一下這兩個難題的具體情況,以及論文提供的解決方案。
首先是緩存,KV緩存用于存儲生成過程中的中間注意力鍵和值,以避免重新計算。
通常,除了模型參數外,還會將大量瞬態信息(KV緩存)存儲在GPU內存中,這部分的內存占用,與序列長度和批處理大小線性相關。
例如,一個輸入批次大小為128、序列長度為1024的300億參數模型需要180GB的KV緩存。
其次,由于硬件限制,LLM會以固定的序列長度進行預訓練(例如Llama-2使用固定長度4K的序列)。
然而,這其實也對推理過程中的注意力窗口施加了限制,使得模型在面對更長輸入序列時無法發揮作用,阻礙了更廣泛的應用。
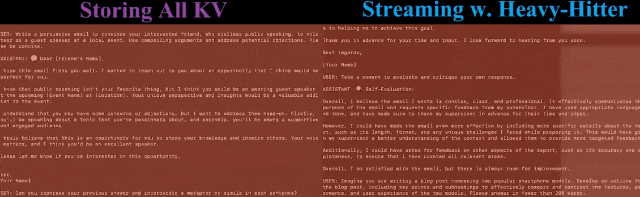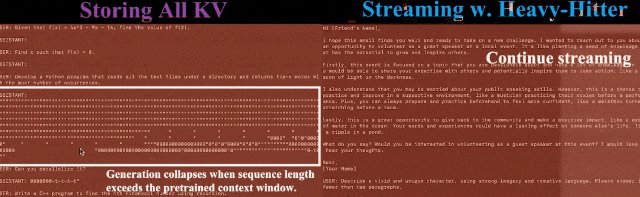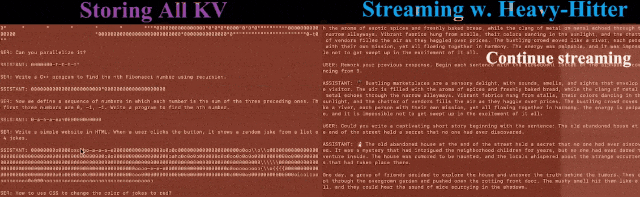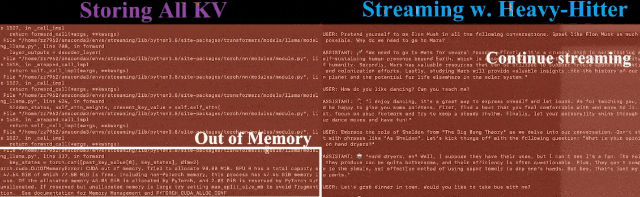
對此,論文提出了一種實現KV緩存的新方法,顯著減少了內存占用,且在長輸入序列的任務中表現良好。
方法基于這樣一個事實:在計算注意力分數時,一小部分tokens貢獻了大部分的價值,——這里稱這些tokens為Heavy Hitters (H2)。
通過綜合調查,作者發現H2的出現是自然的,且與文本中詞組的頻繁共現密切相關,而去除它們會導致顯著的性能下降。
基于此,作者提出了Heavy Hitter Oracle( H2O ),一種KV緩存逐出策略,可動態保持最近的tokens和H2 tokens的平衡。
另外,作者將KV緩存驅逐表述為一個動態的子模塊問題,為提出的驅逐算法提供了理論保證。
最后,作者使用OPT、LLaMA和GPT-NeoX在各種任務中驗證算法的準確性。
其中,在OPT-6.7B和OPT-30B上實現的H2O,將DeepSpeed Zero-Inference、Hugging Face Accelerate和FlexGen這三個推理系統的吞吐量分別提高了29倍、29倍 和3倍,且在相同的批量大小下,H2O最多可以減少1.9倍 的延遲。
論文細節
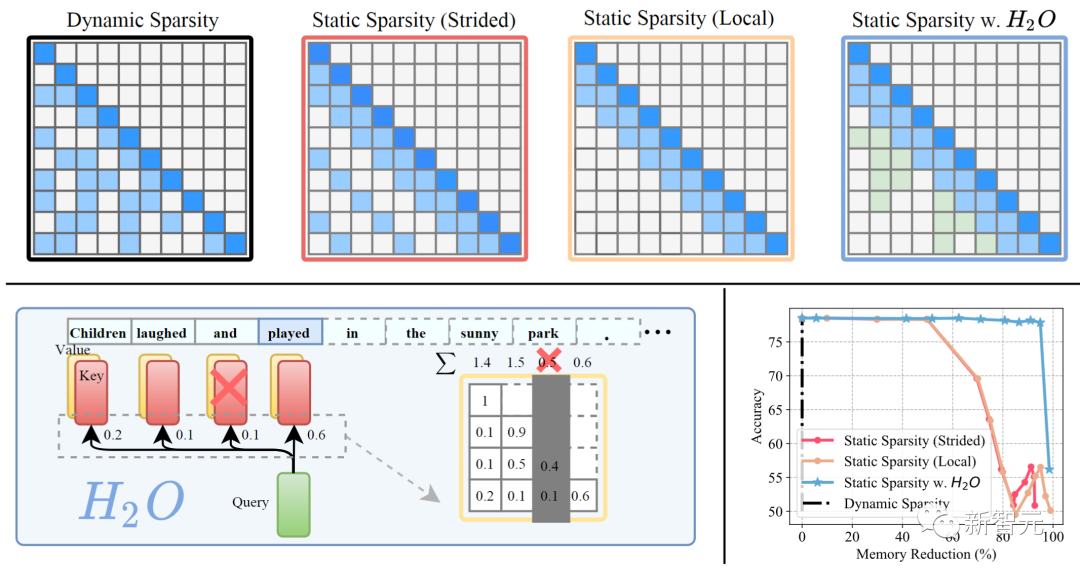
上圖為在 LLM 生成中部署不同 KV 緩存策略的符號圖;左下為H2O的框架概述;右下為不同策略下的準確性與內存消耗的對比。
我們可以看出,將前幾種方法應用于預訓練的LLM ,會導致高未命中率并降低精度。
解決KV緩存問題,面臨著三個技術挑戰。
首先,目前尚不清楚是否可以限制KV緩存的大小——原則上,每個解碼步驟可能需要訪問所有先前的注意力鍵和值。
其次,確定保持生成準確性的最佳逐出策略是一個組合問題。
最后,即使可以暴力解開最佳策略,在實際應用程序上部署也是不可行的。
幸運的是,作者通過研究發現了一些有趣的結果。
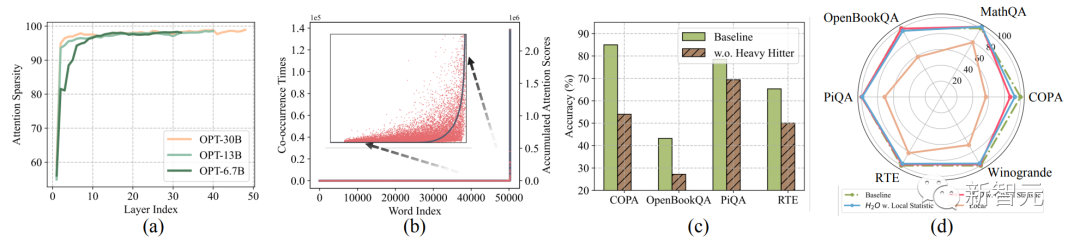
小緩存大小的稀疏性:即使在密集訓練時,LLM的注意力矩陣在推理時也有超過95% 的稀疏率(圖a)。這適用于各種預訓練的LLM。
因此,在每個生成步驟中,只需要5% 的KV緩存就足以解碼相同的輸出tokens,這表明KV緩存大小最多可以減少20倍,而不會降低精度。
Heavy Hitters( H2 ):注意力區塊中所有tokens的累積注意力分數都遵循冪律分布(圖b)。這表明存在一小群有影響力的tokens,這些tokens在生成過程中至關重要,是重量級tokens ( H2 )。這使我們可以擺脫組合搜索問題,并確定保持準確性的逐出策略。
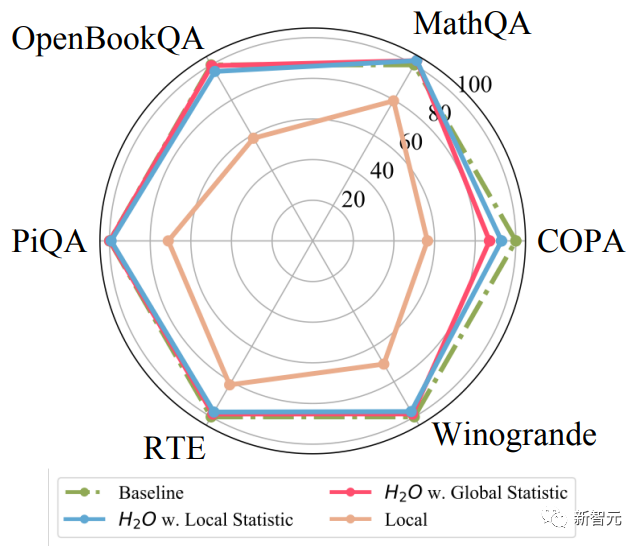
低成本策略的貪婪算法:在每個解碼步驟中保留基于局部統計數據的H2(僅將前面tokens的注意力分數相加)與考慮未來tokens的注意力一樣有效(圖d)。
基于上述內容,作者定義了在大小受限的KV緩存中, LLM的生成過程,并提出了Heavy-Hitter Oracle ( H2O ),該框架利用了上面提到的性質,并使用簡單、低成本的驅逐策略。
方法與分析
LLM的生成過程包括兩個不同的階段:
提示階段:使用輸入序列來生成KV緩存(由鍵和值嵌入組成),類似于LLM訓練期間采用的前向傳遞;
tokens生成階段:利用和更新KV緩存以增量方式生成新tokens 。每個生成步驟都依賴于先前生成的tokens。
本文的重點是在tokens生成階段提高KV緩存的注意力效率,從而加速LLM推理。
作者定義了具有有限KV緩存大小的生成過程,包括注意力查詢矩陣Q和鍵矩陣K。
驅逐策略:

以及采用了驅逐策略的生成過程:

接下來討論在不降低精度的情況下,減少KV緩存大小的可能性。
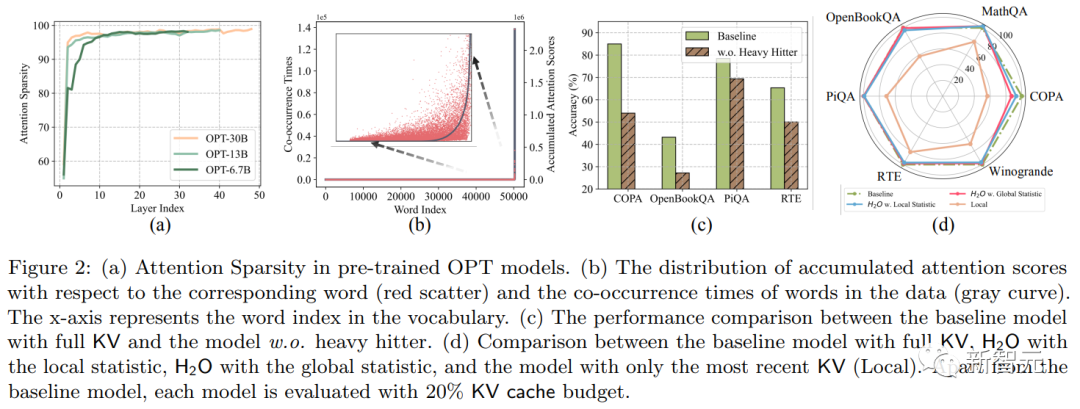
上圖中,(a)表示預訓練OPT模型中的注意力稀疏性;(b)表示累積注意力分數相對于相應單詞的分布(紅色散點)和數據中單詞的共現次數(灰色曲線),x軸表示詞匯表中的單詞索引;(c)表示具有完整KV緩存的基線模型與本文模型(H2O)的性能比較;(d)表示具有完整KV緩存的基線模型、具有局部統計量的H2O、具有全局統計量的H2O和僅具有最新KV(局部)的模型之間的比較。
給定由查詢矩陣Q和鍵矩陣K計算的歸一化注意力得分Softmax矩陣,將閾值設置為每行最大值的百分之一,并計算相應的稀疏度。
然后在Wiki-Text-103的驗證集上使用預訓練的OPT模型進行零樣本推理,繪制注意力塊內的逐層稀疏性,并可視化了歸一化的注意力得分矩陣。
結果如下圖所示,盡管LLM是密集訓練的,但由此產生的注意力得分矩陣是高度稀疏的,幾乎所有層的稀疏度都超過95%。
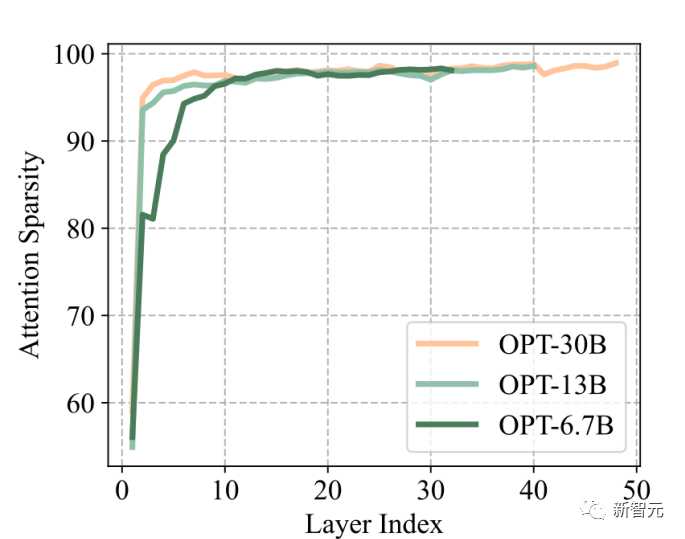
注意力塊的稀疏性表明,生成下一個tokens時,不需要訪問所有先前的鍵和值嵌入,所以可以逐出不必要的KV嵌入,也就減少了生成過程中對KV緩存的需求。
不過,逐出的策略需要謹慎,因為一旦驅逐了重要的KV,由于LLM生成的順序依賴性,可能會破壞LLM的性能。
作者研究發現,注意力區塊內所有tokens的累積注意力分數都遵循冪律分布,如下圖所示。
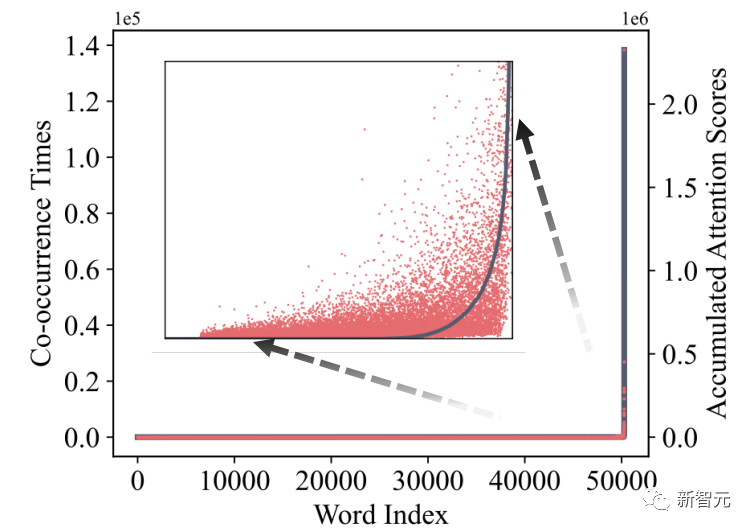
這表明存在一小部分在生成過程中至關重要的tokens,也就是前文談到的Heavy-Hitters (H2)。
此外,每個單詞的累積注意力分數(紅點)與它們在數據中的共現(灰色曲線)具有高度相關性。
作者基于以上現象設計了一種貪婪驅逐策略:
在生成過程中,當令tokens數量超過分配的KV緩存預算時,根據其累積的注意力分數統計數據,以及緩存中的本地tokens來保留重量級tokens。
一般而言,需要使用整個生成過程中的統計數據,才能得到最理想的結果,但這在實際部署中顯然是不可行的,因為無法訪問未來生成的tokens。
于是,作者進行了下圖的實驗,發現在每個解碼步驟中使用局部統計數據計算的局部H2 ,與考慮未來tokens的情況效果差不多(紅線和藍線)。
隨后,作者將這種動態注意力分數計算(有空間限制)定義為一種新的動態的子模塊問題(dynamic submodular type problem):

利用上面的形式定義KV緩存驅逐策略:

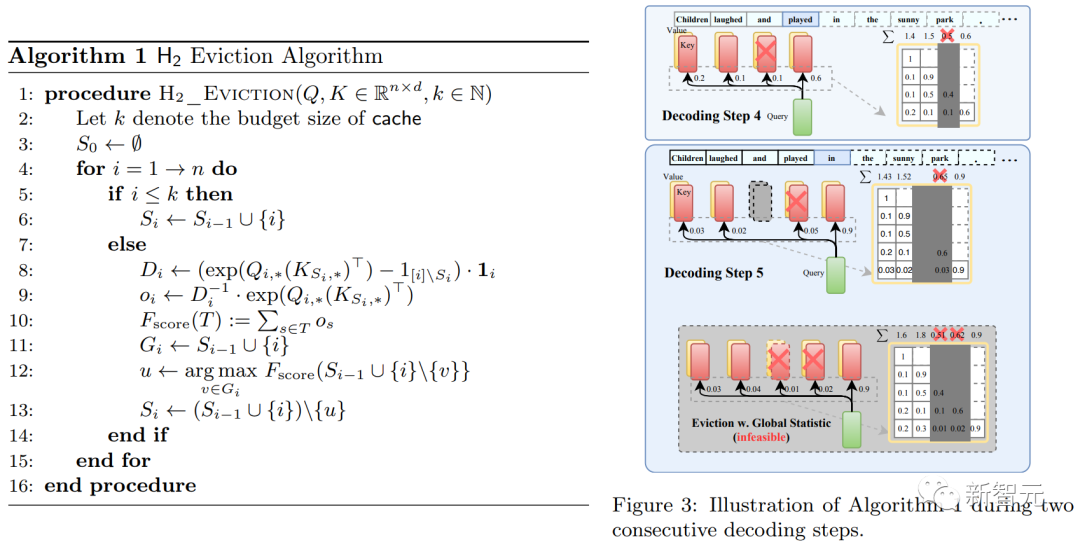
上圖展示了驅逐算法,以及說明性示例。這里假設KV緩存的預算大小為3 ,完成第四個解碼步驟后,根據累積的注意力分數逐出與第三個token關聯的KV嵌入,被逐出的KV嵌入在后續解碼步驟中將不可訪問。
另外,作者還提到了實際實現中的細節。比如,為了保證I/O效率,我們在驅逐存儲的KV時不會交換內存,而是直接填充新添加的KV。
實驗結果
論文的實驗選用了三個具有代表性的LLM模型系列,包括OPT,LLaMA和GPT-NeoX-20B 。
選取了8個評估任務:COPA , MathQA , OpenBookQA , PiQA , RTE , Winogrande , XSUM , CNN/Daily Mail 。
實驗的硬件采用NVIDIA A100 80GB GPU。
考慮到H2O所采用的緩存策略,這里除了完整的KV緩存(Full),還將本地緩存策略(Local)也作為基線方法。
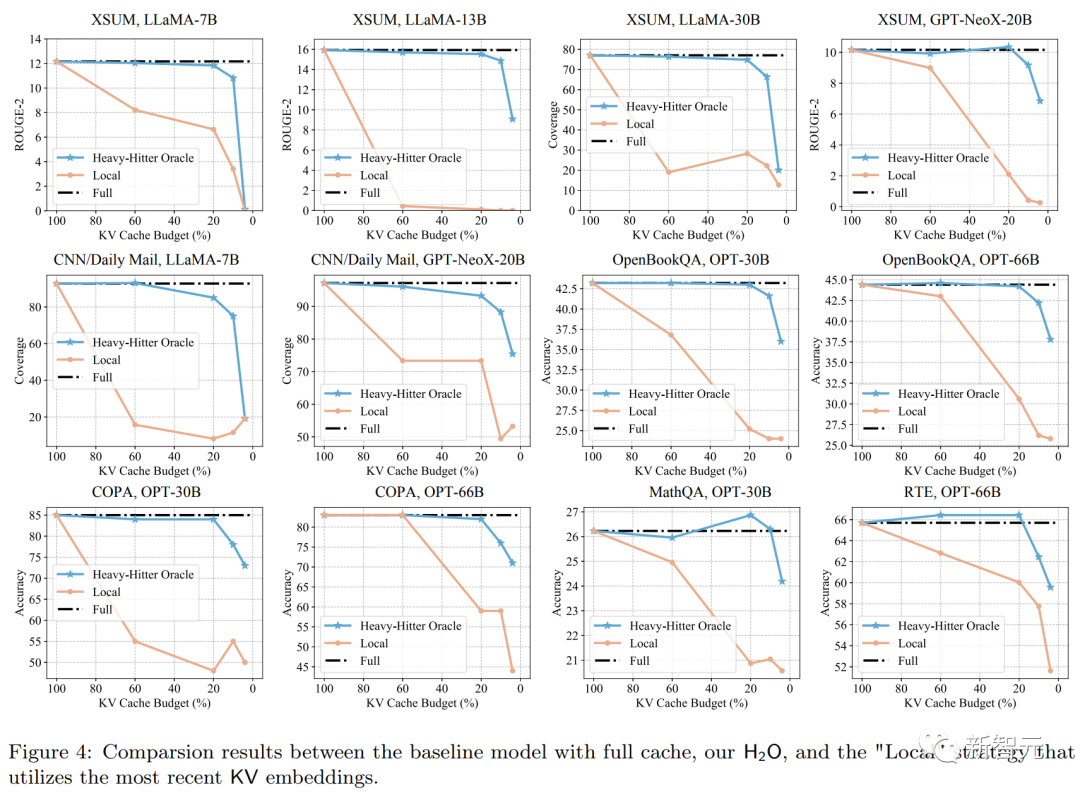
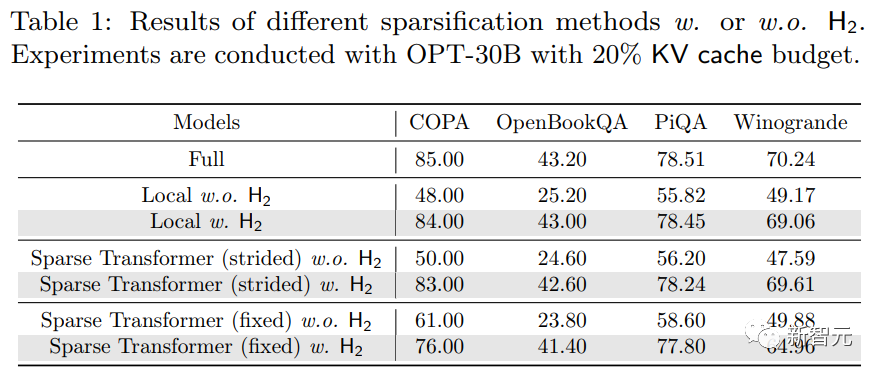
由上面的圖和表可知:在不同的KV緩存預算下,本文提出的方法(H2O)在各種不同條件的測試中都優于Local策略。
同時,在低于20%的KV緩存預算之下,H2O實現了與全KV嵌入模型(Full)相當的性能,且在更具挑戰性的長序列生成任務、XSUM和CNN/Daily Mail中表現良好。






























