國內AI頂會CPAL論文錄用結果放出!共計30篇Oral和60篇Spotlight
大家可能還記得,今年五月份公布的,將由國內大佬馬毅和沈向洋牽頭辦的全新首屆AI學術會議CPAL。
這里我們再介紹一下CPAL到底是個什么會,以防有的讀者時間太久有遺忘——
CPAL(Conference on Parsimony and Learning)名為簡約學術會議,每年舉辦一次。
第一屆CPAL將于2024年1月3日-6日,在香港大學數據科學研究院舉辦。

大會地址:https://cpal.cc
就像名稱明示的那樣,這個年度研究型學術會議注重的就是「簡約」。
第一屆會議一共有兩個軌道(track),一個是論文集軌道(存檔)和一個「最新亮點」軌道(非存檔)。
 圖片
圖片
具體的時間線我們也再復習一下:
 圖片
圖片
可以看到,論文集軌道的論文提交截止日期已經過去了三個多月,「最新亮點」軌道的論文提交截止也已經過去了一個多月。
而在剛剛過去的十一月底,大會發布了兩個軌道的最終評審結果。
最終錄用結果
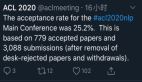
馬毅教授也在推特上發布了最終的結果:9位主講人,16位新星獎獲獎者,共接收30篇論文(論文集軌道)和60篇「最新亮點」軌道中的論文。
馬教授的推特中也附上了每一部分的網址鏈接,點擊即可跳轉到相關頁面。
 圖片
圖片
30篇Oral論文
1. Less is More – Towards parsimonious multi-task models using structured sparsity
作者:Richa Upadhyay, Ronald Phlypo, Rajkumar Saini, Marcus Liwicki
關鍵詞:Multi-task learning, structured sparsity, group sparsity, parameter pruning, semantic segmentation, depth estimation, surface normal estimation
TL;DR:我們提出了一種在多任務環境下利用動態組稀疏性開發簡約模型的方法。
 圖片
圖片
2. Closed-Loop Transcription via Convolutional Sparse Coding
作者:Xili Dai, Ke Chen, Shengbang Tong, Jingyuan Zhang, Xingjian Gao, Mingyang Li, Druv Pai, Yuexiang Zhai, Xiaojun Yuan, Heung-Yeung Shum, Lionel Ni, Yi Ma
關鍵詞:Convolutional Sparse Coding, Inverse Problem, Closed-Loop Transcription
 圖片
圖片
3. Leveraging Sparse Input and Sparse Models: Efficient Distributed Learning in Resource-Constrained Environments
作者:Emmanouil Kariotakis, Grigorios Tsagkatakis, Panagiotis Tsakalides, Anastasios Kyrillidis
關鍵詞:sparse neural network training, efficient training
TL;DR:設計和研究一個系統,利用輸入層和中間層的稀疏性,由資源有限的工作者以分布式方式訓練和運行神經網絡。
 圖片
圖片
4. How to Prune Your Language Model: Recovering Accuracy on the "Sparsity May Cry" Benchmark
作者:Eldar Kurtic, Torsten Hoefler, Dan Alistarh
關鍵詞:pruning, deep learning, benchmarking
TL;DR:我們提供了一套語言模型的剪枝指南,并將其應用于具有挑戰性的Sparsity May Cry基準測試,以恢復準確性。
 圖片
圖片
5. Image Quality Assessment: Integrating Model-centric and Data-centric Approaches
作者:Peibei Cao, Dingquan Li, Kede Ma
關鍵詞:Learning-based IQA, model-centric IQA, data-centric IQA, sampling-worthiness.
 圖片
圖片
6. Jaxpruner: A Concise Library for Sparsity Research
作者:Joo Hyung Lee, Wonpyo Park, Nicole Elyse Mitchell, Jonathan Pilault, Johan Samir Obando Ceron, Han-Byul Kim, Namhoon Lee, Elias Frantar, Yun Long, Amir Yazdanbakhsh, Woohyun Han, Shivani Agrawal, Suvinay Subramanian, Xin Wang, Sheng-Chun Kao, Xingyao Zhang, Trevor Gale, Aart J.C. Bik, Milen Ferev, Zhonglin Han, Hong-Seok Kim, Yann Dauphin, Gintare Karolina Dziugaite, Pablo Samuel Castro, Utku Evci
關鍵詞:jax, sparsity, pruning, quantization, sparse training, efficiency, library, software
TL;DR:本文介紹了 JaxPruner,這是一個用于機器學習研究的、基于JAX的開源剪枝和稀疏訓練庫。
 圖片
圖片
7. NeuroMixGDP: A Neural Collapse-Inspired Random Mixup for Private Data Release
作者:Donghao Li, Yang Cao, Yuan Yao
關鍵詞:Neural Collapse, Differential privacy, Private data publishing, Mixup
TL;DR:本文提出了一種新穎的隱私數據發布框架,稱為 NeuroMixGDP,它利用神經坍縮特征的隨機混合來實現最先進的隱私-效用權衡。
 圖片
圖片
8. Algorithm Design for Online Meta-Learning with Task Boundary Detection
作者:Daouda Sow, Sen Lin, Yingbin Liang, Junshan Zhang
關鍵詞:online meta-learning, task boundary detection, domain shift, dynamic regret, out of distribution detection
TL;DR:我們提出了一種新的算法,用于在不知道任務邊界的非穩態環境中進行與任務無關的在線元學習。
 圖片
圖片
9. Unsupervised Learning of Structured Representation via Closed-Loop Transcription
作者:Shengbang Tong, Xili Dai, Yubei Chen, Mingyang Li, ZENGYI LI, Brent Yi, Yann LeCun, Yi Ma
關鍵詞:Unsupervised/Self-supervised Learning, Closed-Loop Transcription
 圖片
圖片
10. Exploring Minimally Sufficient Representation in Active Learning through Label-Irrelevant Patch Augmentation
作者:Zhiyu Xue, Yinlong Dai, Qi Lei
關鍵詞:Active Learning, Data Augmentation, Minimally Sufficient Representation
 圖片
圖片
11. Probing Biological and Artificial Neural Networks with Task-dependent Neural Manifolds
作者:Michael Kuoch, Chi-Ning Chou, Nikhil Parthasarathy, Joel Dapello, James J. DiCarlo, Haim Sompolinsky, SueYeon Chung
關鍵詞:Computational Neuroscience, Neural Manifolds, Neural Geometry, Representational Geometry, Biologically inspired vision models, Neuro-AI
TL;DR:利用流形容量理論和流形對齊分析,研究和比較獼猴視覺皮層的表征和不同目標訓練的DNN表征。
 圖片
圖片
12. An Adaptive Tangent Feature Perspective of Neural Networks
作者:Daniel LeJeune, Sina Alemohammad
關鍵詞:adaptive, kernel learning, tangent kernel, neural networks, low rank
TL;DR:具有神經網絡結構的自適應特征模型,對權重矩陣施加近似低秩正則化。
 圖片
圖片
13. Balance is Essence: Accelerating Sparse Training via Adaptive Gradient Correction
作者:Bowen Lei, Dongkuan Xu, Ruqi Zhang, Shuren He, Bani Mallick
關鍵詞:Sparse Training, Space-time Co-efficiency, Acceleration, Stability, Gradient Correction
 圖片
圖片
14. Deep Leakage from Model in Federated Learning
作者:Zihao Zhao, Mengen Luo, Wenbo Ding
關鍵詞:Federated learning, distributed learning, privacy leakage
 圖片
圖片
15. Cross-Quality Few-Shot Transfer for Alloy Yield Strength Prediction: A New Materials Science Benchmark and A Sparsity-Oriented Optimization Framework
作者:Xuxi Chen, Tianlong Chen, Everardo Yeriel Olivares, Kate Elder, Scott McCall, Aurelien Perron, Joseph McKeown, Bhavya Kailkhura, Zhangyang Wang, Brian Gallagher
關鍵詞:AI4Science, sparsity, bi-level optimization
 圖片
圖片
16. HRBP: Hardware-friendly Regrouping towards Block-based Pruning for Sparse CNN Training
作者:Haoyu Ma, Chengming Zhang, lizhi xiang, Xiaolong Ma, Geng Yuan, Wenkai Zhang, Shiwei Liu, Tianlong Chen, Dingwen Tao, Yanzhi Wang, Zhangyang Wang, Xiaohui Xie
關鍵詞:efficient training, sparse training, fine-grained structured sparsity, regrouping algorithm
TL;DR:本文提出了一種新穎的細粒度結構剪枝算法,它能在前向和后向傳遞中加速卷積神經網絡的稀疏訓練。
 圖片
圖片
17. Piecewise-Linear Manifolds for Deep Metric Learning
作者:Shubhang Bhatnagar, Narendra Ahuja
關鍵詞:Deep metric learning, Unsupervised representation learning
 圖片
圖片
18. Sparse Activations with Correlated Weights in Cortex-Inspired Neural Networks
作者:Chanwoo Chun, Daniel Lee
關鍵詞:Correlated weights, Biological neural network, Cortex, Neural network gaussian process, Sparse neural network, Bayesian neural network, Generalization theory, Kernel ridge regression, Deep neural network, Random neural network
 圖片
圖片
19. Deep Self-expressive Learning
作者:Chen Zhao, Chun-Guang Li, Wei He, Chong You
關鍵詞:Self-Expressive Model; Subspace Clustering; Manifold Clustering
TL;DR:我們提出了一種「白盒」深度學習模型,它建立在自表達模型的基礎上,具有可解釋性、魯棒性和可擴展性,適用于流形學習和聚類。
 圖片
圖片
20. Investigating the Catastrophic Forgetting in Multimodal Large Language Model Fine-Tuning
作者:Yuexiang Zhai, Shengbang Tong, Xiao Li, Mu Cai, Qing Qu, Yong Jae Lee, Yi Ma
關鍵詞:Multimodal LLM, Supervised Fine-Tuning, Catastrophic Forgetting
TL;DR:監督微調導致多模態大型語言模型的災難性遺忘。
 圖片
圖片
21. Domain Generalization via Nuclear Norm Regularization
作者:Zhenmei Shi, Yifei Ming, Ying Fan, Frederic Sala, Yingyu Liang
關鍵詞:Domain Generalization, Nuclear Norm, Deep Learning
TL;DR:我們提出了一種簡單有效的正則化方法,該方法基于所學特征的核范數,用于領域泛化。
 圖片
圖片
22. FIXED: Frustratingly Easy Domain Generalization with Mixup
作者:Wang Lu, Jindong Wang, Han Yu, Lei Huang, Xiang Zhang, Yiqiang Chen, Xing Xie
關鍵詞:Domain generalization, Data Augmentation, Out-of-distribution generalization
 圖片
圖片
23. HARD: Hyperplane ARrangement Descent
作者:Tianjiao Ding, Liangzu Peng, Rene Vidal
關鍵詞:hyperplane clustering, subspace clustering, generalized principal component analysis
 圖片
圖片
24. Decoding Micromotion in Low-dimensional Latent Spaces from StyleGAN
作者:Qiucheng Wu, Yifan Jiang, Junru Wu, Kai Wang, Eric Zhang, Humphrey Shi, Zhangyang Wang, Shiyu Chang
關鍵詞:generative model, low-rank decomposition
TL;DR:我們的研究表明,在StyleGAN的潛在空間中,我們可以持續找到低維潛在子空間,在這些子空間中,可以為許多有意義的變化(表示為「微情緒」)重建通用的編輯方向。
 圖片
圖片
25. Continual Learning with Dynamic Sparse Training: Exploring Algorithms for Effective Model Updates
作者:Murat Onur Yildirim, Elif Ceren Gok, Ghada Sokar, Decebal Constantin Mocanu, Joaquin Vanschoren
關鍵詞:continual learning, sparse neural networks, dynamic sparse training
TL;DR:我們研究了連續學習中的動態稀疏訓練。
 圖片
圖片
26. Emergence of Segmentation with Minimalistic White-Box Transformers
作者:Yaodong Yu, Tianzhe Chu, Shengbang Tong, Ziyang Wu, Druv Pai, Sam Buchanan, Yi Ma
關鍵詞:white-box transformer, emergence of segmentation properties
TL;DR:白盒transformer只需通過極簡的監督訓練Recipe,就能在網絡的自我注意力圖譜中產生細分特性。
 圖片
圖片
27. Efficiently Disentangle Causal Representations
作者:Yuanpeng Li, Joel Hestness, Mohamed Elhoseiny, Liang Zhao, Kenneth Church
關鍵詞:causal representation learning
28. Sparse Fréchet sufficient dimension reduction via nonconvex optimization
作者:Jiaying Weng, Chenlu Ke, Pei Wang
關鍵詞:Fréchet regression; minimax concave penalty; multitask regression; sufficient dimension reduction; sufficient variable selection.
29. WS-iFSD: Weakly Supervised Incremental Few-shot Object Detection Without Forgetting
作者:Xinyu Gong, Li Yin, Juan-Manuel Perez-Rua, Zhangyang Wang, Zhicheng Yan
關鍵詞:few-shot object detection
TL;DR:我們的iFSD框架采用元學習和弱監督類別增強技術來檢測基礎類別和新類別中的物體,在多個基準測試中的表現明顯優于最先進的方法。
 圖片
圖片
30. PC-X: Profound Clustering via Slow Exemplars
作者:Yuangang Pan, Yinghua Yao, Ivor Tsang
關鍵詞:Deep clustering, interpretable machine learning, Optimization
TL;DR:在本文中,我們設計了一個新的端到端框架,名為「通過慢速示例進行深度聚類」(PC-X),該框架具有內在可解釋性,可普遍適用于各種類型的大規模數據集。
 圖片
圖片
同時還有60篇「最新亮點」軌道中的論文,大家可以前往官網自行瀏覽:https://cpal.cc/spotlight_track/