Linux中的日志分析利器:ail grep awk
一個日志查詢分析的例子
項目發布上線后,接下來需要做什么?開Party,慶祝項目上線。但是Party開到一半,服務運行出了點問題。領導要你馬上調查原因并給出合適的解決辦法。項目才剛上線,日志監控系統都還沒來得及完善。你該怎么處理?

登錄服務器,查詢日志文件定位相關日志,并分析原因。所以在linux服務器上進行日志查詢,成為了必備的技能。
于是你登上了服務器,找到了對應服務的日志文件,輸入了:
tail -f <xx-service>.log但這只能看最新的日志輸出,不能看到過去的某個時間點的日志,或者根據某些特定的字符進行篩選。
于是你輸入了命令:
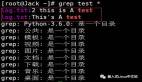
tail -n 20000 <xx-service>.log | grep "ERROR" -A 50 -B 50查看了最近20000行中出現ERROR的日志并包括其前50行和后50行。
一頓操作后你調查出了具體原因,并給出了問題的解決方法。但是你想調查一下問題出現的頻次:
tail -n 2000 <xx-service>.log | grep 'ERROR' | awk '{count++;} END {print "error count:", count}'隨后你分析出了出現問題的更深層次的原因,并出具了根本原因分析報告。
在不具備完善的ELK日志收集分析系統的情況下,日志查詢分析只能依靠Linux基礎的日志查詢分析工具:tail, grep, awk等命令。
tail命令
tail命令用于查看日志文件,常見用法如下:
顯示文件的最后10行:
tail <file name>顯示文件的最后200行:
tail -n 200 <file name>顯示文件第200行開始到末尾的內容:
tail -n +200 <file name> 循環讀取文件:
tail -f <file name>更多tail命令相關的信息,可以通過tail --help命令查看。
grep命令
grep命令用于在一個或多個輸入文件中,搜索與正則匹配的行,并將匹配的行標準輸出。
在日志查詢中,通常用來將tail的輸出結果進行過濾日志,常見用法如下:
(1) 顯示最近2000行日志中,包含Error(區分大小寫)的日志行如包含SystemError,InputError, Error等單詞的行
tail -n 2000 <file name> | grep 'Error' (2) 顯示最近2000行日志中,包含Error單詞(區分大小寫)的日志行:
tail -n 2000 <file name> | grep -w 'Error' -w表示匹配單詞。
(3) 如果不區分大小寫,則可以用以下命令:
tail -n 2000 <file name> | grep -wi 'Error'-i參數則表示不區分大小寫。
(4) 如果需要顯示不包含Error的日志行,則可以用以下命令:
tail -n 2000 postman.log | grep -wiv 'Error'-v表示對匹配的條件取反.
(5) 如果需要進行正則匹配則可以加入-e參數,-E參數則表示擴展正則匹配
tail -n 2000 postman.log | grep -e '.*Error.*'
tail -n 2000 postman.log | grep -E '.*Error.*|.*error.*'(6) -A參數可以包含匹配行的前n行,-B參數則包含匹配行的后n行,上文的提到的命令
tail -n 20000 <xx-service>.log | grep "ERROR" -A 50 -B 50則表示匹配包含ERROR字符的行,以及前50行和后50行。
更多grep命令相關的信息,也可以通過grep --help命令查看。
awk命令
awk是一個文本處理工具,主要用于數據掃描,過濾,統計匯總等。
awk基本語法則是:
awk '<pattern> {<action>} <pattern> {<action>}...'上面提到的一個關于awk的命令則是統計了一下日志中出現ERROR字符的行數。
tail -n 2000 <xx-service>.log | grep 'ERROR' | awk '{count++;} END {print "error count:", count}'更簡單的實現方式則可以通過awk的內置變量實現,如列出ls命令輸出的結果行數:
ls | awk 'END{print NR}'END是awk中的一個關鍵字,后面接的代碼塊只會在讀取完所有數據記錄最后執行一次。與之相反的則是BEGIN,后面接的代碼塊只會在讀取數據記錄前執行一次。
awk是一個十分強大的文本分析工具,如果有日志分析需求,awk足以應對日常所需。更多關于awk的教程可以自行在網上搜索相關資料,或者查看官網教程:https://www.gnu.org/software/gawk/manual/html_node/index.html
總結
總之,基于linux的日志查詢分析,結合tail、grep、awk這三個命令的運用,就完全滿足日常的日志分析需求了。tail控制日志查找范圍,grep進行關鍵詞篩選,awk用于分析統計。