Native Flink on Kubernetes 在小紅書的實踐
摘要:本文整理自小紅書數據流團隊資深研發工程師何軍在 Flink Forward Asia 2021 平臺建設專場的演講,介紹了小紅書基于 K8s 管理 Flink 任務的建設過程,以及往 Native Flink on K8s 方案遷移過程的一些實踐經驗。主要內容包括:
- 多云部署架構
- 業務場景
- Helm 集群管理模式
- Native Flink on Kubernetes
- 流批一體作業管控平臺
- 未來展望
一、多云部署架構
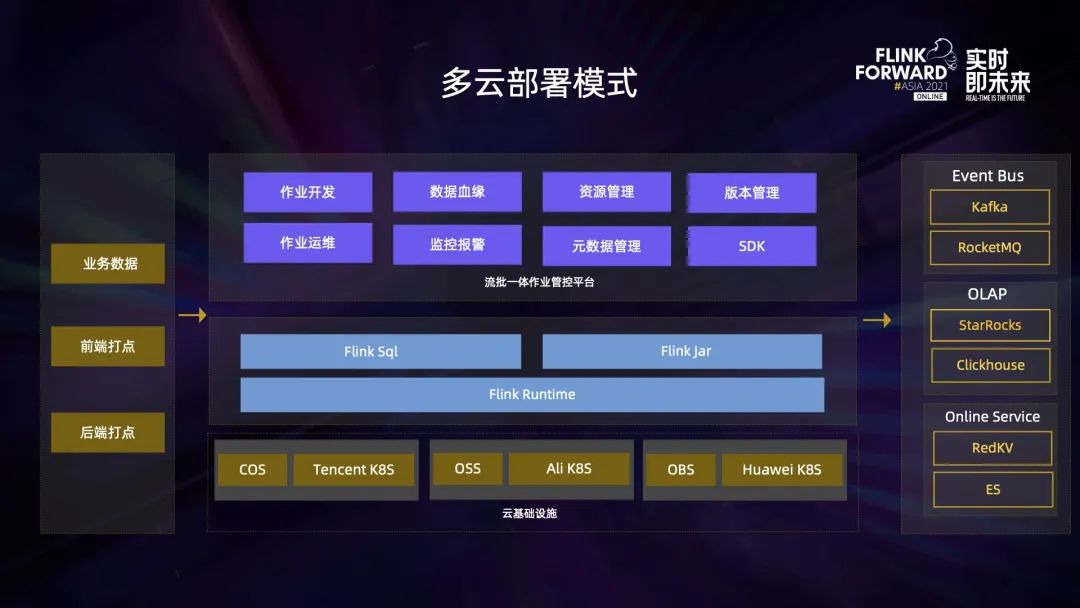
上圖是當前 Flink 集群多云部署模式圖。業務數據分散在各個云廠商之上,為了適配業務數據處理,Flink 集群自然也進行了多云部署。這些云存儲產品一方面用于內部的離線數據存儲,另外一方面會用于 Flink 做 checkpoint 存儲使用。
在這些云基礎設施之上,我們搭建了 Flink 引擎支持 SQL 及 JAR 任務的運行,得益于之前做的一項推動任務 SQL 化的工作,當前內部 SQL 任務和 JAR 任務比例已經達到了 9:1。
在此之上是流批一體作業管控平臺,它主要有以下幾個功能:作業開發運維、任務監控報警、任務版本管理、數據血緣分析、元數據管理、資源管理等。
平臺數據輸入主要有以下三個部分,第一部分是業務數據,存在于業務內部的 DB 系統里比如 MySQL 或者 MongoDB,還有一部分是前后端打點數據,前端打點主要是用戶在小紅書 APP 端的行為日志,后端打點主要是 APP 內部應用程序性能指標相關的數據。這些數據經過 Flink 集群處理之后,會輸出到三個主要業務場景中,首先是消息總線,比如 Kafka 集群以及 RocketMQ 集群,其次會輸出到 olap 引擎中,比如 StarRocks 或 Clickhouse,最后會輸出到在線系統,比如 Redkv 或者 ES 供一些在線查詢使用。
二、業務場景
Flink 在小紅書內部的應用場景有很多,比如實時反欺詐監控、實時數倉、實時算法推薦、實時數據傳輸。本章會著重介紹一下其中兩個場景。
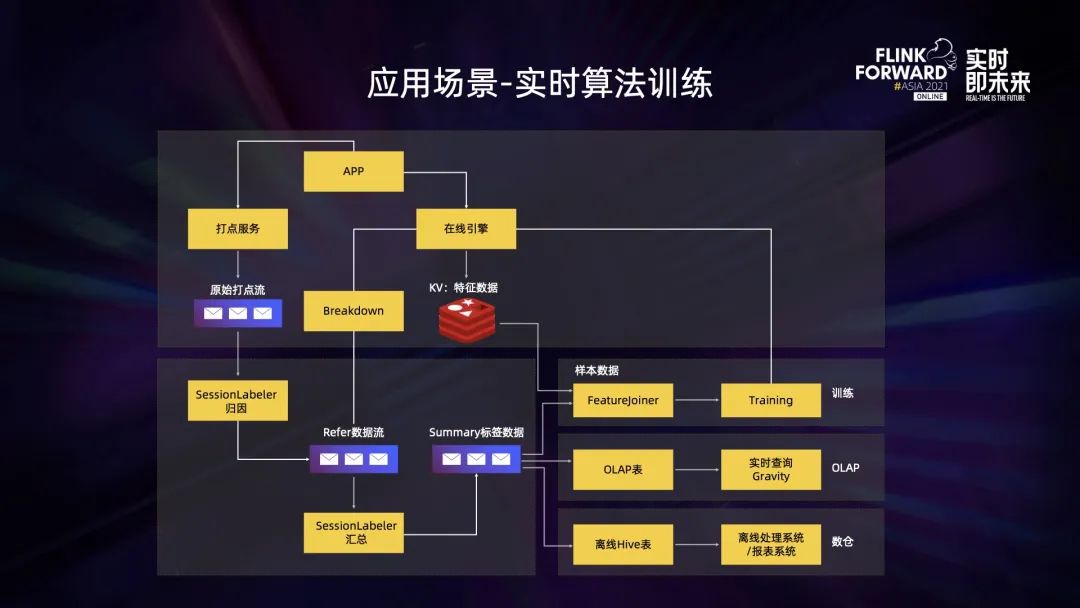
第一個是實時推薦算法訓練。上圖是推薦算法訓練的執行流程。
Flink 集群先接收打點服務采集過來的原始數據,對這一部分數據進行歸因并將它寫入到 Kafka 集群,之后會再有一個 Flink 任務對這部分數據再做一次匯總,然后得到一個 Summary 的標簽數據,針對這個標簽數據,后面還有三條實時處理路徑:
- 第一,Summary 標簽數據會和推薦引擎推薦出來筆記的特征數據進行關聯,這個關聯也是在 Flink 任務中進行的,內部稱其為 FeatureJoiner 任務。接著會產出一個算法訓練的樣本,這個樣本經過算法訓練之后產出一個推薦模型,而這個模型最終會反饋到實時推薦引擎中。
- 第二,Summary 標簽數據會通過 Flink 實時寫到 OLAP 引擎中,比如寫到 Hologres 或 Clickhouse 中。
- 最后, Summary 標簽數據會通過 Flink 寫入到離線 Hive 表中,提供給后續離線報表使用。
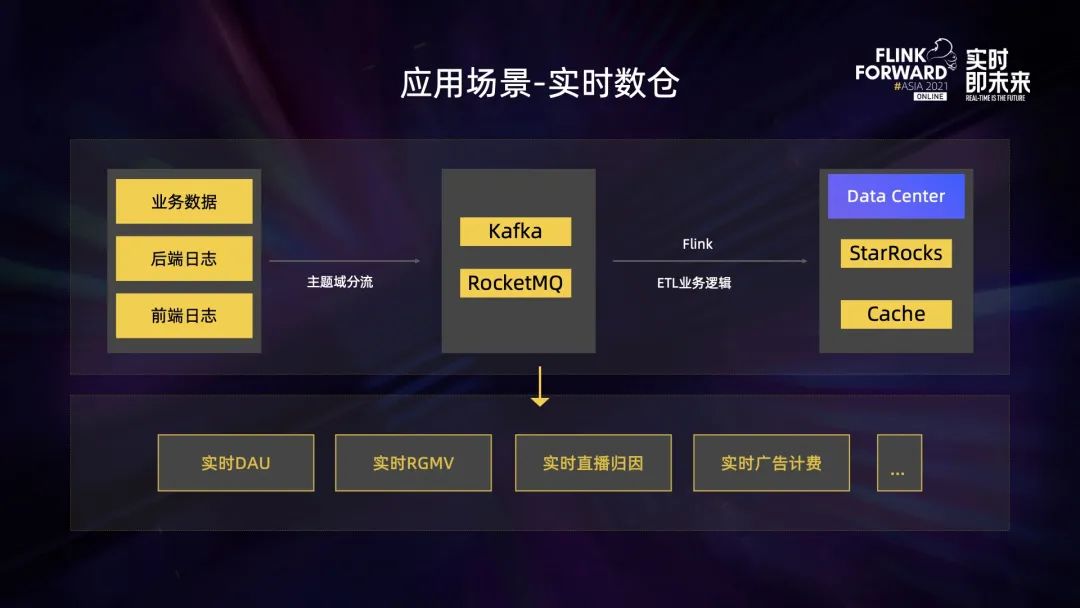
第二個場景是實時數倉。業務數據包括前后端打點的數據,按照業務分流規則進行處理之后會寫入到 Kafka 或者 RocketMQ 中,后續 Flink 會對這部分數據做實時 ETL 業務處理,最終進入實時數據中心。目前實時數據中心主要是基于 StarRocks 實現的,StarRocks 是一個性能十分強大的 OLAP 引擎,它承載了公司很多實時相關業務。在數據中心之上,我們還支撐了很多重要實時指標,比如實時 DAU、實時 GMV、實時直播歸因、實時廣告計費等。
三、Helm 集群管理模式
在正式遷入到 Native Flink on K8s 之前很長一段時間內,都是基于 Helm 來進行集群管理的。Helm 是一個 K8s 上的包管理器,它可以定義、安裝和升級 K8s 應用和服務,同時具有以下幾個特點:

第一,可以管理比較復雜的 K8s 應用,創建 Flink 集群時會創建很多 K8s 相關的資源,例如 service 或者 config map 以及 Deployment 等, Helm 可以將這些資源統一打包成一個 Helm chart,然后進行統一管理,從而不需要感知每一種資源對應的底層描述文件。
第二,比較方便升級和回滾,只需要執行一條簡單命令就可以進行升級或者回滾。同時因為它的代碼是和 Flink Client 的代碼做了隔離,因此在升級過程中不需要去修改 Flink Client 的代碼,實現了代碼解耦。
第三,非常易于共享,將 Helm chart 部署在公司私有服務器上之后,已經可以同時支持多個云產品的 Flink 集群管理。
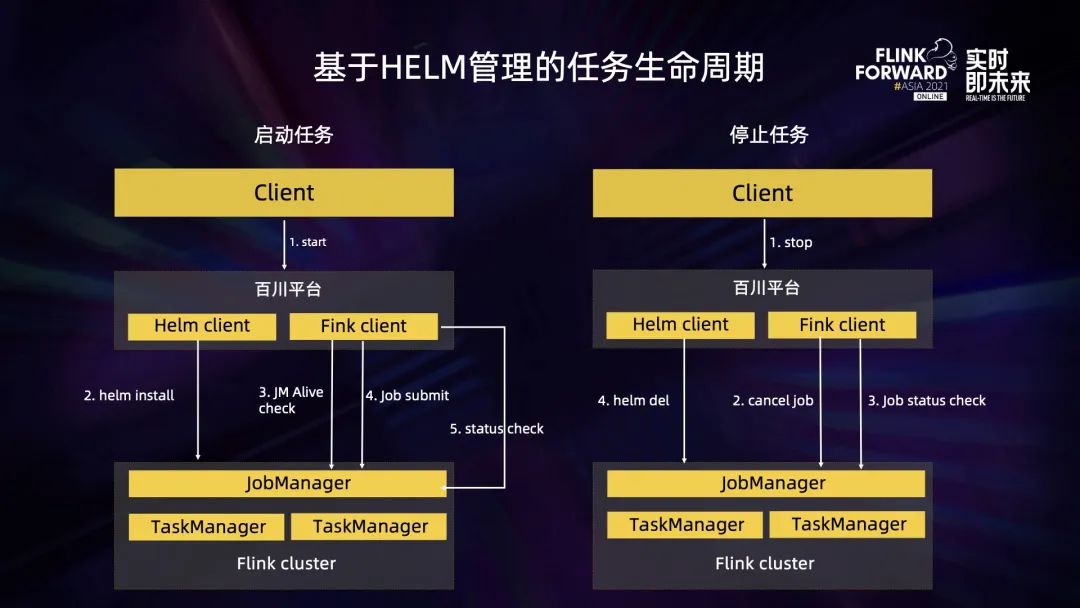
上圖是基于 Helm 管理的 Flink 任務生命周期,主要分為啟動任務和停止任務兩個階段。這里有三個角色,第一個是 Client,它可以是一個 API 請求,也可以是用戶在界面上的一次點擊行為。啟動任務時,百川平臺接收到 API 請求后,會通過 Helm Client 命令去執行 install 指令,創建對應的集群資源,同時內部集成的 Flink Client 也會去檢查當前集群的 JobManager 是否啟動,如果已經啟動就進行 job 提交。job 提交到集群運行起來之后,Flink Client 也會不斷地檢查當前 job 的運行狀態,這也是 Helm 管理模式下作業狀態的維護機制。
第二個階段是任務停止階段,Client 會向百川平臺發起一個 stop 命令,接收到 stop 命令之后百川平臺會通過 Flink Client 向 JobManager 發起 cancel 指令,同時檢查這個 cancel 指令有沒有執行成功,發現 job 被 cancel 之后,會通過 Helm Client 去執行 delete 指令,完成集群資源的銷毀。
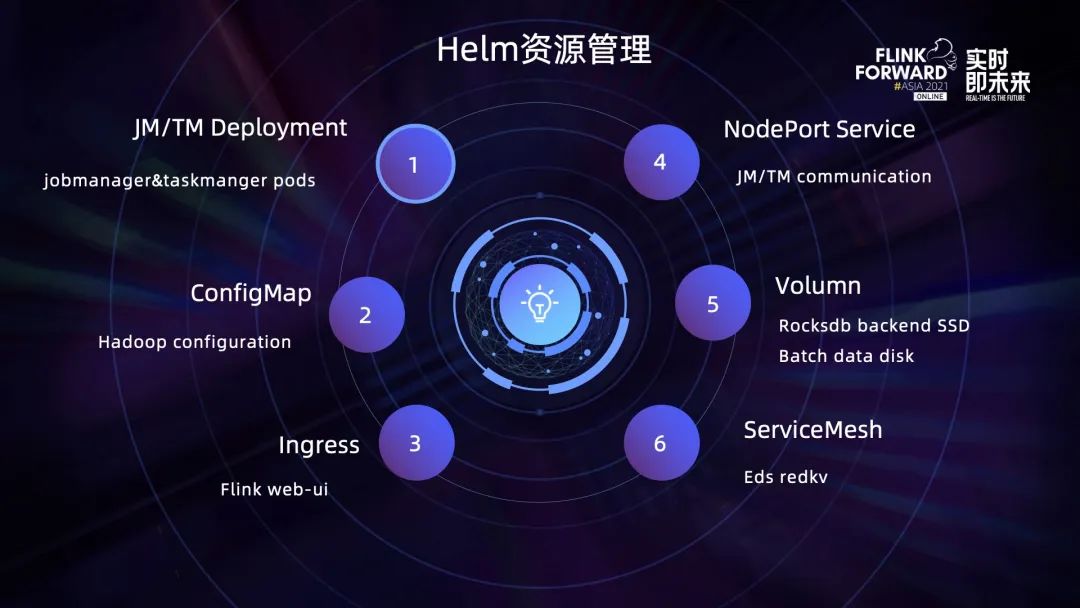
上圖展示了通過 Helm 創建了哪些 K8s 資源。
首先是最基礎的 JobManager 和 TaskManager Deployment;
第二部分是 ConfigMap,主要是針對 log4j 的配置和各大云廠商提供的云存儲產品相關的配置;
第三部分是 Ingress,目前主要用于 Flink web UI 使用以及訪問 JobManager 當前任務狀態;
第四部分是 Nodeport Service,每啟動一個 JobManager,就會在 JM 上啟動一個 Nodeport Service,并與 Ingress 做綁定;
第五部分是指磁盤資源,主要有以下兩個應用場景:使用 RocksDB Backend 的時候需要去掛載高效云盤、批處理任務需要掛載磁盤做中間數據交換;
最后一部分是 ServiceMesh,TaskManager 內部會通過 sidecar 形式去訪問第三方服務,比如說 Redkv service,這些 service 的配置也是在這里面創建的。
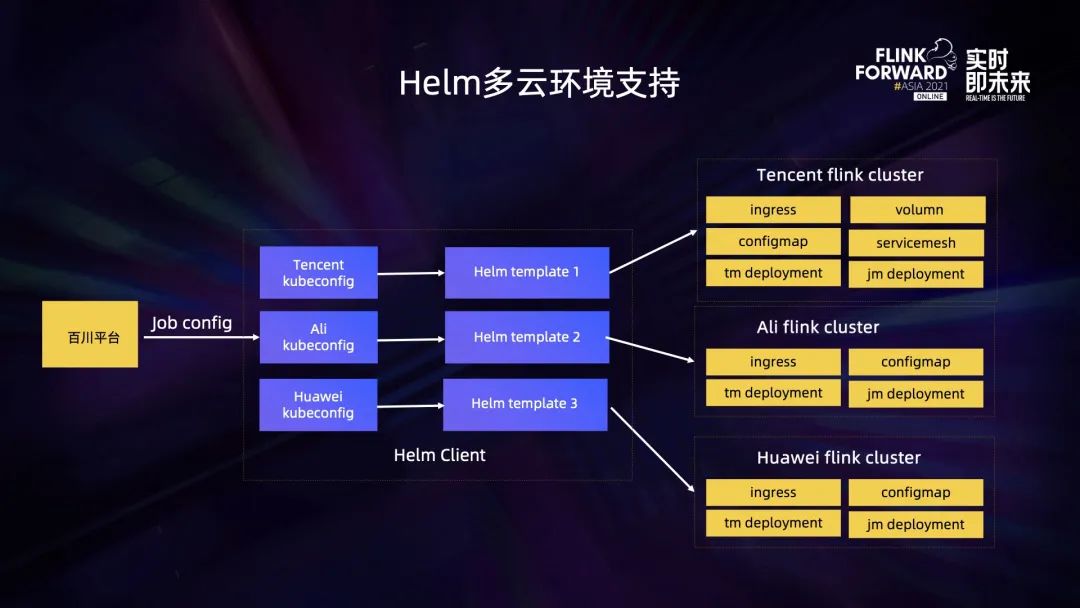
上圖可以看到 Helm Client 里面是集成了各大云廠商提供了 K8s 相關的配置,當它接收到創建任務的參數時,會根據這些參數去渲染出不同的 Helm 模板,并提交到不同的云上執行,創建出對應的集群資源。
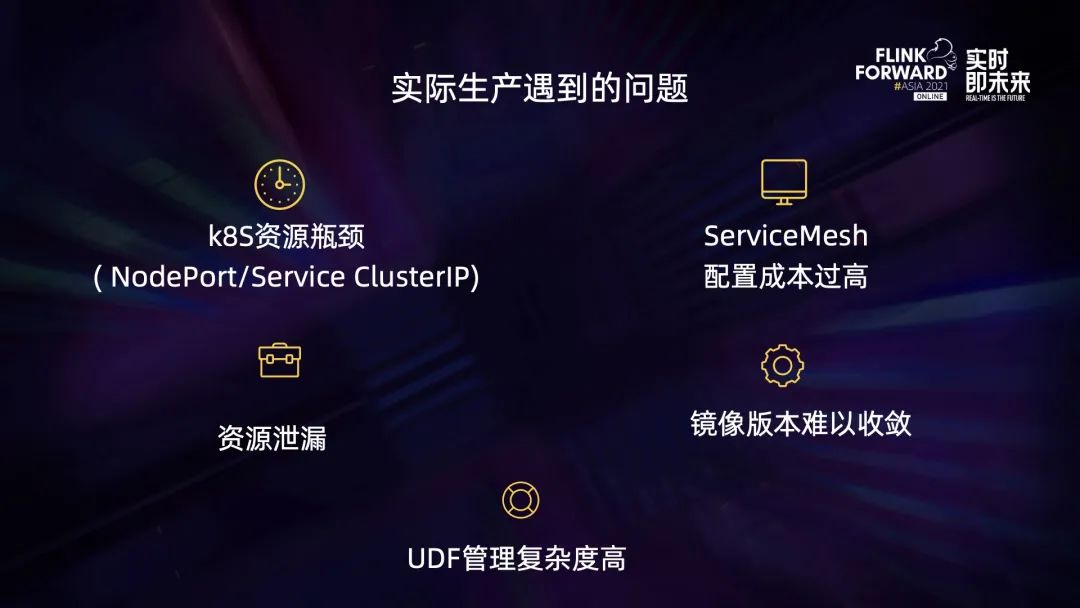
目前的集群管理模式下,在實際生產過程中還是遇到了不少問題:
第一是 K8s 資源瓶頸問題。因為每啟動一個 JobManager 就會創建一個 NodePort Service,而這個 Service 會在整個集群范圍內占用一個端口和一個 ClusterIP。當作業規模達到一定程度的時候,這些端口資源以及 IP 資源就會遇到性能瓶頸了。
第二個是 ServiceMesh 配置成本過高。上文提到 TaskManager 內部會訪問第三方服務,比如說 redkv service,那么每增加一個 redkv service,就需要去修改對應的配置并完成發版,過程的成本是比較高的。
第三個是存在一定的資源泄露問題。所有的資源創建以及銷毀都是通過執行 Helm 命令來完成的,在某些異常情況下,job 失敗會導致 Helm delete 命令沒有被執行,這個時候就有可能會存在資源泄露的問題。
第四個是鏡像版本比較難以收斂。在日常的生產過程中,某些線上任務出現了問題,會臨時出一個 hotfix 版本鏡像并上線運行,久而久之線上就會存在很多版本鏡像在運行,這對于后面的運維工作以及問題排查產生了非常大的挑戰。
最后一個問題是 UDF 管理復雜度比較高,這是任何分布式計算平臺都會遇到的一個問題。
針對上述這些問題,我們在 Native Flink on K8s 模式下一一進行了優化解決。
四、Native Flink on Kubernetes
首先,為什么會選擇這種部署模式?因為它具有以下三個特征:

- 更短的 Failover 時間;
- 可以實現資源托管,不需要手動創建 TaskManager 的 pod,也可以自動完成銷毀;
- 具有更加便捷的 HA。在 Flink 1.12 之前,實現 JobManager HA 還是依賴于第三方的 zookeeper。但在 Native Flink on K8s 模式下,可以依賴于原生 K8s 的 leader 選舉機制來完成 JobManager 的 HA。
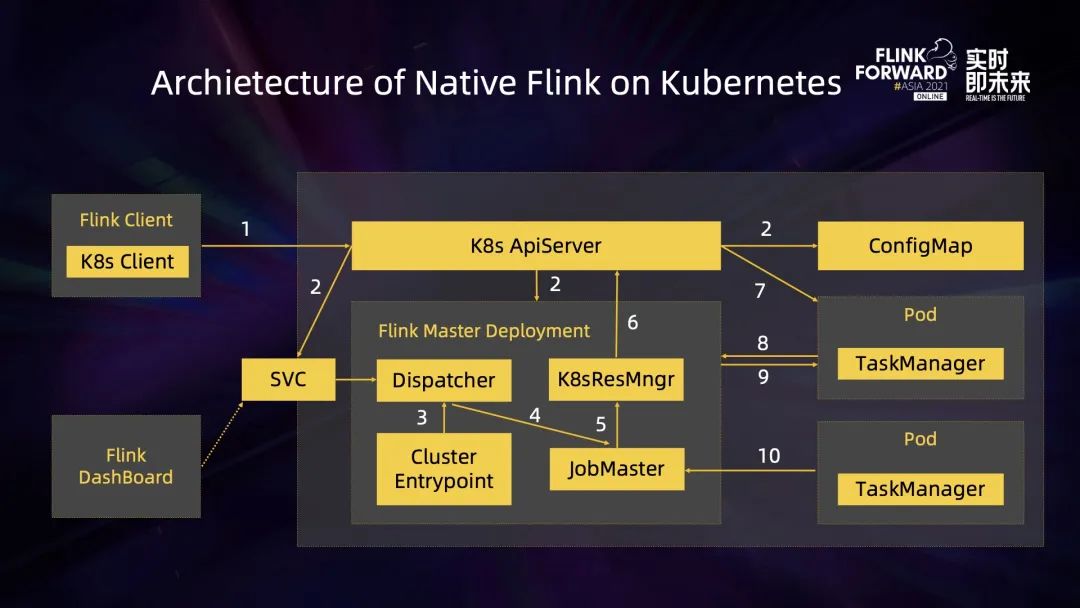
上圖是 Native Flink on K8s 的體系架構圖。Flink Client 里面集成了一個 K8s Client,它可以直接和 K8s API server 進行通訊,完成 JobManager Deployment 以及 ConfigMap 的創建。JobManager development 創建完成之后,它里面的 resource manager 模塊可以直接和 K8s API server 進行通訊,完成 TaskManager pod 的創建和銷毀工作,這也是它與傳統 session Cluster 模式比較大的不同之處。

內部將 UDF 分為兩類:
第一類是平臺內置的,將平時的生產工作中經常使用到的 UDF 進行抽象歸納總結,并內置到鏡像里面。鏡像里有關于 UDF 的配置文件,其中有 UDF 的名稱以及類型,同時指定了它對應的實現類。
另外一類是 User-defined UDF,在 Helm 管理模式下,針對用戶自定義的 UDF 管理是比較粗放的,將用戶 project 下所有 UDF 相關的 JAR 包統一加載到 classloader 下,這會導致類沖突問題。而在 Native Flink 模式下,實現了一個 create function using JAR 的語法,可以按需加載用戶所需要的 UDF 對應的 JAR 包,可以極大地緩解類沖突的問題。
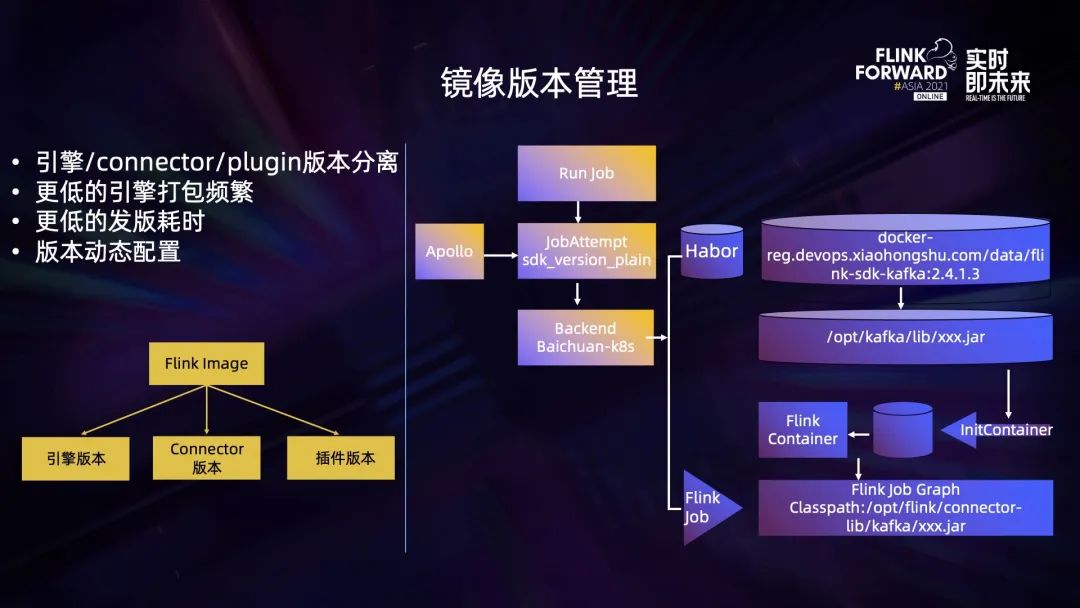
在原有的模式上,鏡像管理是通過將所有代碼統一打包到一個大的 image 里,但這樣會存在一個問題,對任何模塊的修改都需要對整個代碼庫進行一次編譯打包,而這個過程是非常耗時的。
在 Native Flink 版本下,針對鏡像版本管理做了一些優化,主要是將 Flink 的 image 拆分為了三個部分,分為 Flink engine、connector 以及第三方插件。這三個部分都有各自版本號,并且可以自由進行拼裝組合。這項優化降低了引擎打包的頻率,也意味著可以提升發版效率。
拆分之后,Flink 如何將這些鏡像組合成一個可以運行的鏡像呢?下面以加載一個 Kafka SDK 插件為例來進行闡述。job 運行時會從一個動態配置倉庫中獲取當前這個 job 應該使用的 Kafka SDK 版本,并將其傳遞給百川的后端,這個 SDK 版本對應了 docker 倉庫里面的一個鏡像,鏡像只包含一個 SDK 對應的 JAR 包,百川的后端在渲染 pod 模板的時候,會在 InitContainer 階段將 image 加載進來,同時將它 Kafka 的 JAR 包移動到 Flink container 某個指定的目錄下去,以此完成加載。
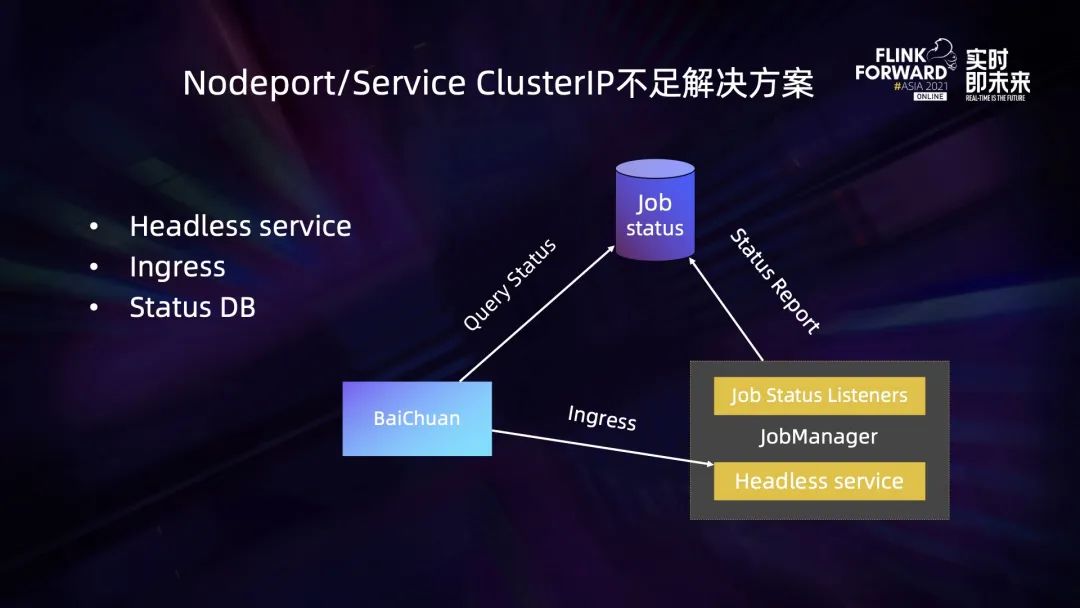
在新的模式下,對 job 狀態維護機制做了一次重構,引入了一個 headless 類型的 service 以及一個 status DB。在 JobManager 模塊,通過 JobManager status listener 不斷監聽 job 狀態變化,并將這個變化上傳到 job ststusDB 中,百川平臺可以通過 Query DB 來獲取任務的狀態。另外在某些場景下,可能因為 job 狀態上傳失敗導致百川無法獲取到任務的狀態,百川還是可以走原來的路徑,通過 Ingress 去訪問 JobManager 來獲取任務的狀態。此時的 Ingress 和之前不同之處在于它綁定的是一個 headless service,不需要占用集群的 Cluster IP,這就解決了之前模式下 K8s ClusterIP 以及 nodePort 不足的問題。
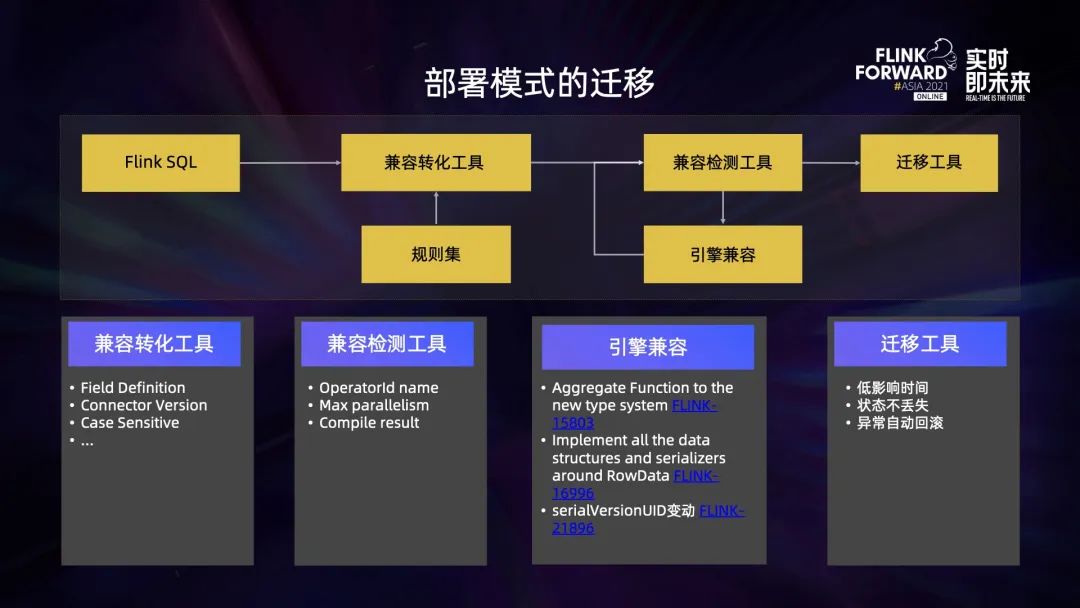
完成上述優化工作以后,面臨的最大的問題就是如何將老版本的任務平滑地遷移到新版本 Flink 1.13 上,這其實是一項非常具有挑戰性的工作。主要做了以下 4 個方面的工作:
第一,兼容轉化工具。這個工具會對 SQL 進行轉化,保證 SQL 在 1.13 運行的語法校驗不會出錯。1.10 到 1.13 經歷過幾個大版本的變更, SQL 的定義在眾多方面已經不兼容,比如在 1.10 和 1.11 的時候,Kafka connector 的取值是 0.11,到 1.13 之后,對應取值已經變成 universal,如果不做任何轉化,原始 SQL 肯定在 1.13 上沒有辦法運行。
第二,兼容檢測工具。這個工具的目的是為了檢查 SQL 運行在 1.13 的時候能不能從一個低版本的 savepoint 去進行恢復。主要從以下幾個方面去做了檢查:operator ID 升級之后,名稱有沒有發生變化;新舊兩個版本對應的 max parallelism 有沒有發生變化,因為 max parallelism 發生變化的時候,在某部分場景下是沒有辦法從一個老的 savepoint 來恢復的。
第三,預編譯。在 1.13 上對轉換之后的 SQL 進行預編譯,看編譯的結果是否能夠正常通過。在兼容檢測工具的過程中,也發現了很多從低版本到高版本不兼容的地方,引入了新的數據類型機制,1.11 沒有使用 ExternalSerializer,而 1.12 及以后使用 ExternalSerializer 進行包裝;BaseRowSerializer 已經在 Flink 1.11 時候改名成了 RowDataSerializer;數據類型里面有一個 seriaVersionUID,之前它是一個隨機的 long 類型的數字,而在 1.13 統一固定成了 1。上述種種不兼容會導致 1.13 沒有辦法直接從一個低版本的 savepoint 來恢復的。因此針對這些問題,在引擎側做了一些改造。
第四,遷移工具。這個工具的目標主要有以下三點:
首先,對用戶作業的影響時間盡可能降到最低,為了達成這個目標,我們對 Native Flink on K8s 的 application mode 做了比較大的改造。原生的 application mode 是一邊調度一邊申請資源,為了在升級過程中降低對用戶作業的影響,實現了 application mode 下可以提前申請好資源并完成 SQL 的編譯 (即 JobManager 的預啟動),這個過程完成之后,將舊的 job 停掉然后啟動新的 job,整個過程對用戶作業的影響能夠控制在 30 秒以內 (中等規模任務)。
其次,在遷移的過程中要保證狀態不丟失,因為所有遷移都是基于 savepoint 來啟動的,所以這塊的數據是不會有任何丟失的。
最后,如果在升級過程中發生了異常,可以支持異常情況下自動完成回滾。

在實際 Application mode 應用過程中,也發現了原生 Flink 的一些問題,并做了對應的處理方案。
例如 JobManager 在 failover 的時候會重新拉起一批新的 TM,會導致 TaskManager 的資源翻倍。如果資源池的資源不足以滿足 double 的需求,就有可能導致 failover 失敗。此外,即使這一次 failover 成功了,但是新啟動的 job 會基于首次啟動時指定的 recover path 來進行恢復,這個時候的位點可能已經是一個十天以前的位點了,這會導致數據重復消費的問題。針對這個問題,在檢測到 JobManager 發生 failover 的時候就會在引擎側直接將 job fail 掉并告警,然后通過人工手動介入來處理。
五、流批一體作業管控平臺

流批一體作業管控平臺主要提供了以下幾個模塊的功能:作業開發及運維、版本管理、監控報警、資源管理、數據血緣、元數據管理以及 SDK。其中資源管理主要分為資源隔離和資源推薦,數據血緣主要用于展示 Flink 任務上下游之間的關系,元數據管理主要是針對用戶 catalog 表。
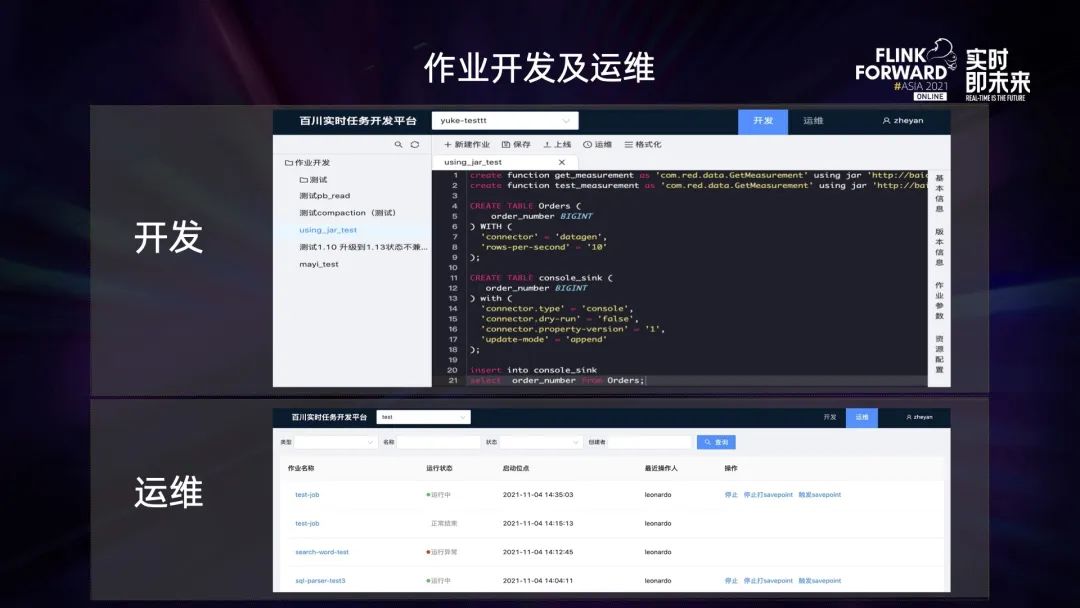
上圖上半部分是 SQL 開發界面,頁面的主體部分 SQL 編輯器,右側有任務的基本信息、版本信息、作業參數以及一些資源配置相關的界面元素。
下半部分是任務運維界面,上面提供了很多常規操作,比如停止任務,或先打 savepoint 再停止任務等。
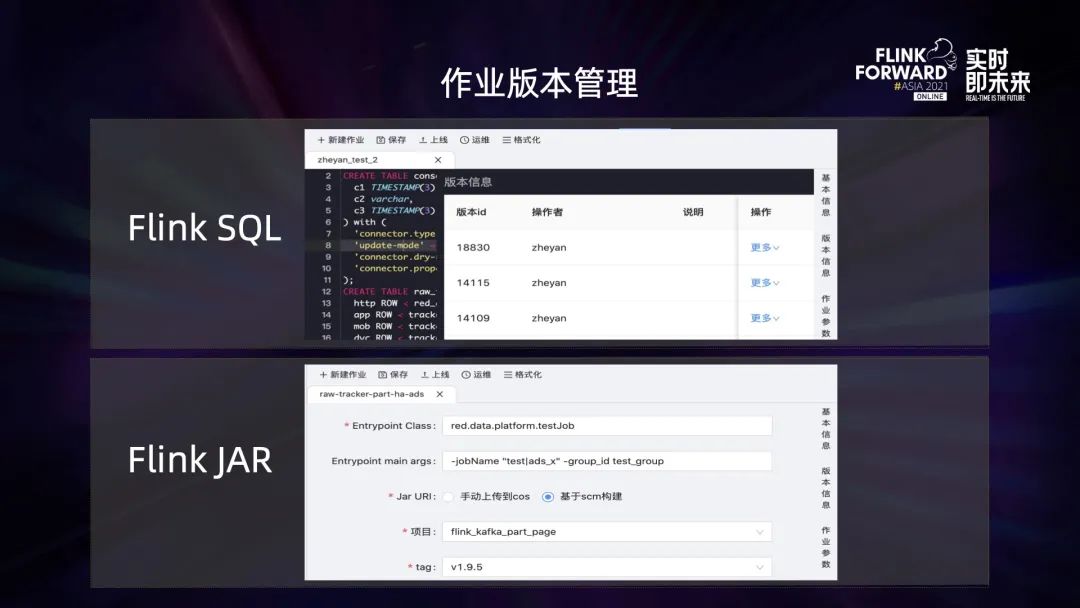
作業版本管理分為 Flink SQL 任務以及 Flink JAR 任務。在 SQL 任務界面上可以看到 SQL 經歷過很多次發版,“更多” 按鈕提供了回滾操作。針對 Flink JAR 任務,目前有兩種提交 JAR 任務的方法,可以直接將用戶的 JAR 包上傳到一個分布式存儲路徑,也可以通過指定代碼倉庫 tag 來指定 JAR 包的版本。
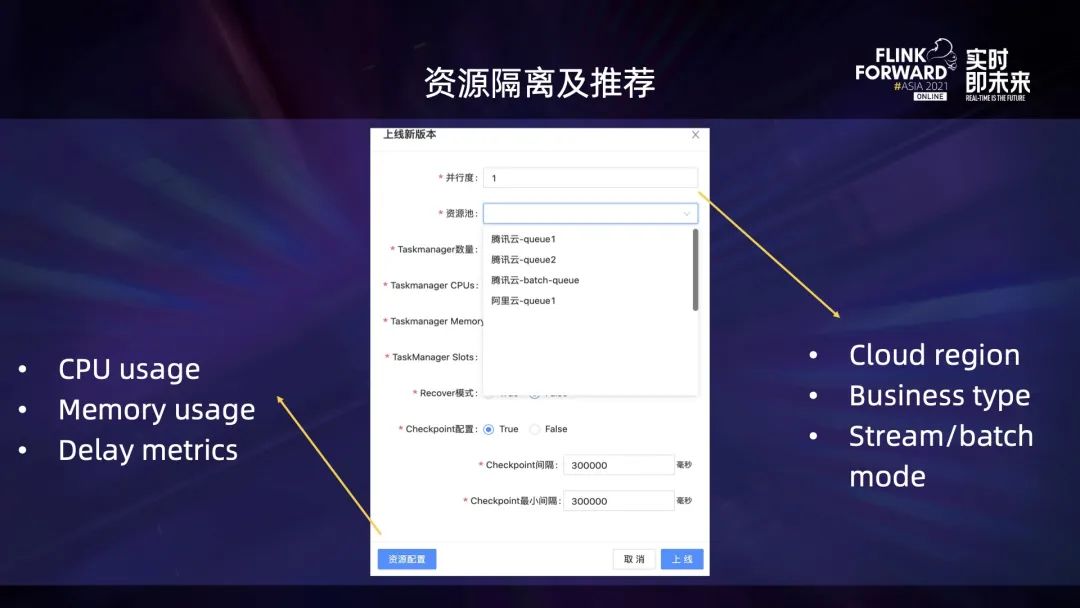
資源管理主要分為資源隔離和資源推薦。這里引入了資源池的概念,并基于以下幾個維度做了切分:
- 第一個因素是它運行所屬的云環境;
- 第二個因素是業務類型;
- 第三個因素是資源池提供給流還是批任務使用。
另外,針對已經運行一段時間的任務,會結合它歷史運行期間的 CPU、內存、延遲 lag 等指標信息,給出當前任務所需要的最佳 K8s 資源配置推薦結果。

Rugal 調度平臺是公司內部一個對標 airflow 的產品,它可以通過百川提供的 SDK 定時創建任務提交到百川平臺。上圖左側是一個 SQL 編輯模板,其中的很多參數信息都是通過變量的形式來展示。調用 SDK 的時候,可以將這些變量對應的實際值傳入進來,并用這些值渲染出具體要執行的 SQL,從而生成具體的執行實例。
六、未來展望

最后是對未來工作的規劃。
第一,動態資源調整。目前, Flink job 一旦提交運行,就無法在運行期間修改某個 operator 占用的資源。所以希望未來能夠在 job 不進行 restart 的情況下,調整某個算子所占用的資源。
第二,跨云多活方案。目前公司核心 P0 作業基本都是雙鏈路的,但都僅限于在單朵云上。希望針對這些核心任務,實現跨云雙活方案,其中一個云上任務出現問題的時候,能夠穩定切換到另外一朵云上。
第三,批任務資源調度優化。因為批任務大多是在凌晨以后開始執行,同時會調度很多任務,有的任務可能因為搶占不到資源導致無法及時運行,在任務調度執行策略上仍有可以優化的空間。