?概覽數據庫索引創建
數據庫表是一組行/記錄。然而,這些行并不是以表的形式物理存儲的,它們存儲在塊上的數據頁中。要在這些數據頁中找到特定記錄需要掃描多個文件。為了改進這一點,我們創建索引。索引是小型的引用表,用于根據索引值存儲對行的引用。
索引是一種使數據檢索更快的數據庫對象。 但是,索引的創建也需要時間,并且會占用額外的空間。因此,在選擇正確的索引創建策略時,我們必須審慎選擇。

RUM猜想
類似于CAP定理,RUM猜想指出 —— 我們無法設計一個存儲系統的訪問方法,使其在以下三個方面都最優:
讀、更新和內存。
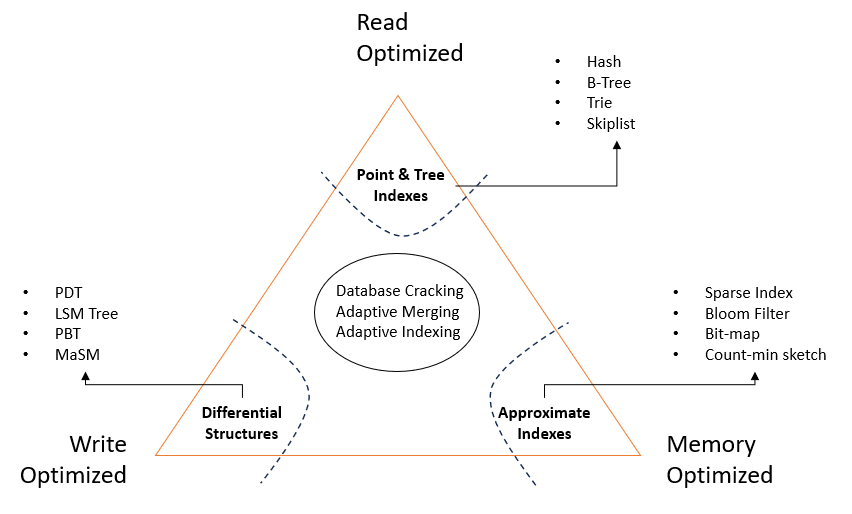
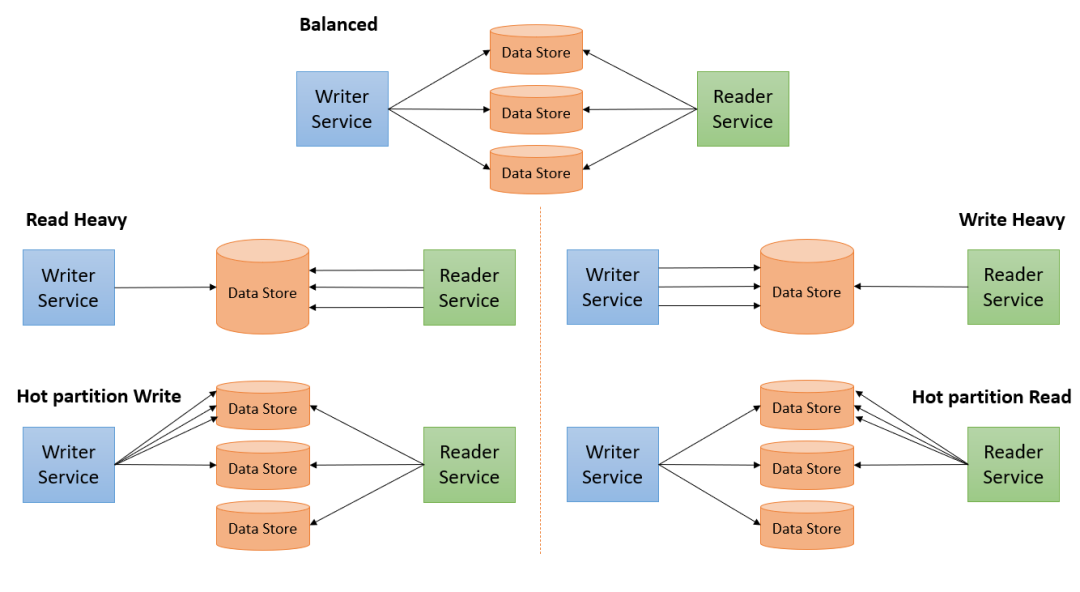
讀取、更新、內存 — 以兩者優化為代價的第三者。
- 讀取開銷: 定義為總讀取數據量(主要 + 輔助)與預期讀取的主要數據量之間的比率。通過讀取放大來衡量。
- 更新開銷: 定義為總寫入數據量(主要 + 輔助)與預期更新的主要數據量之間的比率。通過寫入放大來衡量。
根據上圖中的讀取和寫入模式,數據庫將分為以下5類:
- 平衡 — 讀取和寫入均勻分布。很少發生。
- 讀取優化 — 寫入較少,讀取較多(分析工作負載)
- 寫入優化 — 寫入較多,讀取較少(事務工作負載)
- 熱分區讀取 — 來自某些數據部分的讀取較多
- 熱分區寫入 — 向某些部分的寫入較多
索引類型
(1) 無索引
實現:Kafka(可以看作純粹是WAL)、數據倉庫
(2) 主鍵索引
主鍵 = 分區鍵 + (可選)排序鍵
- 分區鍵 = “什么節點”
- 排序鍵 = 滿足唯一性約束的剩余內容
有各種分區策略,其中一些如下:
- 哈希分區(也稱為“一致性哈希”)
- 范圍分區?隨機數
聚簇索引 — 物理數據組織
非聚簇索引 — 邏輯組織
(3) KV存儲(哈希表)
- 哈希分區在這里非常有意義
- 只能在RAM中進行,這就是為什么我們在PostgreSQL等數據庫中看不到它
- 實現:Memcache、Redis
(4) B樹 — 讀取優化
- 實現:DynamoDB、PostgreSQL
- 變體:Bw-tree 等(查看 Alex Petrov 的《Database Internals》)
- 它是許多數據庫中的默認索引。
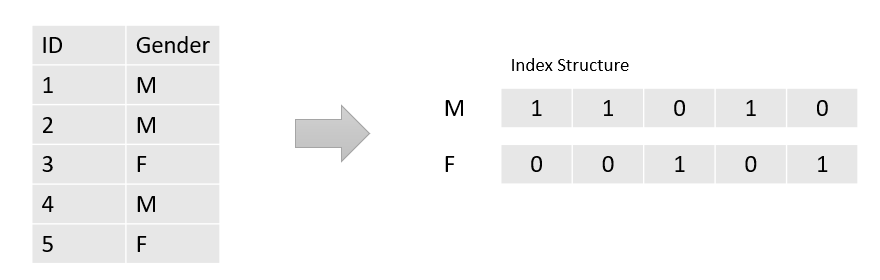
(5) 位圖索引
用于OLAP的讀取和內存優化。
(6) LSM樹 — 寫入優化
實現:Cassandra、Spanner
(7) 二級索引 — 更多讀取優化
- 本地二級索引 — 這是“默認”/“正常”的二級索引
- 全局二級索引 - 可能對于讀取重型的鍵范圍查詢和無法避免的散列收集最有意義
- 實現:DynamoDB,可能是Spanner
(8) 多維索引
- 連接索引
- R樹(實現:PostgreSQL)
- 四叉樹(實現:Elasticsearch)
- 地理哈希(實現:Redis)
(9) 倒排索引
實現:ElasticSearch、PostgreSQL、Redis
示例場景:Twitter 等社交媒體站點的文本搜索,google.com,GitHub
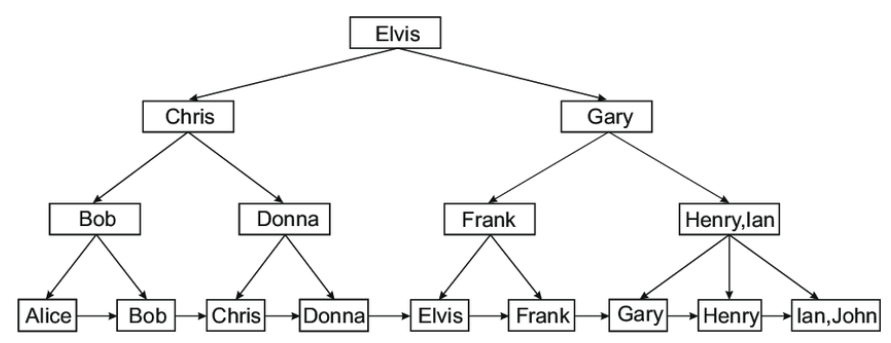
(10) 跳躍表
實現:Redis(僅)
示例場景:游戲排行榜
(11) 向量索引
實現:Pinecone、Facebook 的 Faiss、PlanetScale 的 MySQL 分支、Redis
示例場景:機器學習問題
(12) 數據立方體和物化視圖
實現:數據倉庫,支持OLAP的數據庫
(13) Count-min sketch
- 就RUM而言,以極端OLAP讀取延遲為代價換取精度
- 實現:Flink、AWS Firehose、Druid、Spark streams、Redis
對于分布式系統,還有其他有趣的權衡。其中之一是PACELC,它說:如果是分區,選擇可用性和一致性之間的折衷,否則選擇延遲和一致性之間的折衷。有許多級別的一致性可供折衷選擇(以及隔離級別)。
(14) 一致性級別
- 強一致性
- 最終一致性
- 一致前綴
- 單調讀取