理想汽車基于Flink on K8s的數據集成實踐

一、數據集成的發展與現狀
理想汽車數據集成的發展經歷了四個階段:

第一階段:在 2020 年 7 月基于 DataX 構建了離線數據交換能力。
第二階段:在 2021 年 7 月,構建了基于 Flink 的實時處理平臺,在這兩個階段,還沒有一個真正的數據集成的產品。
第三階段:2022 年 9 月,開始建設數據集成平臺,構建了第一個數據集成鏈路,實現 Kafka 到 Hive 的數據鏈路。
第四階段:2023 年 4 月,在原來實時處理能力的基礎上擴展了離線集成能力,實現了批流數據的統一。
早期,理想還沒有統一的數據集成平臺,數據產品紛雜。

TiDB、MySQL、StarRocks、MongoDB 等數據傳輸到下游,是通過 DataX 來實現的;而 Kafka、Oracle 等數據傳輸具備流特性的數據又是通過 Flink 實現的;同時,比如 Hive 等一些數據傳輸是通過寫 Spark SQL 來實現的;還有一些數據庫,如 TiDB、Oracle 是通過數據庫自己的引擎進行數據傳輸。
基于以上數據形態,業務方在使用產品時存在如下一些痛點:

- 產品能力缺失。需要在多套平臺之間切換,沒有直接可落地的產品,需要開發團隊寫代碼。
- 多套開發語言。無論是 Flink、Spark 還是 DataX 等等,每一個引擎都有其特有的配置,需要同時了解多套開發語音和不同的開發細節。
- 資源共享難。由于批流使用不同的引擎,由不同的團隊開發,底層的計算和存儲資源很難共享。
- 資源利用率低。正是由于資源共享難,又引發了另外一個問題,就是資源利用率低,且存在不均衡的狀況。比如實時計算集群,是長期運行的任務,其計算資源經常吃緊,但是存儲資源基本上處于沒有使用的狀態。

根據業務痛點,我們總結出了三大需求:
首先是統一平臺,屏蔽各種異構數據源之間不同傳輸引擎的差異。
第二是統一計算引擎,將批式、流式用一套引擎實現。
第三是存算分離,能夠在計算層和存儲層,按照業務的需求進行獨立的彈性伸縮。

為了滿足上述需求,我們選擇使用 Fink 作為計算引擎,其批流一體的計算引擎,讓我們在處理批式、流式時可以做到無縫切換。同時,Flink 基于 K8s 的云原生的能力也能夠幫助我們實現計算資源和存儲資源的彈性擴縮容。
我們的產品已經在業務上有很多應用實例。對接了包括服務器端的日志類數據,比如 Oracle、MySQL、TiDB 等有 binlog 的業務數據傳輸到下游。同時,車端、云端還有工廠的一些埋點和信號的數據,也通過集成平臺實現了數據傳輸。
計算方面,在傳輸能力上,可以實現流式和批式的數據處理轉換,支持并行讀取和并行寫入的能力,以及對于異構數據源不同類型數據轉換的能力,業務用戶不再需要去了解不同產品的細節。在產品運維能力上,包括任務的管理、權限控制、監控告警、日志采集等等,覆蓋了任務的全部生命周期。最終落到下游各種數據存儲。

二、數據集成的落地實踐
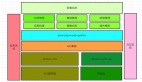
1、數據集成平臺架構

存儲層:采用 JuiceFS+BOS 的方式,同時借助 K8s 本身 node 節點的一些本地存儲能力,為計算引擎提供相應的存儲能力。
計算層:基于 Flink 的內核,擴展了各種 connector,最終封裝成了一個標準化鏡像,通過 Flink Operator 來調取鏡像,把任務提交到 K8s 的集群當中。同時,配備了 Flink 的 history 的服務,這樣用戶可以在任務出現異常或任務結束時對任務的歷史狀況進行分析。Flink Operator 是一個定義在 Flink 上的 CRD,它通過 K8s 的 API server 對外提供標準化的 API。上面封裝了一個中間層,對下使用 K8s 的 API server,對產品則封裝了標準化的 API,屏蔽各個層的依賴關系,還承接了任務的編排和任務生命周期的管理。
2、設計模型
數據集成的設計模型如下圖所示,通過定義各種 source 和 sink 的插件來實現數據傳輸的轉換。

下面封裝的 API,用戶只需要定義 source 和要傳輸的數據內容,以及寫到哪一個 sink,就可以完成一個 transform 的過程。

例如,假設我們已經有了 TiDB、OceanBase、Hive、Kafka 等 sink 的鏈路,當增加一個新的 MySQL 的 connector 時,就創建了這一套插件的一組數據傳輸能力。這樣就可以快速實現各種場景的數據落地。
3、典型場景

在離線集成場景中,首先獲取庫表的關聯關系。數據之間的增量和全量的數據同步,通過調度平臺進行統一的調度處理。

在過去使用 OceanBase 到 Hive 的鏈路,數據量大時 OB 經常出現 time out,因為 OB 本身設置了 time out 時間。我們的解決方法是,首先獲取 OB 的數據結構,分析主鍵及分區選擇分片字段,計算出這個字段的最大值、最小值,以及這一批次的數據量,然后使用這三個信息,合理設置拉取這個數據的 size。之后, Flink 就可以基于這個 size 的大小并行地去拉取。保證每一次拉取的數據量不會特別的多,這樣就解決了數據出現 time out 的問題

過去的實時傳輸鏈路,用戶需要跨多個平臺去做,開發流程長。并且,用戶需要手動創建表,開發復雜。

有了數據集成平臺之后,就省去了上面一系列的人工過程。通過集成平臺配置 source、sink,就可以實現數據流轉。
對于 Hive 的表,經常會有數據分區。這里提供了幾種方式來生成 Hive 的分區,可以基于數據、基于處理或基于元數據時間來進行分區。基于元數據時間分區的好處是可以避免生成太多的 Hive 的小碎文件,因為消費數據在不出現延遲的情況下,基本上一個分區的數據都會寫到同一個 Hive 的 partition 里面。同時,開啟了 Kafka 的自動感知分區的能力,比如當 Kafka 數據暴增時,Kafka 的 topic 的分區進行增加,自動感知就非常有必要。

上圖展示的是一個 Oracle 傳輸入流的場景。借助 Flink CDC 的能力,在全量階段,通過設置多個并行度來讀全量數據,當全量數據讀取完成后,Flink 會通過自動切換能力切換到增量模式。增量模式會選擇其中的某一個 task manager,去讀取增量的數據。
4、異構數據源

不同類型的數據庫支持的數據類型存在差異,我們很難在這個過程當一一記住該把哪個類型轉換到哪個類型。因此,在數據集成平臺上,我們把數據源的類型映射成 Flink 類型,把數據目標的類型也映射成 Flink 類型。最終,都通過 Flink 的類型進行統一的處理轉換。映射過程用戶是不需要關注的。
5、SQL 形式的過濾條件

這個轉換過程中,需要過濾一些常用的 where 條件,這里提供了常用的一些函數。
三、數據集成云原生的落地實踐

K8s 云原生方案的落地主要考慮了四大關鍵點,接下來逐一展開介紹。
1、方案選型

選型方面,選擇使用 Flink Operator 進行任務管理。首先,Flink Operator 可以方便地進行管理集群。它封裝了 K8s 的一個應用,可以擴展 API 來實現配置和創建應用實例。采用聲明式地提交。同時配備了集成的 ingress,可以通過 ingress 來實現配置 Flink 的 web UI,在運行過程中通過 web UI 監控任務的狀態,或者查看運行日志。Flink Operator 實現了作業全生命周期的管理,可以實現運行和暫停應用程序,有狀態、無狀態的應用升級,以及定時觸發和管理 CheckPoint 點。還可以做到回滾。

上圖展示了 Flink Operator 的處理過程。首先,在平臺上注冊 Flink Operator,也就是在 K8s 集群中創建一個 Flink deployment 的 CRD。之后就可以使用這個 CRD 去創建相應的資源。一個 yaml 文件提交到 K8s 集群之后,K8s 的 API 調用 CRD 創建 FlinkDeployment。然后由 Flink Operator 創建 Flink 的 Deployment,并創建相應的 TaskManager。同時,Operator 會監聽 FlinkDeployment 的狀態,其實質上是監聽 JobManagerPod 的狀態,并更新到 Operator 中。如果任務失敗,會嘗試重新調起。
2、狀態判斷及日志采集

各種任務的狀態已經被記錄到了 FlinkDeployment 中,通過 watch 的方式去監聽 Flink K8s API server,就可以捕獲任務各個事件的狀態。同時,還會 watch 每一個 JobManager 和 TaskManager 的 pod,將 pod 狀態和名稱來作為日志標題。已經有了任務運行的狀態,為什么還要采集 pod 的狀態呢?因為實時任務是一個持久化運行的任務,pod 可能會在某一個時間節點,由于一些原因導致了死亡。對于已經死亡的 pod,不需要看到所有的日志的狀態。通過標記 pod 的狀態,來描述這一個日志是一個有效還是一個無效的日志。在每一個 K8s 的 node 節點上部署了 Agent,通過 Agent 采集某每一個 pod 的日志作為下游的轉換日志。

上圖描繪出了狀態轉換關系。Failed、Finished、Canceled 和 Suspended 這四個狀態是最終任務結束的狀態類型。如果出現 Failed,下游會進行相應的告警。
3、監控告警

我們對每一個任務都給用戶提供了配置告警的方式,當用戶啟動任務的時候,任務會把相應的指標上報到 Prometheus,Prometheus 會周期性地去采集和運算,如果告警指標沒有被觸發,就會處于靜默的狀態。如果告警指標被觸發,就會觸發一條告警發送給相應的用戶。用戶就可以基于告警采取相應的處理。
4、共享存儲

共享存儲使用了 JuiceFS。每一個 pod 都會通過掛載本地 CSI 的方式把 JuiceFS 掛載到本地,形成一個本地的存儲目錄。
Flink 的任務需要去做周期性的 checkpoint,checkpoint 會被持久化到 JuiceFS 里面。在任務運行時,Flink 配置了重啟的策略,Operator 也會有一些重啟的策略,當任務出現異常的時候會進行任務的重啟,在重啟時會找到最近一次 checkpoint 點進行重啟。另外,Flink Operator 可以實現任務的無狀態和有狀態的升級,升級時,如果 yaml 狀態發生了變更,就會去找到最新的 checkpoint 點進行任務重啟。
Flink 運行期間的狀態信息和存檔信息也會記錄在 JuiceFS 里面,會由 Flink 的 history 來提供查看。
四、未來規劃

首先,支持更多的數據源,實現更多異構數據源之間的轉換。
第二,彈性伸縮能力方面,目前雖然使用了 K8s 的能力,但是對資源的彈性伸縮等問題還沒有進行完整的落地,后續希望在彈性伸縮能力上進行一些增強。
第三,進一步提升海量數據的傳輸性能。
最后,對于批處理任務,目前 Flink 存在一個缺陷,無法進行謂詞下推,導致在做有 where 條件的任務時會把全量數據拉到 Flink 內存里面,再進行 where 條件的過濾。