不愧是字節(jié),面?zhèn)€實(shí)習(xí)也滿頭大汗!
大家好,我是小林。
最近有一些同學(xué)問我,要準(zhǔn)備到什么程度才能去找大廠日常實(shí)習(xí)?
其實(shí)大廠的日常實(shí)習(xí)面試和校招面試差不太多,面試的問題都差不多,八股+項(xiàng)目+算法,都必須要準(zhǔn)備,只是說實(shí)習(xí)面試要求可能不會(huì)太嚴(yán)格,比如你實(shí)習(xí)的算法,即使沒寫出來,能說出大概的思路,其實(shí)也是能過的,秋招的話,可能沒寫出算法,大概率就涼了。
針對(duì)后端這一塊的話,編程語(yǔ)言+MySQL+Redis+網(wǎng)絡(luò)協(xié)議+操作系統(tǒng)+后端項(xiàng)目+算法,這幾大塊都需要好好準(zhǔn)備一波,后端面試都是圍繞這幾大塊知識(shí)進(jìn)行考察。
雖然后端技術(shù)棧還包含消息隊(duì)列、分布式、微服務(wù),但是這些針對(duì)校招來說不是必須要掌握的內(nèi)容,時(shí)間有限的情況下,可以延后學(xué)習(xí)。
今天就分享一個(gè)字節(jié)日常實(shí)習(xí)的一面和二面的Java后端面經(jīng),我把問題分類了一下,主要是網(wǎng)絡(luò)+操作系統(tǒng)+Java+MySQL+Redis+算法這幾大塊問題,也做對(duì)應(yīng)的解答,內(nèi)容比較多,同學(xué)們可以收藏,后續(xù)慢慢細(xì)看&復(fù)習(xí)。
網(wǎng)絡(luò)
http和https的區(qū)別是什么?
絡(luò)層") HTTP 與 HTTPS 網(wǎng)絡(luò)層
HTTP 與 HTTPS 網(wǎng)絡(luò)層
- HTTP 是超文本傳輸協(xié)議,信息是明文傳輸,存在安全風(fēng)險(xiǎn)的問題。HTTPS 則解決 HTTP 不安全的缺陷,在 TCP 和 HTTP 網(wǎng)絡(luò)層之間加入了 SSL/TLS 安全協(xié)議,使得報(bào)文能夠加密傳輸。
- HTTP 連接建立相對(duì)簡(jiǎn)單, TCP 三次握手之后便可進(jìn)行 HTTP 的報(bào)文傳輸。而 HTTPS 在 TCP 三次握手之后,還需進(jìn)行 SSL/TLS 的握手過程,才可進(jìn)入加密報(bào)文傳輸。
- 兩者的默認(rèn)端口不一樣,HTTP 默認(rèn)端口號(hào)是 80,HTTPS 默認(rèn)端口號(hào)是 443。
- HTTPS 協(xié)議需要向 CA(證書權(quán)威機(jī)構(gòu))申請(qǐng)數(shù)字證書,來保證服務(wù)器的身份是可信的。
域名和ip地址如何對(duì)映的?
主要通過DNS域名解析來完成的。域名解析的工作流程:
- 客戶端首先會(huì)發(fā)出一個(gè) DNS 請(qǐng)求,問 www.server.com 的 IP 是啥,并發(fā)給本地 DNS 服務(wù)器(也就是客戶端的 TCP/IP 設(shè)置中填寫的 DNS 服務(wù)器地址)。
- 本地域名服務(wù)器收到客戶端的請(qǐng)求后,如果緩存里的表格能找到 www.server.com,則它直接返回 IP 地址。如果沒有,本地 DNS 會(huì)去問它的根域名服務(wù)器:“老大, 能告訴我 www.server.com 的 IP 地址嗎?” 根域名服務(wù)器是最高層次的,它不直接用于域名解析,但能指明一條道路。
- 根 DNS 收到來自本地 DNS 的請(qǐng)求后,發(fā)現(xiàn)后置是 .com,說:“www.server.com 這個(gè)域名歸 .com 區(qū)域管理”,我給你 .com 頂級(jí)域名服務(wù)器地址給你,你去問問它吧。”
- 本地 DNS 收到頂級(jí)域名服務(wù)器的地址后,發(fā)起請(qǐng)求問“老二, 你能告訴我 www.server.com 的 IP 地址嗎?”
- 頂級(jí)域名服務(wù)器說:“我給你負(fù)責(zé) www.server.com 區(qū)域的權(quán)威 DNS 服務(wù)器的地址,你去問它應(yīng)該能問到”。
- 本地 DNS 于是轉(zhuǎn)向問權(quán)威 DNS 服務(wù)器:“老三,www.server.com對(duì)應(yīng)的IP是啥呀?” server.com 的權(quán)威 DNS 服務(wù)器,它是域名解析結(jié)果的原出處。為啥叫權(quán)威呢?就是我的域名我做主。
- 權(quán)威 DNS 服務(wù)器查詢后將對(duì)應(yīng)的 IP 地址 X.X.X.X 告訴本地 DNS。
- 本地 DNS 再將 IP 地址返回客戶端,客戶端和目標(biāo)建立連接。
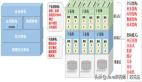
至此,我們完成了 DNS 的解析過程。現(xiàn)在總結(jié)一下,整個(gè)過程我畫成了一個(gè)圖。
 域名解析的工作流程
域名解析的工作流程
get和post的區(qū)別?
根據(jù) RFC 規(guī)范,GET 的語(yǔ)義是從服務(wù)器獲取指定的資源,這個(gè)資源可以是靜態(tài)的文本、頁(yè)面、圖片視頻等。GET 請(qǐng)求的參數(shù)位置一般是寫在 URL 中,URL 規(guī)定只能支持 ASCII,所以 GET 請(qǐng)求的參數(shù)只允許 ASCII 字符 ,而且瀏覽器會(huì)對(duì) URL 的長(zhǎng)度有限制(HTTP協(xié)議本身對(duì) URL長(zhǎng)度并沒有做任何規(guī)定)。
比如,你打開我的文章,瀏覽器就會(huì)發(fā)送 GET 請(qǐng)求給服務(wù)器,服務(wù)器就會(huì)返回文章的所有文字及資源。
求") GET 請(qǐng)求
GET 請(qǐng)求
根據(jù) RFC 規(guī)范,POST 的語(yǔ)義是根據(jù)請(qǐng)求負(fù)荷(報(bào)文body)對(duì)指定的資源做出處理,具體的處理方式視資源類型而不同。POST 請(qǐng)求攜帶數(shù)據(jù)的位置一般是寫在報(bào)文 body 中,body 中的數(shù)據(jù)可以是任意格式的數(shù)據(jù),只要客戶端與服務(wù)端協(xié)商好即可,而且瀏覽器不會(huì)對(duì) body 大小做限制。
比如,你在我文章底部,敲入了留言后點(diǎn)擊「提交」(暗示你們留言),瀏覽器就會(huì)執(zhí)行一次 POST 請(qǐng)求,把你的留言文字放進(jìn)了報(bào)文 body 里,然后拼接好 POST 請(qǐng)求頭,通過 TCP 協(xié)議發(fā)送給服務(wù)器。
求") POST 請(qǐng)求
POST 請(qǐng)求
tcp 建立連接的三次握手過程介紹一下
TCP 是面向連接的協(xié)議,所以使用 TCP 前必須先建立連接,而建立連接是通過三次握手來進(jìn)行的。三次握手的過程如下圖:
 TCP 三次握手
TCP 三次握手
- 一開始,客戶端和服務(wù)端都處于 CLOSE 狀態(tài)。先是服務(wù)端主動(dòng)監(jiān)聽某個(gè)端口,處于 LISTEN 狀態(tài)
報(bào)文 —— SYN 報(bào)文") 第一個(gè)報(bào)文 —— SYN 報(bào)文
第一個(gè)報(bào)文 —— SYN 報(bào)文
- 客戶端會(huì)隨機(jī)初始化序號(hào)(client_isn),將此序號(hào)置于 TCP 首部的「序號(hào)」字段中,同時(shí)把 SYN 標(biāo)志位置為 1,表示 SYN 報(bào)文。接著把第一個(gè) SYN 報(bào)文發(fā)送給服務(wù)端,表示向服務(wù)端發(fā)起連接,該報(bào)文不包含應(yīng)用層數(shù)據(jù),之后客戶端處于 SYN-SENT 狀態(tài)。
報(bào)文 —— SYN + ACK 報(bào)文") 第二個(gè)報(bào)文 —— SYN + ACK 報(bào)文
第二個(gè)報(bào)文 —— SYN + ACK 報(bào)文
- 服務(wù)端收到客戶端的 SYN 報(bào)文后,首先服務(wù)端也隨機(jī)初始化自己的序號(hào)(server_isn),將此序號(hào)填入 TCP 首部的「序號(hào)」字段中,其次把 TCP 首部的「確認(rèn)應(yīng)答號(hào)」字段填入 client_isn + 1, 接著把 SYN 和 ACK 標(biāo)志位置為 1。最后把該報(bào)文發(fā)給客戶端,該報(bào)文也不包含應(yīng)用層數(shù)據(jù),之后服務(wù)端處于 SYN-RCVD 狀態(tài)。
報(bào)文 —— ACK 報(bào)文") 第三個(gè)報(bào)文 —— ACK 報(bào)文
第三個(gè)報(bào)文 —— ACK 報(bào)文
- 客戶端收到服務(wù)端報(bào)文后,還要向服務(wù)端回應(yīng)最后一個(gè)應(yīng)答報(bào)文,首先該應(yīng)答報(bào)文 TCP 首部 ACK 標(biāo)志位置為 1 ,其次「確認(rèn)應(yīng)答號(hào)」字段填入 server_isn + 1 ,最后把報(bào)文發(fā)送給服務(wù)端,這次報(bào)文可以攜帶客戶到服務(wù)端的數(shù)據(jù),之后客戶端處于 ESTABLISHED 狀態(tài)。
- 服務(wù)端收到客戶端的應(yīng)答報(bào)文后,也進(jìn)入 ESTABLISHED 狀態(tài)。
為什么不是 2 次或者 4 次握手?
三次握手的原因:
- 三次握手才可以阻止重復(fù)歷史連接的初始化(主要原因)
- 三次握手才可以同步雙方的初始序列號(hào)
- 三次握手才可以避免資源浪費(fèi)
原因一:避免歷史連接
我們來看看 RFC 793 指出的 TCP 連接使用三次握手的首要原因:
The principle reason for the three-way handshake is to prevent old duplicate connection initiations from causing confusion.
簡(jiǎn)單來說,三次握手的首要原因是為了防止舊的重復(fù)連接初始化造成混亂。
我們考慮一個(gè)場(chǎng)景,客戶端先發(fā)送了 SYN(seq = 90)報(bào)文,然后客戶端宕機(jī)了,而且這個(gè) SYN 報(bào)文還被網(wǎng)絡(luò)阻塞了,服務(wù)端并沒有收到,接著客戶端重啟后,又重新向服務(wù)端建立連接,發(fā)送了 SYN(seq = 100)報(bào)文(注意!不是重傳 SYN,重傳的 SYN 的序列號(hào)是一樣的)。
看看三次握手是如何阻止歷史連接的:
 三次握手避免歷史連接
三次握手避免歷史連接
客戶端連續(xù)發(fā)送多次 SYN(都是同一個(gè)四元組)建立連接的報(bào)文,在網(wǎng)絡(luò)擁堵情況下:
- 一個(gè)「舊 SYN 報(bào)文」比「最新的 SYN」 報(bào)文早到達(dá)了服務(wù)端,那么此時(shí)服務(wù)端就會(huì)回一個(gè) SYN + ACK 報(bào)文給客戶端,此報(bào)文中的確認(rèn)號(hào)是 91(90+1)。
- 客戶端收到后,發(fā)現(xiàn)自己期望收到的確認(rèn)號(hào)應(yīng)該是 100 + 1,而不是 90 + 1,于是就會(huì)回 RST 報(bào)文。
- 服務(wù)端收到 RST 報(bào)文后,就會(huì)釋放連接。
- 后續(xù)最新的 SYN 抵達(dá)了服務(wù)端后,客戶端與服務(wù)端就可以正常的完成三次握手了。
上述中的「舊 SYN 報(bào)文」稱為歷史連接,TCP 使用三次握手建立連接的最主要原因就是防止「歷史連接」初始化了連接。
如果是兩次握手連接,就無法阻止歷史連接,那為什么 TCP 兩次握手為什么無法阻止歷史連接呢?
我先直接說結(jié)論,主要是因?yàn)樵趦纱挝帐值那闆r下,服務(wù)端沒有中間狀態(tài)給客戶端來阻止歷史連接,導(dǎo)致服務(wù)端可能建立一個(gè)歷史連接,造成資源浪費(fèi)。
你想想,在兩次握手的情況下,服務(wù)端在收到 SYN 報(bào)文后,就進(jìn)入 ESTABLISHED 狀態(tài),意味著這時(shí)可以給對(duì)方發(fā)送數(shù)據(jù),但是客戶端此時(shí)還沒有進(jìn)入 ESTABLISHED 狀態(tài),假設(shè)這次是歷史連接,客戶端判斷到此次連接為歷史連接,那么就會(huì)回 RST 報(bào)文來斷開連接,而服務(wù)端在第一次握手的時(shí)候就進(jìn)入 ESTABLISHED 狀態(tài),所以它可以發(fā)送數(shù)據(jù)的,但是它并不知道這個(gè)是歷史連接,它只有在收到 RST 報(bào)文后,才會(huì)斷開連接。
兩次握手無法阻止歷史連接
可以看到,如果采用兩次握手建立 TCP 連接的場(chǎng)景下,服務(wù)端在向客戶端發(fā)送數(shù)據(jù)前,并沒有阻止掉歷史連接,導(dǎo)致服務(wù)端建立了一個(gè)歷史連接,又白白發(fā)送了數(shù)據(jù),妥妥地浪費(fèi)了服務(wù)端的資源。
因此,要解決這種現(xiàn)象,最好就是在服務(wù)端發(fā)送數(shù)據(jù)前,也就是建立連接之前,要阻止掉歷史連接,這樣就不會(huì)造成資源浪費(fèi),而要實(shí)現(xiàn)這個(gè)功能,就需要三次握手。
所以,TCP 使用三次握手建立連接的最主要原因是防止「歷史連接」初始化了連接。
原因二:同步雙方初始序列號(hào)
TCP 協(xié)議的通信雙方, 都必須維護(hù)一個(gè)「序列號(hào)」, 序列號(hào)是可靠傳輸?shù)囊粋€(gè)關(guān)鍵因素,它的作用:
- 接收方可以去除重復(fù)的數(shù)據(jù);
- 接收方可以根據(jù)數(shù)據(jù)包的序列號(hào)按序接收;
- 可以標(biāo)識(shí)發(fā)送出去的數(shù)據(jù)包中, 哪些是已經(jīng)被對(duì)方收到的(通過 ACK 報(bào)文中的序列號(hào)知道);
可見,序列號(hào)在 TCP 連接中占據(jù)著非常重要的作用,所以當(dāng)客戶端發(fā)送攜帶「初始序列號(hào)」的 SYN 報(bào)文的時(shí)候,需要服務(wù)端回一個(gè) ACK 應(yīng)答報(bào)文,表示客戶端的 SYN 報(bào)文已被服務(wù)端成功接收,那當(dāng)服務(wù)端發(fā)送「初始序列號(hào)」給客戶端的時(shí)候,依然也要得到客戶端的應(yīng)答回應(yīng),這樣一來一回,才能確保雙方的初始序列號(hào)能被可靠的同步。
 四次握手與三次握手
四次握手與三次握手
四次握手其實(shí)也能夠可靠的同步雙方的初始化序號(hào),但由于第二步和第三步可以優(yōu)化成一步,所以就成了「三次握手」。
而兩次握手只保證了一方的初始序列號(hào)能被對(duì)方成功接收,沒辦法保證雙方的初始序列號(hào)都能被確認(rèn)接收。
原因三:避免資源浪費(fèi)
如果只有「兩次握手」,當(dāng)客戶端發(fā)生的 SYN 報(bào)文在網(wǎng)絡(luò)中阻塞,客戶端沒有接收到 ACK 報(bào)文,就會(huì)重新發(fā)送 SYN ,由于沒有第三次握手,服務(wù)端不清楚客戶端是否收到了自己回復(fù)的 ACK 報(bào)文,所以服務(wù)端每收到一個(gè) SYN 就只能先主動(dòng)建立一個(gè)連接,這會(huì)造成什么情況呢?
如果客戶端發(fā)送的 SYN 報(bào)文在網(wǎng)絡(luò)中阻塞了,重復(fù)發(fā)送多次 SYN 報(bào)文,那么服務(wù)端在收到請(qǐng)求后就會(huì)建立多個(gè)冗余的無效鏈接,造成不必要的資源浪費(fèi)。
造成資源浪費(fèi)") 兩次握手會(huì)造成資源浪費(fèi)
兩次握手會(huì)造成資源浪費(fèi)
即兩次握手會(huì)造成消息滯留情況下,服務(wù)端重復(fù)接受無用的連接請(qǐng)求 SYN 報(bào)文,而造成重復(fù)分配資源。
操作系統(tǒng)
已知一個(gè)進(jìn)程名,如何殺掉這個(gè)進(jìn)程?
在Linux 操作系統(tǒng),可以使用kill命令來殺死進(jìn)程。
首先,使用ps命令查找進(jìn)程的PID(進(jìn)程ID),然后使用kill命令加上PID來終止進(jìn)程。例如:
ps -ef | grep <進(jìn)程名> // 查找進(jìn)程的PID
kill <PID> // 終止進(jìn)程進(jìn)程間通信有哪些方式?
- Linux 內(nèi)核提供了不少進(jìn)程間通信的方式,其中最簡(jiǎn)單的方式就是管道,管道分為「匿名管道」和「命名管道」。
- 匿名管道顧名思義,它沒有名字標(biāo)識(shí),匿名管道是特殊文件只存在于內(nèi)存,沒有存在于文件系統(tǒng)中,shell 命令中的「|」豎線就是匿名管道,通信的數(shù)據(jù)是無格式的流并且大小受限,通信的方式是單向的,數(shù)據(jù)只能在一個(gè)方向上流動(dòng),如果要雙向通信,需要?jiǎng)?chuàng)建兩個(gè)管道,再來匿名管道是只能用于存在父子關(guān)系的進(jìn)程間通信,匿名管道的生命周期隨著進(jìn)程創(chuàng)建而建立,隨著進(jìn)程終止而消失。
- 命名管道突破了匿名管道只能在親緣關(guān)系進(jìn)程間的通信限制,因?yàn)槭褂妹艿赖那疤幔枰谖募到y(tǒng)創(chuàng)建一個(gè)類型為 p 的設(shè)備文件,那么毫無關(guān)系的進(jìn)程就可以通過這個(gè)設(shè)備文件進(jìn)行通信。另外,不管是匿名管道還是命名管道,進(jìn)程寫入的數(shù)據(jù)都是緩存在內(nèi)核中,另一個(gè)進(jìn)程讀取數(shù)據(jù)時(shí)候自然也是從內(nèi)核中獲取,同時(shí)通信數(shù)據(jù)都遵循先進(jìn)先出原則,不支持 lseek 之類的文件定位操作。
- 消息隊(duì)列克服了管道通信的數(shù)據(jù)是無格式的字節(jié)流的問題,消息隊(duì)列實(shí)際上是保存在內(nèi)核的「消息鏈表」,消息隊(duì)列的消息體是可以用戶自定義的數(shù)據(jù)類型,發(fā)送數(shù)據(jù)時(shí),會(huì)被分成一個(gè)一個(gè)獨(dú)立的消息體,當(dāng)然接收數(shù)據(jù)時(shí),也要與發(fā)送方發(fā)送的消息體的數(shù)據(jù)類型保持一致,這樣才能保證讀取的數(shù)據(jù)是正確的。消息隊(duì)列通信的速度不是最及時(shí)的,畢竟每次數(shù)據(jù)的寫入和讀取都需要經(jīng)過用戶態(tài)與內(nèi)核態(tài)之間的拷貝過程。
- 共享內(nèi)存可以解決消息隊(duì)列通信中用戶態(tài)與內(nèi)核態(tài)之間數(shù)據(jù)拷貝過程帶來的開銷,它直接分配一個(gè)共享空間,每個(gè)進(jìn)程都可以直接訪問,就像訪問進(jìn)程自己的空間一樣快捷方便,不需要陷入內(nèi)核態(tài)或者系統(tǒng)調(diào)用,大大提高了通信的速度,享有最快的進(jìn)程間通信方式之名。但是便捷高效的共享內(nèi)存通信,帶來新的問題,多進(jìn)程競(jìng)爭(zhēng)同個(gè)共享資源會(huì)造成數(shù)據(jù)的錯(cuò)亂。
- 那么,就需要信號(hào)量來保護(hù)共享資源,以確保任何時(shí)刻只能有一個(gè)進(jìn)程訪問共享資源,這種方式就是互斥訪問。信號(hào)量不僅可以實(shí)現(xiàn)訪問的互斥性,還可以實(shí)現(xiàn)進(jìn)程間的同步,信號(hào)量其實(shí)是一個(gè)計(jì)數(shù)器,表示的是資源個(gè)數(shù),其值可以通過兩個(gè)原子操作來控制,分別是 P 操作和 V 操作。
- 與信號(hào)量名字很相似的叫信號(hào),它倆名字雖然相似,但功能一點(diǎn)兒都不一樣。信號(hào)是異步通信機(jī)制,信號(hào)可以在應(yīng)用進(jìn)程和內(nèi)核之間直接交互,內(nèi)核也可以利用信號(hào)來通知用戶空間的進(jìn)程發(fā)生了哪些系統(tǒng)事件,信號(hào)事件的來源主要有硬件來源(如鍵盤 Cltr+C )和軟件來源(如 kill 命令),一旦有信號(hào)發(fā)生,進(jìn)程有三種方式響應(yīng)信號(hào) 1. 執(zhí)行默認(rèn)操作、2. 捕捉信號(hào)、3. 忽略信號(hào)。有兩個(gè)信號(hào)是應(yīng)用進(jìn)程無法捕捉和忽略的,即 SIGKILL 和 SIGSTOP,這是為了方便我們能在任何時(shí)候結(jié)束或停止某個(gè)進(jìn)程。
- 前面說到的通信機(jī)制,都是工作于同一臺(tái)主機(jī),如果要與不同主機(jī)的進(jìn)程間通信,那么就需要 Socket 通信了。Socket 實(shí)際上不僅用于不同的主機(jī)進(jìn)程間通信,還可以用于本地主機(jī)進(jìn)程間通信,可根據(jù)創(chuàng)建 Socket 的類型不同,分為三種常見的通信方式,一個(gè)是基于 TCP 協(xié)議的通信方式,一個(gè)是基于 UDP 協(xié)議的通信方式,一個(gè)是本地進(jìn)程間通信方式。
kill -9 使用的是哪種?
- 信號(hào)
fork創(chuàng)建子進(jìn)程有哪些特點(diǎn)呢?
- 父子進(jìn)程:fork調(diào)用后,會(huì)創(chuàng)建一個(gè)新的子進(jìn)程,該子進(jìn)程與父進(jìn)程幾乎完全相同,包括代碼、數(shù)據(jù)和打開文件等。子進(jìn)程從fork調(diào)用的位置開始執(zhí)行,父進(jìn)程和子進(jìn)程在fork調(diào)用之后的代碼處繼續(xù)執(zhí)行。
- 資源繼承:子進(jìn)程繼承了父進(jìn)程的大部分資源,包括打開的文件、文件描述符、信號(hào)處理器等。但是有些資源(如互斥鎖和定時(shí)器)可能需要進(jìn)行特殊處理,以避免競(jìng)爭(zhēng)條件或資源泄漏。
- 內(nèi)存:父進(jìn)程和子進(jìn)程擁有獨(dú)立的虛擬內(nèi)存空間,每個(gè)進(jìn)程都有自己的內(nèi)存映射表。子進(jìn)程通過寫時(shí)復(fù)制(copy-on-write)機(jī)制與父進(jìn)程共享物理內(nèi)存,只有在需要修改內(nèi)存內(nèi)容時(shí)才會(huì)進(jìn)行復(fù)制。
- 父子關(guān)系:父進(jìn)程可以通過fork的返回值判斷是否為子進(jìn)程。父進(jìn)程的fork返回子進(jìn)程的PID,而子進(jìn)程的fork返回0。這樣可以根據(jù)返回值的不同,在父子進(jìn)程中執(zhí)行不同的邏輯。
Copy On Write技術(shù)介紹一下
在創(chuàng)建子進(jìn)程的過程中,操作系統(tǒng)會(huì)把父進(jìn)程的「頁(yè)表」復(fù)制一份給子進(jìn)程,這個(gè)頁(yè)表記錄著虛擬地址和物理地址映射關(guān)系,而不會(huì)復(fù)制物理內(nèi)存,也就是說,兩者的虛擬空間不同,但其對(duì)應(yīng)的物理空間是同一個(gè)。
 圖片
圖片
這樣一來,子進(jìn)程就共享了父進(jìn)程的物理內(nèi)存數(shù)據(jù)了,這樣能夠節(jié)約物理內(nèi)存資源,頁(yè)表對(duì)應(yīng)的頁(yè)表項(xiàng)的屬性會(huì)標(biāo)記該物理內(nèi)存的權(quán)限為只讀。
當(dāng)父進(jìn)程或者子進(jìn)程在向共享內(nèi)存發(fā)起寫操作時(shí),CPU 就會(huì)觸發(fā)寫保護(hù)中斷,這個(gè)「寫保護(hù)中斷」是由于違反權(quán)限導(dǎo)致的,然后操作系統(tǒng)會(huì)在「寫保護(hù)中斷處理函數(shù)」里進(jìn)行物理內(nèi)存的復(fù)制,并重新設(shè)置其內(nèi)存映射關(guān)系,將父子進(jìn)程的內(nèi)存讀寫權(quán)限設(shè)置為可讀寫,最后才會(huì)對(duì)內(nèi)存進(jìn)行寫操作,這個(gè)過程被稱為「**寫時(shí)復(fù)制(Copy On Write)**」。
 圖片
圖片
寫時(shí)復(fù)制顧名思義,在發(fā)生寫操作的時(shí)候,操作系統(tǒng)才會(huì)去復(fù)制物理內(nèi)存,這樣是為了防止 fork 創(chuàng)建子進(jìn)程時(shí),由于物理內(nèi)存數(shù)據(jù)的復(fù)制時(shí)間過長(zhǎng)而導(dǎo)致父進(jìn)程長(zhǎng)時(shí)間阻塞的問題。
Java
ArrayList和LinkedList的區(qū)別?
- 底層數(shù)據(jù)結(jié)構(gòu):ArrayList使用數(shù)組作為底層數(shù)據(jù)結(jié)構(gòu),而LinkedList使用雙向鏈表作為底層數(shù)據(jù)結(jié)構(gòu)
- 隨機(jī)訪問性能:ArrayList支持通過索引直接訪問元素,因?yàn)榈讓訑?shù)組的連續(xù)存儲(chǔ)特性,所以時(shí)間復(fù)雜度為O(1)。而LinkedList需要從頭或尾部開始遍歷鏈表,時(shí)間復(fù)雜度為O(n)。
- 插入和刪除操作:ArrayList在尾部插入和刪除元素的時(shí)間復(fù)雜度為O(1),因?yàn)樗恍枰{(diào)整數(shù)組的長(zhǎng)度即可。但在中間或頭部插入和刪除元素時(shí),需要將后續(xù)元素進(jìn)行移動(dòng),時(shí)間復(fù)雜度為O(n)。而LinkedList在任意位置插入和刪除元素的時(shí)間復(fù)雜度為O(1),因?yàn)橹恍枰{(diào)整節(jié)點(diǎn)的指針即可。
- 內(nèi)存占用:ArrayList在每個(gè)元素中都存儲(chǔ)了實(shí)際的數(shù)據(jù),而LinkedList在每個(gè)節(jié)點(diǎn)中存儲(chǔ)了數(shù)據(jù)和前后節(jié)點(diǎn)的指針。因此,相同數(shù)量的元素情況下,LinkedList通常比ArrayList占用更多的內(nèi)存空間。
在使用時(shí)候,這兩者的應(yīng)用場(chǎng)景是什么?
- 如果需要頻繁進(jìn)行隨機(jī)訪問操作,而對(duì)插入和刪除操作要求不高,可以選擇ArrayList。
- 如果需要頻繁進(jìn)行插入和刪除操作,而對(duì)隨機(jī)訪問操作要求不高,可以選擇LinkedList。
HashMap的底層數(shù)據(jù)結(jié)構(gòu)是什么?
在 JDK 1.7 版本之前, HashMap 數(shù)據(jù)結(jié)構(gòu)是數(shù)組和鏈表,HashMap通過哈希算法將元素的鍵(Key)映射到數(shù)組中的槽位(Bucket)。如果多個(gè)鍵映射到同一個(gè)槽位,它們會(huì)以鏈表的形式存儲(chǔ)在同一個(gè)槽位上,因?yàn)殒湵淼牟樵儠r(shí)間是O(n),所以沖突很嚴(yán)重,一個(gè)索引上的鏈表非常長(zhǎng),效率就很低了。
所以在 JDK 1.8版本的時(shí)候做了優(yōu)化,當(dāng)一個(gè)鏈表的長(zhǎng)度超過8的時(shí)候就轉(zhuǎn)換數(shù)據(jù)結(jié)構(gòu),不再使用鏈表存儲(chǔ),而是使用紅黑樹,查找時(shí)使用紅黑樹,時(shí)間復(fù)雜度O(log n),可以提高查詢性能,但是在數(shù)量較少時(shí),即數(shù)量小于6時(shí),會(huì)將紅黑樹轉(zhuǎn)換回鏈表。
 圖片
圖片
HashMap會(huì)產(chǎn)生哪些并發(fā)安全?
- JDK 1.7 HashMap 采用數(shù)組 + 鏈表的數(shù)據(jù)結(jié)構(gòu),多線程背景下,在數(shù)組擴(kuò)容的時(shí)候,存在 Entry 鏈死循環(huán)和數(shù)據(jù)丟失問題。
- JDK 1.8 HashMap 采用數(shù)組 + 鏈表 + 紅黑二叉樹的數(shù)據(jù)結(jié)構(gòu),優(yōu)化了 1.7 中數(shù)組擴(kuò)容的方案,解決了 Entry 鏈死循環(huán)和數(shù)據(jù)丟失問題。但是多線程背景下,put 方法存在數(shù)據(jù)覆蓋的問題。
說一下ConcurrentHashMap是如何實(shí)現(xiàn)的線程安全的?
JDK 1.7 ConcurrentHashMap
在 JDK 1.7 中它使用的是數(shù)組加鏈表的形式實(shí)現(xiàn)的,而數(shù)組又分為:大數(shù)組 Segment 和小數(shù)組 HashEntry。Segment 是一種可重入鎖(ReentrantLock),在 ConcurrentHashMap 里扮演鎖的角色;HashEntry 則用于存儲(chǔ)鍵值對(duì)數(shù)據(jù)。一個(gè) ConcurrentHashMap 里包含一個(gè) Segment 數(shù)組,一個(gè) Segment 里包含一個(gè) HashEntry 數(shù)組,每個(gè) HashEntry 是一個(gè)鏈表結(jié)構(gòu)的元素。
分段鎖技術(shù)將數(shù)據(jù)分成一段一段的存儲(chǔ),然后給每一段數(shù)據(jù)配一把鎖,當(dāng)一個(gè)線程占用鎖訪問其中一個(gè)段數(shù)據(jù)的時(shí)候,其他段的數(shù)據(jù)也能被其他線程訪問,能夠?qū)崿F(xiàn)真正的并發(fā)訪問。
JDK 1.8 ConcurrentHashMap
在 JDK 1.7 中,ConcurrentHashMap 雖然是線程安全的,但因?yàn)樗牡讓訉?shí)現(xiàn)是數(shù)組 + 鏈表的形式,所以在數(shù)據(jù)比較多的情況下訪問是很慢的,因?yàn)橐闅v整個(gè)鏈表,而 JDK 1.8 則使用了數(shù)組 + 鏈表/紅黑樹的方式優(yōu)化了 ConcurrentHashMap 的實(shí)現(xiàn),具體實(shí)現(xiàn)結(jié)構(gòu)如下:
JDK 1.8 ConcurrentHashMap 主要通過 volatile + CAS 或者 synchronized 來實(shí)現(xiàn)的線程安全的。
添加元素時(shí)首先會(huì)判斷容器是否為空:
- 如果為空則使用 volatile 加 CAS 來初始化,如果容器不為空,則根據(jù)存儲(chǔ)的元素計(jì)算該位置是否為空。
如果根據(jù)存儲(chǔ)的元素計(jì)算結(jié)果為空,則利用 CAS 設(shè)置該節(jié)點(diǎn);
如果根據(jù)存儲(chǔ)的元素計(jì)算結(jié)果不為空,則使用 synchronized ,然后,遍歷桶中的數(shù)據(jù),并替換或新增節(jié)點(diǎn)到桶中,最后再判斷是否需要轉(zhuǎn)為紅黑樹,這樣就能保證并發(fā)訪問時(shí)的線程安全了。
如果把上面的執(zhí)行用一句話歸納的話,就相當(dāng)于是ConcurrentHashMap通過對(duì)頭結(jié)點(diǎn)加鎖來保證線程安全的,鎖的粒度相比 Segment 來說更小了,發(fā)生沖突和加鎖的頻率降低了,并發(fā)操作的性能就提高了。而且 JDK 1.8 使用的是紅黑樹優(yōu)化了之前的固定鏈表,那么當(dāng)數(shù)據(jù)量比較大的時(shí)候,查詢性能也得到了很大的提升,從之前的 O(n) 優(yōu)化到了 O(logn) 的時(shí)間復(fù)雜度。
除了ConcurrentHashMap,還可以如何將HashMap變?yōu)榫€程安全的?
- 將 HashMap 替換成HashTable,HashTable是線程安全的。
- 使用Collections.synchronizedMap方法:可以使用Collections.synchronizedMap方法創(chuàng)建一個(gè)線程安全的HashMap,它會(huì)返回一個(gè)包裝后的線程安全的Map對(duì)象。該方法使用了內(nèi)部的同步機(jī)制來保證線程安全,但在高并發(fā)環(huán)境下可能性能較低。
Map<KeyType, ValueType> synchronizedMap = Collections.synchronizedMap(new HashMap<>());Redis
Redis常見的數(shù)據(jù)結(jié)構(gòu)有哪些?以及底層是如何實(shí)現(xiàn)的?
Redis 提供了豐富的數(shù)據(jù)類型,常見的有五種數(shù)據(jù)類型:String(字符串),Hash(哈希),List(列表),Set(集合)、Zset(有序集合)。
 圖片
圖片
- String 類型的應(yīng)用場(chǎng)景:緩存對(duì)象、常規(guī)計(jì)數(shù)、分布式鎖、共享 session 信息等。
- List 類型的應(yīng)用場(chǎng)景:消息隊(duì)列(但是有兩個(gè)問題:1. 生產(chǎn)者需要自行實(shí)現(xiàn)全局唯一 ID;2. 不能以消費(fèi)組形式消費(fèi)數(shù)據(jù))等。
- Hash 類型:緩存對(duì)象、購(gòu)物車等。
- Set 類型:聚合計(jì)算(并集、交集、差集)場(chǎng)景,比如點(diǎn)贊、共同關(guān)注、抽獎(jiǎng)活動(dòng)等。
- Zset 類型:排序場(chǎng)景,比如排行榜、電話和姓名排序等。
我畫了一張 Redis 數(shù)據(jù)類型和底層數(shù)據(jù)結(jié)構(gòu)的對(duì)應(yīng)關(guān)圖,左邊是 Redis 3.0版本的,也就是《Redis 設(shè)計(jì)與實(shí)現(xiàn)》這本書講解的版本,現(xiàn)在看還是有點(diǎn)過時(shí)了,右邊是現(xiàn)在 Redis 7.0 版本的。
String 類型內(nèi)部實(shí)現(xiàn)
String 類型的底層的數(shù)據(jù)結(jié)構(gòu)實(shí)現(xiàn)主要是 SDS(簡(jiǎn)單動(dòng)態(tài)字符串)。SDS 和我們認(rèn)識(shí)的 C 字符串不太一樣,之所以沒有使用 C 語(yǔ)言的字符串表示,因?yàn)?SDS 相比于 C 的原生字符串:
- SDS 不僅可以保存文本數(shù)據(jù),還可以保存二進(jìn)制數(shù)據(jù)。因?yàn)?SDS 使用 len 屬性的值而不是空字符來判斷字符串是否結(jié)束,并且 SDS 的所有 API 都會(huì)以處理二進(jìn)制的方式來處理 SDS 存放在 buf[] 數(shù)組里的數(shù)據(jù)。所以 SDS 不光能存放文本數(shù)據(jù),而且能保存圖片、音頻、視頻、壓縮文件這樣的二進(jìn)制數(shù)據(jù)。
- **SDS 獲取字符串長(zhǎng)度的時(shí)間復(fù)雜度是 O(1)**。因?yàn)?C 語(yǔ)言的字符串并不記錄自身長(zhǎng)度,所以獲取長(zhǎng)度的復(fù)雜度為 O(n);而 SDS 結(jié)構(gòu)里用 len 屬性記錄了字符串長(zhǎng)度,所以復(fù)雜度為 O(1)。
- Redis 的 SDS API 是安全的,拼接字符串不會(huì)造成緩沖區(qū)溢出。因?yàn)?SDS 在拼接字符串之前會(huì)檢查 SDS 空間是否滿足要求,如果空間不夠會(huì)自動(dòng)擴(kuò)容,所以不會(huì)導(dǎo)致緩沖區(qū)溢出的問題。
List 類型內(nèi)部實(shí)現(xiàn)
List 類型的底層數(shù)據(jù)結(jié)構(gòu)是由雙向鏈表或壓縮列表實(shí)現(xiàn)的:
- 如果列表的元素個(gè)數(shù)小于 512 個(gè)(默認(rèn)值,可由 list-max-ziplist-entries 配置),列表每個(gè)元素的值都小于 64 字節(jié)(默認(rèn)值,可由 list-max-ziplist-value 配置),Redis 會(huì)使用壓縮列表作為 List 類型的底層數(shù)據(jù)結(jié)構(gòu);
- 如果列表的元素不滿足上面的條件,Redis 會(huì)使用雙向鏈表作為 List 類型的底層數(shù)據(jù)結(jié)構(gòu);
但是在 Redis 3.2 版本之后,List 數(shù)據(jù)類型底層數(shù)據(jù)結(jié)構(gòu)就只由 quicklist 實(shí)現(xiàn)了,替代了雙向鏈表和壓縮列表。
Hash 類型內(nèi)部實(shí)現(xiàn)
Hash 類型的底層數(shù)據(jù)結(jié)構(gòu)是由壓縮列表或哈希表實(shí)現(xiàn)的:
- 如果哈希類型元素個(gè)數(shù)小于 512 個(gè)(默認(rèn)值,可由 hash-max-ziplist-entries 配置),所有值小于 64 字節(jié)(默認(rèn)值,可由 hash-max-ziplist-value 配置)的話,Redis 會(huì)使用壓縮列表作為 Hash 類型的底層數(shù)據(jù)結(jié)構(gòu);
- 如果哈希類型元素不滿足上面條件,Redis 會(huì)使用哈希表作為 Hash 類型的底層數(shù)據(jù)結(jié)構(gòu)。
在 Redis 7.0 中,壓縮列表數(shù)據(jù)結(jié)構(gòu)已經(jīng)廢棄了,交由 listpack 數(shù)據(jù)結(jié)構(gòu)來實(shí)現(xiàn)了。
Set 類型內(nèi)部實(shí)現(xiàn)
Set 類型的底層數(shù)據(jù)結(jié)構(gòu)是由哈希表或整數(shù)集合實(shí)現(xiàn)的:
- 如果集合中的元素都是整數(shù)且元素個(gè)數(shù)小于 512 (默認(rèn)值,set-maxintset-entries配置)個(gè),Redis 會(huì)使用整數(shù)集合作為 Set 類型的底層數(shù)據(jù)結(jié)構(gòu);
- 如果集合中的元素不滿足上面條件,則 Redis 使用哈希表作為 Set 類型的底層數(shù)據(jù)結(jié)構(gòu)。
ZSet 類型內(nèi)部實(shí)現(xiàn)
Zset 類型的底層數(shù)據(jù)結(jié)構(gòu)是由壓縮列表或跳表實(shí)現(xiàn)的:
- 如果有序集合的元素個(gè)數(shù)小于 128 個(gè),并且每個(gè)元素的值小于 64 字節(jié)時(shí),Redis 會(huì)使用壓縮列表作為 Zset 類型的底層數(shù)據(jù)結(jié)構(gòu);
- 如果有序集合的元素不滿足上面的條件,Redis 會(huì)使用跳表作為 Zset 類型的底層數(shù)據(jù)結(jié)構(gòu);
在 Redis 7.0 中,壓縮列表數(shù)據(jù)結(jié)構(gòu)已經(jīng)廢棄了,交由 listpack 數(shù)據(jù)結(jié)構(gòu)來實(shí)現(xiàn)了。
項(xiàng)目中為什么引入Redis呢?和本地緩存有哪些區(qū)別?
- 主要是為了提升查詢效率,減少對(duì)MySQL的訪問。
- Redis 提供了豐富的數(shù)據(jù)類型,能滿足各種業(yè)務(wù)場(chǎng)景,并且Redis還可以進(jìn)行集群擴(kuò)展,以及實(shí)現(xiàn)分布式鎖,這是本地緩存做不到的。
如果Redis數(shù)據(jù)超過內(nèi)存限制,該如何處理?
在配置文件 redis.conf 中,可以通過參數(shù) maxmemory <bytes> 來設(shè)定最大運(yùn)行內(nèi)存,只有在 Redis 的運(yùn)行內(nèi)存達(dá)到了我們?cè)O(shè)置的最大運(yùn)行內(nèi)存,才會(huì)觸發(fā)內(nèi)存淘汰策略。不同位數(shù)的操作系統(tǒng),maxmemory 的默認(rèn)值是不同的:
- 在 64 位操作系統(tǒng)中,maxmemory 的默認(rèn)值是 0,表示沒有內(nèi)存大小限制,那么不管用戶存放多少數(shù)據(jù)到 Redis 中,Redis 也不會(huì)對(duì)可用內(nèi)存進(jìn)行檢查,直到 Redis 實(shí)例因內(nèi)存不足而崩潰也無作為。
- 在 32 位操作系統(tǒng)中,maxmemory 的默認(rèn)值是 3G,因?yàn)?32 位的機(jī)器最大只支持 4GB 的內(nèi)存,而系統(tǒng)本身就需要一定的內(nèi)存資源來支持運(yùn)行,所以 32 位操作系統(tǒng)限制最大 3 GB 的可用內(nèi)存是非常合理的,這樣可以避免因?yàn)閮?nèi)存不足而導(dǎo)致 Redis 實(shí)例崩潰。
Redis 內(nèi)存淘汰策略共有八種,這八種策略大體分為「不進(jìn)行數(shù)據(jù)淘汰」和「進(jìn)行數(shù)據(jù)淘汰」兩類策略。
1、不進(jìn)行數(shù)據(jù)淘汰的策略
noeviction(Redis3.0之后,默認(rèn)的內(nèi)存淘汰策略) :它表示當(dāng)運(yùn)行內(nèi)存超過最大設(shè)置內(nèi)存時(shí),不淘汰任何數(shù)據(jù),這時(shí)如果有新的數(shù)據(jù)寫入,會(huì)報(bào)錯(cuò)通知禁止寫入,不淘汰任何數(shù)據(jù),但是如果沒用數(shù)據(jù)寫入的話,只是單純的查詢或者刪除操作的話,還是可以正常工作。
2、進(jìn)行數(shù)據(jù)淘汰的策略
針對(duì)「進(jìn)行數(shù)據(jù)淘汰」這一類策略,又可以細(xì)分為「在設(shè)置了過期時(shí)間的數(shù)據(jù)中進(jìn)行淘汰」和「在所有數(shù)據(jù)范圍內(nèi)進(jìn)行淘汰」這兩類策略。
在設(shè)置了過期時(shí)間的數(shù)據(jù)中進(jìn)行淘汰:
- volatile-random:隨機(jī)淘汰設(shè)置了過期時(shí)間的任意鍵值;
- volatile-ttl:優(yōu)先淘汰更早過期的鍵值。
- volatile-lru(Redis3.0 之前,默認(rèn)的內(nèi)存淘汰策略):淘汰所有設(shè)置了過期時(shí)間的鍵值中,最久未使用的鍵值;
- volatile-lfu(Redis 4.0 后新增的內(nèi)存淘汰策略):淘汰所有設(shè)置了過期時(shí)間的鍵值中,最少使用的鍵值;
在所有數(shù)據(jù)范圍內(nèi)進(jìn)行淘汰:
- allkeys-random:隨機(jī)淘汰任意鍵值;
- allkeys-lru:淘汰整個(gè)鍵值中最久未使用的鍵值;
- allkeys-lfu(Redis 4.0 后新增的內(nèi)存淘汰策略):淘汰整個(gè)鍵值中最少使用的鍵值。
Redis緩存過期如何實(shí)現(xiàn)的?底層呢?
Redis 選擇「惰性刪除+定期刪除」這兩種策略配和使用,以求在合理使用 CPU 時(shí)間和避免內(nèi)存浪費(fèi)之間取得平衡。
Redis 是怎么實(shí)現(xiàn)惰性刪除的?
Redis 的惰性刪除策略由 db.c 文件中的 expireIfNeeded 函數(shù)實(shí)現(xiàn),代碼如下:
int expireIfNeeded(redisDb *db, robj *key) {
// 判斷 key 是否過期
if (!keyIsExpired(db,key)) return 0;
....
/* 刪除過期鍵 */
....
// 如果 server.lazyfree_lazy_expire 為 1 表示異步刪除,反之同步刪除;
return server.lazyfree_lazy_expire ? dbAsyncDelete(db,key) :
dbSyncDelete(db,key);
}Redis 在訪問或者修改 key 之前,都會(huì)調(diào)用 expireIfNeeded 函數(shù)對(duì)其進(jìn)行檢查,檢查 key 是否過期:
- 如果過期,則刪除該 key,至于選擇異步刪除,還是選擇同步刪除,根據(jù) lazyfree_lazy_expire 參數(shù)配置決定(Redis 4.0版本開始提供參數(shù)),然后返回 null 客戶端;
- 如果沒有過期,不做任何處理,然后返回正常的鍵值對(duì)給客戶端;
惰性刪除的流程圖如下:
 圖片
圖片
Redis 是怎么實(shí)現(xiàn)定期刪除的?
再回憶一下,定期刪除策略的做法:每隔一段時(shí)間「隨機(jī)」從數(shù)據(jù)庫(kù)中取出一定數(shù)量的 key 進(jìn)行檢查,并刪除其中的過期key。
1、這個(gè)間隔檢查的時(shí)間是多長(zhǎng)呢?
在 Redis 中,默認(rèn)每秒進(jìn)行 10 次過期檢查一次數(shù)據(jù)庫(kù),此配置可通過 Redis 的配置文件 redis.conf 進(jìn)行配置,配置鍵為 hz 它的默認(rèn)值是 hz 10。
特別強(qiáng)調(diào)下,每次檢查數(shù)據(jù)庫(kù)并不是遍歷過期字典中的所有 key,而是從數(shù)據(jù)庫(kù)中隨機(jī)抽取一定數(shù)量的 key 進(jìn)行過期檢查。
2、隨機(jī)抽查的數(shù)量是多少呢?
我查了下源碼,定期刪除的實(shí)現(xiàn)在 expire.c 文件下的 activeExpireCycle 函數(shù)中,其中隨機(jī)抽查的數(shù)量由 ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP 定義的,它是寫死在代碼中的,數(shù)值是 20。
也就是說,數(shù)據(jù)庫(kù)每輪抽查時(shí),會(huì)隨機(jī)選擇 20 個(gè) key 判斷是否過期。
接下來,詳細(xì)說說 Redis 的定期刪除的流程:
- 從過期字典中隨機(jī)抽取 20 個(gè) key;
- 檢查這 20 個(gè) key 是否過期,并刪除已過期的 key;
- 如果本輪檢查的已過期 key 的數(shù)量,超過 5 個(gè)(20/4),也就是「已過期 key 的數(shù)量」占比「隨機(jī)抽取 key 的數(shù)量」大于 25%,則繼續(xù)重復(fù)步驟 1;如果已過期的 key 比例小于 25%,則停止繼續(xù)刪除過期 key,然后等待下一輪再檢查。
可以看到,定期刪除是一個(gè)循環(huán)的流程。
那 Redis 為了保證定期刪除不會(huì)出現(xiàn)循環(huán)過度,導(dǎo)致線程卡死現(xiàn)象,為此增加了定期刪除循環(huán)流程的時(shí)間上限,默認(rèn)不會(huì)超過 25ms。
針對(duì)定期刪除的流程,我寫了個(gè)偽代碼:
do {
//已過期的數(shù)量
expired = 0;
//隨機(jī)抽取的數(shù)量
num = 20;
while (num--) {
//1. 從過期字典中隨機(jī)抽取 1 個(gè) key
//2. 判斷該 key 是否過期,如果已過期則進(jìn)行刪除,同時(shí)對(duì) expired++
}
// 超過時(shí)間限制則退出
if (timelimit_exit) return;
/* 如果本輪檢查的已過期 key 的數(shù)量,超過 25%,則繼續(xù)隨機(jī)抽查,否則退出本輪檢查 */
} while (expired > 20/4);定期刪除的流程如下:
 圖片
圖片
介紹RDB持久化機(jī)制的詳細(xì)過程吧
因?yàn)?AOF 日志記錄的是操作命令,不是實(shí)際的數(shù)據(jù),所以用 AOF 方法做故障恢復(fù)時(shí),需要全量把日志都執(zhí)行一遍,一旦 AOF 日志非常多,勢(shì)必會(huì)造成 Redis 的恢復(fù)操作緩慢。
為了解決這個(gè)問題,Redis 增加了 RDB 快照。所謂的快照,就是記錄某一個(gè)瞬間東西,比如當(dāng)我們給風(fēng)景拍照時(shí),那一個(gè)瞬間的畫面和信息就記錄到了一張照片。
所以,RDB 快照就是記錄某一個(gè)瞬間的內(nèi)存數(shù)據(jù),記錄的是實(shí)際數(shù)據(jù),而 AOF 文件記錄的是命令操作的日志,而不是實(shí)際的數(shù)據(jù)。
因此在 Redis 恢復(fù)數(shù)據(jù)時(shí), RDB 恢復(fù)數(shù)據(jù)的效率會(huì)比 AOF 高些,因?yàn)橹苯訉?RDB 文件讀入內(nèi)存就可以,不需要像 AOF 那樣還需要額外執(zhí)行操作命令的步驟才能恢復(fù)數(shù)據(jù)。
Redis 還可以通過配置文件的選項(xiàng)來實(shí)現(xiàn)每隔一段時(shí)間自動(dòng)執(zhí)行一次 bgsave 命令,默認(rèn)會(huì)提供以下配置:
save 900 1
save 300 10
save 60 10000別看選項(xiàng)名叫 save,實(shí)際上執(zhí)行的是 bgsave 命令,也就是會(huì)創(chuàng)建子進(jìn)程來生成 RDB 快照文件。只要滿足上面條件的任意一個(gè),就會(huì)執(zhí)行 bgsave,它們的意思分別是:
- 900 秒之內(nèi),對(duì)數(shù)據(jù)庫(kù)進(jìn)行了至少 1 次修改;
- 300 秒之內(nèi),對(duì)數(shù)據(jù)庫(kù)進(jìn)行了至少 10 次修改;
- 60 秒之內(nèi),對(duì)數(shù)據(jù)庫(kù)進(jìn)行了至少 10000 次修改。
這里提一點(diǎn),Redis 的快照是全量快照,也就是說每次執(zhí)行快照,都是把內(nèi)存中的「所有數(shù)據(jù)」都記錄到磁盤中。所以執(zhí)行快照是一個(gè)比較重的操作,如果頻率太頻繁,可能會(huì)對(duì) Redis 性能產(chǎn)生影響。如果頻率太低,服務(wù)器故障時(shí),丟失的數(shù)據(jù)會(huì)更多。
執(zhí)行 bgsave 過程中,Redis 依然可以繼續(xù)處理操作命令的,也就是數(shù)據(jù)是能被修改的,關(guān)鍵的技術(shù)就在于寫時(shí)復(fù)制技術(shù)(Copy-On-Write, COW)。
執(zhí)行 bgsave 命令的時(shí)候,會(huì)通過 fork() 創(chuàng)建子進(jìn)程,此時(shí)子進(jìn)程和父進(jìn)程是共享同一片內(nèi)存數(shù)據(jù)的,因?yàn)閯?chuàng)建子進(jìn)程的時(shí)候,會(huì)復(fù)制父進(jìn)程的頁(yè)表,但是頁(yè)表指向的物理內(nèi)存還是一個(gè),此時(shí)如果主線程執(zhí)行讀操作,則主線程和 bgsave 子進(jìn)程互相不影響。
 圖片
圖片
如果主線程執(zhí)行寫操作,則被修改的數(shù)據(jù)會(huì)復(fù)制一份副本,然后 bgsave 子進(jìn)程會(huì)把該副本數(shù)據(jù)寫入 RDB 文件,在這個(gè)過程中,主線程仍然可以直接修改原來的數(shù)據(jù)。
 圖片
圖片
RDB持久化會(huì)阻塞主線程嘛?
Redis 提供了兩個(gè)命令來生成 RDB 文件,分別是 save 和 bgsave,他們的區(qū)別就在于是否在「主線程」里執(zhí)行:
- 執(zhí)行了 save 命令,就會(huì)在主線程生成 RDB 文件,由于和執(zhí)行操作命令在同一個(gè)線程,所以如果寫入 RDB 文件的時(shí)間太長(zhǎng),會(huì)阻塞主線程;
- 執(zhí)行了 bgsave 命令,會(huì)創(chuàng)建一個(gè)子進(jìn)程來生成 RDB 文件,這樣可以避免主線程的阻塞;
MySQL
MySQL的char和varchar有什么區(qū)別?
區(qū)別如下:
- 存儲(chǔ)方式:char類型是固定長(zhǎng)度的字符類型,它會(huì)以指定的長(zhǎng)度存儲(chǔ)每個(gè)字符,無論實(shí)際存儲(chǔ)的字符長(zhǎng)度是多少。varchar類型是可變長(zhǎng)度的字符類型,它會(huì)根據(jù)實(shí)際存儲(chǔ)的字符長(zhǎng)度來動(dòng)態(tài)調(diào)整存儲(chǔ)空間。
- 空間占用:由于char類型是固定長(zhǎng)度的,所以它在存儲(chǔ)時(shí)會(huì)占用固定的空間,無論實(shí)際存儲(chǔ)的字符長(zhǎng)度是多少。而varchar類型在存儲(chǔ)時(shí)只會(huì)占用實(shí)際使用的空間,因此在存儲(chǔ)短字符時(shí),varchar比char更節(jié)省空間。
- 應(yīng)用場(chǎng)景:如果的數(shù)據(jù)長(zhǎng)度固定且相對(duì)較短,可以考慮使用char類型;如果您的數(shù)據(jù)長(zhǎng)度可變或相對(duì)較長(zhǎng),可以考慮使用varchar類型。
索引有哪些分類嘛?
可以按照四個(gè)角度來分類索引。
- 按「數(shù)據(jù)結(jié)構(gòu)」分類:B+tree索引、Hash索引、Full-text索引。
- 按「物理存儲(chǔ)」分類:聚簇索引(主鍵索引)、二級(jí)索引(輔助索引)。
- 按「字段特性」分類:主鍵索引、唯一索引、普通索引、前綴索引。
- 按「字段個(gè)數(shù)」分類:?jiǎn)瘟兴饕⒙?lián)合索引。
有什么索引優(yōu)化的方式?
- 前綴索引優(yōu)化:前綴索引顧名思義就是使用某個(gè)字段中字符串的前幾個(gè)字符建立索引,使用前綴索引是為了減小索引字段大小,可以增加一個(gè)索引頁(yè)中存儲(chǔ)的索引值,有效提高索引的查詢速度。在一些大字符串的字段作為索引時(shí),使用前綴索引可以幫助我們減小索引項(xiàng)的大小。
- 覆蓋索引優(yōu)化:覆蓋索引是指 SQL 中 query 的所有字段,在索引 B+Tree 的葉子節(jié)點(diǎn)上都能找得到的那些索引,從二級(jí)索引中查詢得到記錄,而不需要通過聚簇索引查詢獲得,可以避免回表的操作。
- 主鍵索引最好是自增的;如果我們使用非自增主鍵,由于每次插入主鍵的索引值都是隨機(jī)的,因此每次插入新的數(shù)據(jù)時(shí),就可能會(huì)插入到現(xiàn)有數(shù)據(jù)頁(yè)中間的某個(gè)位置,這將不得不移動(dòng)其它數(shù)據(jù)來滿足新數(shù)據(jù)的插入,甚至需要從一個(gè)頁(yè)面復(fù)制數(shù)據(jù)到另外一個(gè)頁(yè)面,我們通常將這種情況稱為頁(yè)分裂。頁(yè)分裂還有可能會(huì)造成大量的內(nèi)存碎片,導(dǎo)致索引結(jié)構(gòu)不緊湊,從而影響查詢效率。
- 防止索引失效:用上了索引并不意味著查詢的時(shí)候會(huì)使用到索引,所以我們心里要清楚有哪些情況會(huì)導(dǎo)致索引失效,從而避免寫出索引失效的查詢語(yǔ)句,否則這樣的查詢效率是很低的。
說一下Explain會(huì)返回哪些參數(shù)?
下圖,就是一個(gè)沒有使用索引,并且是一個(gè)全表掃描的查詢語(yǔ)句。
 圖片
圖片
對(duì)于執(zhí)行計(jì)劃,參數(shù)有:
- possible_keys 字段表示可能用到的索引;
- key 字段表示實(shí)際用的索引,如果這一項(xiàng)為 NULL,說明沒有使用索引;
- key_len 表示索引的長(zhǎng)度;
- rows 表示掃描的數(shù)據(jù)行數(shù)。
- type 表示數(shù)據(jù)掃描類型,我們需要重點(diǎn)看這個(gè)。
type 字段就是描述了找到所需數(shù)據(jù)時(shí)使用的掃描方式是什么,常見掃描類型的執(zhí)行效率從低到高的順序?yàn)椋?/p>
- All(全表掃描);
- index(全索引掃描);
- range(索引范圍掃描);
- ref(非唯一索引掃描);
- eq_ref(唯一索引掃描);
- const(結(jié)果只有一條的主鍵或唯一索引掃描)。
在這些情況里,all 是最壞的情況,因?yàn)椴捎昧巳頀呙璧姆绞健ndex 和 all 差不多,只不過 index 對(duì)索引表進(jìn)行全掃描,這樣做的好處是不再需要對(duì)數(shù)據(jù)進(jìn)行排序,但是開銷依然很大。所以,要盡量避免全表掃描和全索引掃描。
range 表示采用了索引范圍掃描,一般在 where 子句中使用 < 、>、in、between 等關(guān)鍵詞,只檢索給定范圍的行,屬于范圍查找。從這一級(jí)別開始,索引的作用會(huì)越來越明顯,因此我們需要盡量讓 SQL 查詢可以使用到 range 這一級(jí)別及以上的 type 訪問方式。
ref 類型表示采用了非唯一索引,或者是唯一索引的非唯一性前綴,返回?cái)?shù)據(jù)返回可能是多條。因?yàn)殡m然使用了索引,但該索引列的值并不唯一,有重復(fù)。這樣即使使用索引快速查找到了第一條數(shù)據(jù),仍然不能停止,要進(jìn)行目標(biāo)值附近的小范圍掃描。但它的好處是它并不需要掃全表,因?yàn)樗饕怯行虻模幢阌兄貜?fù)值,也是在一個(gè)非常小的范圍內(nèi)掃描。
eq_ref 類型是使用主鍵或唯一索引時(shí)產(chǎn)生的訪問方式,通常使用在多表聯(lián)查中。比如,對(duì)兩張表進(jìn)行聯(lián)查,關(guān)聯(lián)條件是兩張表的 user_id 相等,且 user_id 是唯一索引,那么使用 EXPLAIN 進(jìn)行執(zhí)行計(jì)劃查看的時(shí)候,type 就會(huì)顯示 eq_ref。
const 類型表示使用了主鍵或者唯一索引與常量值進(jìn)行比較,比如 select name from product where id=1。
需要說明的是 const 類型和 eq_ref 都使用了主鍵或唯一索引,不過這兩個(gè)類型有所區(qū)別,const 是與常量進(jìn)行比較,查詢效率會(huì)更快,而 eq_ref 通常用于多表聯(lián)查中。
除了關(guān)注 type,我們也要關(guān)注 extra 顯示的結(jié)果。
這里說幾個(gè)重要的參考指標(biāo):
- Using filesort :當(dāng)查詢語(yǔ)句中包含 group by 操作,而且無法利用索引完成排序操作的時(shí)候, 這時(shí)不得不選擇相應(yīng)的排序算法進(jìn)行,甚至可能會(huì)通過文件排序,效率是很低的,所以要避免這種問題的出現(xiàn)。
- Using temporary:使了用臨時(shí)表保存中間結(jié)果,MySQL 在對(duì)查詢結(jié)果排序時(shí)使用臨時(shí)表,常見于排序 order by 和分組查詢 group by。效率低,要避免這種問題的出現(xiàn)。
- Using index:所需數(shù)據(jù)只需在索引即可全部獲得,不須要再到表中取數(shù)據(jù),也就是使用了覆蓋索引,避免了回表操作,效率不錯(cuò)。
算法
- 樹的層次遍歷
- 輸出樹的最大寬度
- 合并k個(gè)有序數(shù)組