數據庫索引技術之B樹索引
本文轉載自微信公眾號「小菜學編程」,作者fasionchan 。轉載本文請聯系小菜學編程公眾號。
前面我們介紹了 哈希索引 和 LSM樹索引 ,它們都基于日志結構式的數據文件。雖然工程界對這種索引的認可度正與日俱增,但還遠不是最受歡迎的索引技術。
那么,目前應用最廣的索引技術又是什么呢?
您可能早就有所耳聞——這就是本文要探討的 B樹( b-tree )索引。B樹可以說是數據庫索引技術中的武林盟主,能夠幾十年長盛不衰,必定有它自己的獨門秘訣。
索引結構
跟我們在 LSM樹 一節中提到的 SSTable 一樣,B樹也是將數據組織成有序形式,因此支持范圍查詢。盡管如此,它們的底層結構卻完全不同,B樹有自己獨特的設計哲學。
日志結構式索引將數據分成大小可調節的分段,通常是幾兆或更大,然后再順序寫入磁盤。而B樹則是以 塊( block )為單位來組織數據,塊大小是固定的,通常是 4KB ,也可以更大。這種設計更貼近磁盤的硬件結構,因為磁盤也是以塊為單位來讀寫數據的。
出于性能方面考慮,計算機通常以一定字節數(如 4KB )為單位來存取數據。在不同的場景有不同的叫法:磁盤數據一般稱為 塊 ( block ),內存數據一般稱為 頁( page )。這兩種場景數據庫均有涉及,因而術語可以混用。
磁盤中的每個數據塊都有一個唯一的地址,因此數據塊間可以互相引用,有點像內存中的指針。因此,我們可以用這種方式,將數據塊組織成一棵樹——B樹( b-tree )。
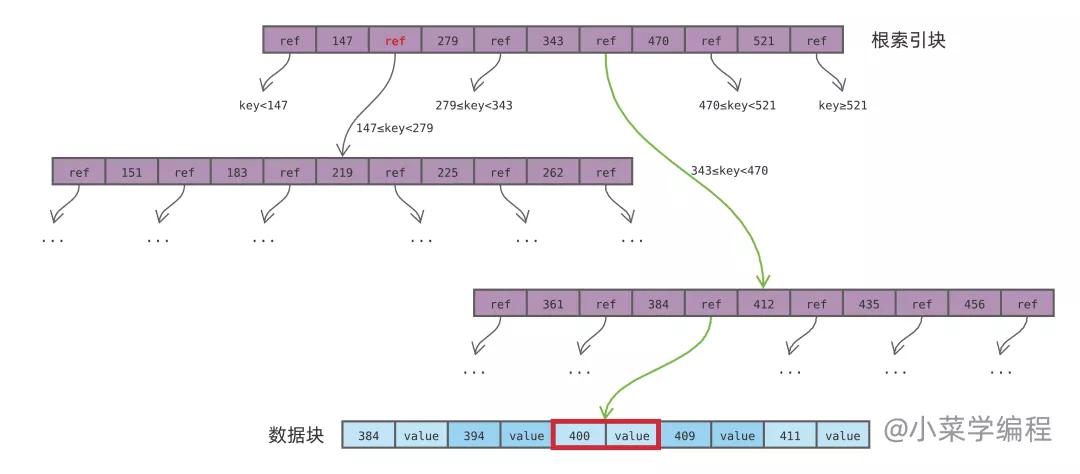
如上圖,為簡化討論,我們假設數據庫記錄只有兩個字段:一個是索引鍵,類型為整數;另一個是值。數據按索引鍵排序,依次保存在一個數據塊中,如藍色數據塊所示。
紫色部分數據塊為索引,它將索引鍵的范圍劃分為多個區間;每個區間保存著另一個數據塊的地址( ref ),表示該范圍內的數據,可以通過 ref 指向的數據塊找到。上圖中紅色的 ref 表示, 之間的數據,可以通過其左下方的另一個索引數據塊找到。
如果子范圍內的數據記錄還很多,單個數據塊容納不下,ref 便指向另一個索引塊,進一步將數據范圍分小;如果子范圍內的數據記錄不多,一個數據塊就能裝下,ref 便直接指向數據。
這樣一來,ref 就將數據塊組織成一棵多叉樹,數據塊主要分為兩種:
- 一種用于保存數據記錄,如上圖藍色部分,位于樹的 葉子節點 ,簡稱 數據塊 ;
- 一種用于保存索引,如上圖紫色部分,位于樹的的 內部節點,簡稱 索引塊 ;
從樹的根節點索引塊出發,根據數據鍵所在范圍的 ref 逐層往下找,即可定位到數據記錄。舉個例子,當查詢鍵為 400 的記錄時,搜索路徑如綠色箭頭線所示:
從根索引塊出發,400 落在區間 [343, 470) ,根據該區間 ref 找到下一級;
來到下一個索引塊,400 落在區間 [384, 412) ,根據該區間 ref 找到下一級;
最終來到藍色的數據塊,待查找的數據記錄就在里面;
范圍查詢
為了支持范圍查詢,數據庫將數據記錄排過序后才保存到數據塊,相鄰數據塊間則通過雙向鏈表指針連接在一起。
這樣一來,數據庫只要先定位邊界元素,然后以此為起點遍歷數據即可:
如果查詢條件為小于,則從后往前遍歷數據;
如果查詢條件為大于,則從前往后遍歷數據;
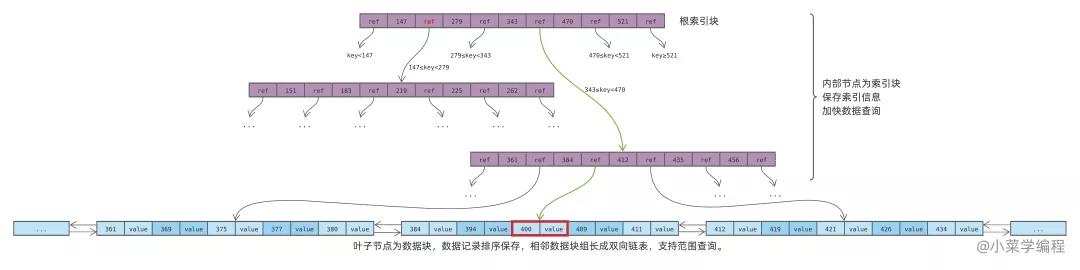
如上圖,以查詢大于等于 400 且小于 420 的數據為例:
數據庫定位到鍵值為 400 的數據記錄,如紅框所示;
數據庫檢查本數據塊內 400 以后的記錄,滿足小于 420 則取出;
數據庫根據鏈表指針找到下一個數據塊,繼續檢查里面的數據記錄,滿足小于 420 則取出;
數據庫重復步驟 3 ,逐個往后遍歷數據塊,直到有數據記錄大于等于 420 ;
分支因子
我們注意到,B樹是一種多叉樹。那么,為什么不能用最簡單的二叉樹呢?
實際上,每個樹節點最多可以有多少個分叉,是樹的一個非常重要的特性—— 分支因子( branching factor )。我們知道,在數據記錄數一定的前提下,樹的分支因子越大,高度越低。
我們使用排序樹來查找數據時,從根節點開始不斷搜索,最終來到葉子節點。換句話講,我們需要檢查的節點數,其實就是樹的高度。
而數據庫數據需要持久化并保存在磁盤里面,那磁盤有什么特點呢?
- 磁盤 IO 比較慢,非順序的磁盤 IO 更是如此;
- 磁盤 IO 以 塊( block )為數據單位,單次 IO 總是讀寫整個塊;
在排序樹中搜索數據,顯然是離散讀,而不是順序讀。因為我們無法保證 ref 指向的數據塊就在當前塊后面,磁盤通常只能重新 尋道( seek )后才能讀取數據。由于磁盤尋道很慢很慢,IO 次數必須盡量減少,因此樹的高度應該盡量壓低。
另一方面,磁盤以塊為單位讀寫數據,一個塊可以保存很多分支信息。如果一個塊只保存兩個分支,那就浪費了。因為就算只保存兩個分支,讀的時候還是必須整塊讀,開銷是一樣的。因此,不如盡量提高分支數,這樣還能減低樹的高度,進而減少 IO 次數。
通常 4KB 大的數據塊可以保存多達 500 個分支,如果樹的高度為 3 ,可以支撐多達 個數據,超過一億。有意思的是數據庫根索引塊通常緩存在內存中,這樣只需 2 次 IO 操作即可從超過 1 億數據中找到想要的那個。
綜上所述,B樹幾乎就是為磁盤量身定制的數據結構,它充分地利用了磁盤的特點:
磁盤以塊為單位讀寫數據,B樹就以塊為節點,組織成多叉樹;
磁盤 IO 很慢,B樹就通過提高分支因子,降低樹的高度,減少 IO 次數;
寫操作
數據庫寫操作分為兩種,一種是 更新( update ),一種是 插入( insert )。
如果要更新數據庫中的已有記錄,先搜索B樹找到包含該記錄的數據塊(葉子節點)。然后修改數據塊的記錄值,再將個數據塊寫回磁盤。由于數據塊只是內容改變了,位置不變,因此B樹中任何對該數據塊的引用仍然有效。
如果要插入一條新記錄,同樣先搜索B樹,找到數據范圍包含新記錄的數據塊(葉子節點)。如果數據塊還有足夠空間,就將新記錄添加進入并保存到磁盤即可。如果數據塊空閑空間不足,則需要將其分裂為兩個:
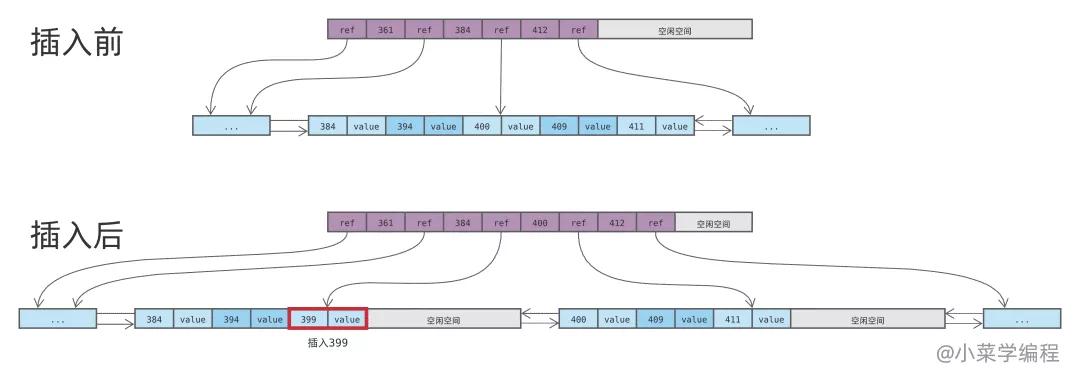
如上圖,以插入 399 為例:由于目標數據塊已經存滿,需要將其分裂為兩個。分裂后的數據塊都只有一半數據,新記錄保存在其中的一個。
如果新記錄的鍵相對較小,則保存在左邊的數據塊;否則就保存在右邊的數據塊。399 跟該范圍的其他數據相比較小,因此保存在左邊數據塊。
由于數據塊發生了分裂,因此它們的父節點需要更新,以便記錄最新的數據范圍和分支信息。
B樹算法可以保證樹的 平衡( balanced ):一棵包含 個鍵的B樹,高度不超過 ,否則樹的性能會大打折扣。通常一棵 3 層或 4 層深的B樹即可容納數據庫所有數據,因此查詢時無須遍歷太多數據塊,性能相對較好。
至此,三種主流的數據庫索引技術已經全部介紹完畢。除了本節介紹的B樹索引,其他兩種分別是:
- 哈希索引
- LSM樹索引