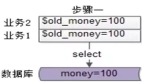
并發情況如何實現加鎖來保證數據一致性?
單體架構下鎖的實現方案
1. ReentrantLock 全局鎖
ReentrantLock(可重入鎖),指的是一個線程再次對已持有的鎖保護的臨界資源時,重入請求將會成功。
簡單的與我們常用的 Synchronized 進行比較:
ReentrantLock | Synchronized | |
鎖實現機制 | 依賴 AQS | 監視器模式 |
靈活性 | 支持響應超時、中斷、嘗試獲取鎖 | 不靈活 |
釋放形式 | 必須顯示調用 unlock () 釋放鎖 | 自動釋放監視器 |
鎖類型 | 公平鎖 & 非公平鎖 | 非公平鎖 |
條件隊列 | 可關聯多個條件隊列 | 關聯一個條件隊列 |
可重入性 | 可重入 | 可重入 |
AQS 機制:如果被請求的共享資源空閑,那么就當前請求資源的線程設置為有效的工作線程,將共享資源通過 CAScompareAndSetState設置為鎖定狀態;如果共享資源被占用,就采用一定的阻塞等待喚醒機制(CLH 變體的 FIFO 雙端隊列)來保證鎖分配。
可重入性:無論是公平鎖還是非公平鎖的情況,加鎖過程會利用一個 state 值
private volatile int state- state 值初始化的時候為 0,表示沒有任何線程持有鎖
- 當有線程來請求該鎖時,state 值會自增 1,同一個線程多次獲取鎖,就會多次 + 1,這就是可重入的概念
- 解鎖也是對 state 值自減 1,一直到 0,此線程對鎖釋放。
public class LockExample {
static int count = 0;
static ReentrantLock lock = new ReentrantLock();
public static void main(String[] args) throws InterruptedException {
Runnable runnable = new Runnable() {
@Override
public void run() {
try {
// 加鎖
lock.lock();
for (int i = 0; i < 10000; i++) {
count++;
}
} catch (Exception e) {
e.printStackTrace();
}
finally {
// 解鎖,放在finally子句中,保證鎖的釋放
lock.unlock();
}
}
};
Thread thread1 = new Thread(runnable);
Thread thread2 = new Thread(runnable);
thread1.start();
thread2.start();
thread1.join();
thread2.join();
System.out.println("count: " + count);
}
}
/**
* 輸出
* count: 20000
*/2. Mysql 行鎖、樂觀鎖
樂觀鎖即是無鎖思想,一般都是基于 CAS 思想實現的,而在 MySQL 中通過 version 版本號 + CAS 無鎖形式實現樂觀鎖;例如 T1,T2 兩個事務一起并發執行時,當 T2 事務執行成功提交后,會對 version+1,所以 T1 事務執行的 version 條件就無法成立了。
對 sql 語句進行加鎖以及狀態機的操作,也可以避免不同線程同時對 count 值訪問導致的數據不一致問題。
// 樂觀鎖 + 狀態機
update
table_name
set
version = version + 1,
count = count + 1
where
id = id AND version = version AND count = [修改前的count值];
// 行鎖 + 狀態機
update
table_name
set
count = count + 1
where
id = id AND count = [修改前的count值]
for update;3. 細粒度的 ReetrantLock 鎖
如果我們直接采用 ReentrantLock 全局加鎖,那么這種情況是一條線程獲取到鎖,整個程序全部的線程來到這里都會阻塞;但是我們在項目里面想要針對每個用戶在操作的時候實現互斥邏輯,所以我們需要更加細粒度的鎖。
public class LockExample {
private static Map<String, Lock> lockMap = new ConcurrentHashMap<>();
public static void lock(String userId) {
// Map中添加細粒度的鎖資源
lockMap.putIfAbsent(userId, new ReentrantLock());
// 從容器中拿鎖并實現加鎖
lockMap.get(userId).lock();
}
public static void unlock(String userId) {
// 先從容器中拿鎖,確保鎖的存在
Lock locak = lockMap.get(userId);
// 釋放鎖
lock.unlock();
}
}弊端:如果每一個用戶請求共享資源,就會加鎖一次,后續該用戶就沒有在登錄過平臺,但是鎖對象會一直存在于內存中,這等價于發生了內存泄漏,所以鎖的超時和淘汰機制機制需要實現。
4. 細粒度的 Synchronized 全局鎖
上面的加鎖機制使用到了鎖容器ConcurrentHashMap,該容易為了線程安全的情況,多以底層還是會用到Synchronized機制,所以有些情況,使用 lockMap 需要加上兩層鎖。
那么我們是不是可以直接使用Synchronized來實現細粒度的鎖機制
public class LockExample {
public static void syncFunc1(Long accountId) {
String lock = new String(accountId + "").intern();
synchronized (lock) {
System.out.println(Thread.currentThread().getName() + "拿到鎖了");
// 模擬業務耗時
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println(Thread.currentThread().getName() + "釋放鎖了");
}
}
public static void syncFunc2(Long accountId) {
String lock = new String(accountId + "").intern();
synchronized (lock) {
System.out.println(Thread.currentThread().getName() + "拿到鎖了");
// 模擬業務耗時
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println(Thread.currentThread().getName() + "釋放鎖了");
}
}
// 使用 Synchronized 來實現更加細粒度的鎖
public static void main(String[] args) {
new Thread(()-> syncFunc1(123456L), "Thread-1").start();
new Thread(()-> syncFunc2(123456L), "Thread-2").start();
}
}
/**
* 打印
* Thread-1拿到鎖了
* Thread-1釋放鎖了
* Thread-2拿到鎖了
* Thread-2釋放鎖了
*/- 從代碼中我們發現實現加鎖的對象其實就是一個與用戶 ID 相關的一個字符串對象,這里可能會有疑問,我每一個新的線程進來,new 的都是一個新的字符串對象,只不過字符串內容一樣,怎么能夠保證可以安全的鎖住共享資源呢;
- 這其實需要歸功于后面的intern()函數的功能;
- intern()函數用于在運行時將字符串添加到堆空間中的字符串常量池中,如果字符串已經存在,返回字符串常量池中的引用。
分布式架構下鎖的實現方案
核心問題:我們需要找到一個多個進程之間所有線程可見的區域來定義這個互斥量。
一個優秀的分布式鎖的實現方案應該滿足如下幾個特性:
- 分布式環境下,可以保證不同進程之間的線程互斥
- 同一時刻,同時只允許一條線程成功獲取到鎖資源
- 保證互斥量的地方需要保證高可用性
- 要保證可以高性能的獲取鎖和釋放鎖
- 可以支持同一線程的鎖重入性
- 具備合理的阻塞機制,競爭鎖失敗的線程要有相應的處理方案
- 支持非阻塞式的獲取鎖。獲取鎖失敗的線程可以直接返回
- 具備合理的鎖失效機制,如超時失效等,可以確保避免死鎖情況出現
Redis 實現分布式鎖
- redis 屬于中間件,可獨立部署;
- 對于不同的 Java 進程來說都是可見的,同時性能也非常可觀
- 依賴與 redis 本身提供的指令setnx key value來實現分布式鎖;區別于普通set指令的是只有當 key 不存在時才會設置成功,key 存在時會返回設置失敗
代碼實例:
// 扣庫存接口
@RequestMapping("/minusInventory")
public String minusInventory(Inventory inventory) {
// 獲取鎖
String lockKey = "lock-" + inventory.getInventoryId();
int timeOut = 100;
Boolean flag = stringRedisTemplate.opsForValue()
.setIfAbsent(lockKey, "竹子-熊貓",timeOut,TimeUnit.SECONDS);
// 加上過期時間,可以保證死鎖也會在一定時間內釋放鎖
stringRedisTemplate.expire(lockKey,timeOut,TimeUnit.SECONDS);
if(!flag){
// 非阻塞式實現
return "服務器繁忙...請稍后重試!!!";
}
// ----只有獲取鎖成功才能執行下述的減庫存業務----
try{
// 查詢庫存信息
Inventory inventoryResult =
inventoryService.selectByPrimaryKey(inventory.getInventoryId());
if (inventoryResult.getShopCount() <= 0) {
return "庫存不足,請聯系賣家....";
}
// 扣減庫存
inventoryResult.setShopCount(inventoryResult.getShopCount() - 1);
int n = inventoryService.updateByPrimaryKeySelective(inventoryResult);
} catch (Exception e) { // 確保業務出現異常也可以釋放鎖,避免死鎖
// 釋放鎖
stringRedisTemplate.delete(lockKey);
}
if (n > 0)
return "端口-" + port + ",庫存扣減成功!!!";
return "端口-" + port + ",庫存扣減失敗!!!";
}
作者:竹子愛熊貓
鏈接:https://juejin.cn/post/7038473714970656775過期時間的合理性分析:
因為對于不同的業務,我們設置的過期時間的長短都會不一樣,太長了不合適,太短了也不合適;
所以我們想到的解決方案是設置一條子線程,給當前鎖資源續命。具體實現是,子線程間隔 2-3s 去查詢一次 key 是否過期,如果還沒有過期則代表業務線程還在執行業務,那么則為該 key 的過期時間加上 5s。
但是為了避免主線程意外死亡后,子線程會一直為其續命,造成 “長生鎖” 的現象,所以將子線程變為主(業務)線程的守護線程,這樣子線程就會跟著主線程一起死亡。
// 續命子線程
public class GuardThread extends Thread {
private static boolean flag = true;
public GuardThread(String lockKey,
int timeOut, StringRedisTemplate stringRedisTemplate){
……
}
@Override
public void run() {
// 開啟循環續命
while (flag){
try {
// 先休眠一半的時間
Thread.sleep(timeOut / 2 * 1000);
}catch (Exception e){
e.printStackTrace();
}
// 時間過了一半之后再去續命
// 先查看key是否過期
Long expire = stringRedisTemplate.getExpire(
lockKey, TimeUnit.SECONDS);
// 如果過期了,代表主線程釋放了鎖
if (expire <= 0){
// 停止循環
flag = false;
}
// 如果還未過期
// 再為則續命一半的時間
stringRedisTemplate.expire(lockKey,expire
+ timeOut/2,TimeUnit.SECONDS);
}
}
}
// 創建子線程為鎖續命
GuardThread guardThread = new GuardThread(lockKey,timeOut,stringRedisTemplate);
// 設置為當前 業務線程 的守護線程
guardThread.setDaemon(true);
guardThread.start();
作者:竹子愛熊貓
鏈接:https://juejin.cn/post/7038473714970656775Redis 主從架構下鎖失效的問題
為了在開發過程保證 Redis 的高可用,會采用主從復制架構做讀寫分離,從而提升 Redis 的吞吐量以及可用性。但是如果一條線程在 redis 主節點上獲取鎖成功之后,主節點還沒有來得及復制給從節點就宕機了,此時另一條線程訪問 redis 就會在從節點上面訪問,同時也獲取鎖成功,這時候臨界資源的訪問就會出現安全性問題了。
解決辦法:
- 紅鎖算法(官方提出的解決方案):多臺獨立的 Redis 同時寫入數據,在鎖失效時間之內,一半以上的機器寫成功則返回獲取鎖成功,失敗的時候釋放掉那些成功的機器上的鎖。但這種做法缺點是成本高需要獨立部署多臺 Redis 節點。
- 額外記錄鎖狀態:再額外通過其他獨立部署的中間件(比如 DB)來記錄鎖狀態,在新線程獲取鎖之前需要先查詢 DB 中的鎖持有記錄,只要當鎖狀態為未持有時再嘗試獲取分布式鎖。但是這種情況缺點顯而易見,獲取鎖的過程實現難度復雜,性能開銷也非常大;另外還需要配合定時器功能更新 DB 中的鎖狀態,保證鎖的合理失效機制。
- 使用 Zookepper 實現
Zookeeper 實現分布式鎖
Zookeeper 數據區別于 redis 的數據,數據是實時同步的,主節點寫入后需要一半以上的節點都寫入才會返回成功。所以如果像電商、教育等類型的項目追求高性能,可以放棄一定的穩定性,推薦使用 redis 實現;例如像金融、銀行、政府等類型的項目,追求高穩定性,可以犧牲一部分性能,推薦使用 Zookeeper 實現。
分布式鎖性能優化
上面加鎖確實解決了并發情況下線程安全的問題,但是我們面對 100w 個用戶同時去搶購 1000 個商品的場景該如何解決呢?
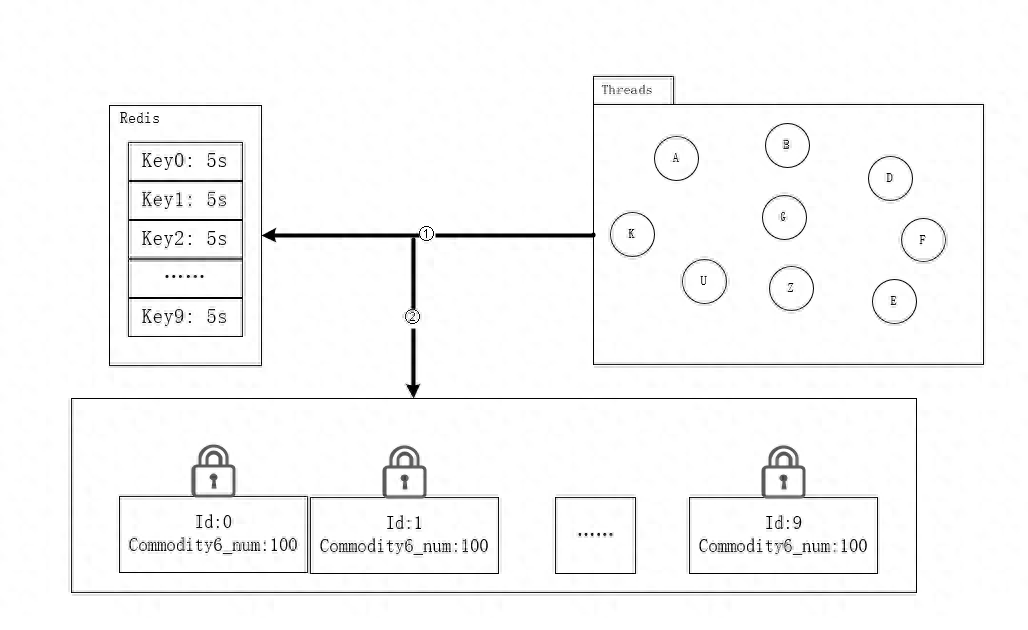
- 可與將共享資源做一下提前預熱,分段分散存儲一份。搶購時間為下午 15:00,提前再 14:30 左右將商品數量分成 10 份,并將每一塊數據進行分別加鎖,來防止并發異常。
- 另外也需要在 redis 中寫入 10 個 key,每一個新的線程進來先隨機的分配一把鎖,然后進行后面的減庫存邏輯,完成之后釋放鎖,以便之后的線程使用。
- 這種分布式鎖的思想就是,將原先一把鎖就可以實現的多線程同步訪問共享資源的功能,為了提高瞬時情況下多線程的訪問速度,還需要保證并發安全的情況下一種實現方式。
參考文章:
1. https://juejin.cn/post/7236213437800890423
2. https://juejin.cn/post/7038473714970656775
3. https://tech.meituan.com/2019/12/05/aqs-theory-and-apply.html
作者:京東科技 焦澤斌
來源:京東云開發者社區 轉載請注明來源