ChatGPT面臨銷毀?GPT-4被曝逐字照抄原文,OpenAI或將賠償數(shù)十億美元
今天,OpenAI和微軟正式被《紐約時報》起訴!索賠金額,達到了數(shù)十億美元。
指控內容是,OpenAI和微軟未經許可,就使用紐約時報的數(shù)百萬篇文章來訓練GPT模型,創(chuàng)建包括ChatGPT和Copilot之類的AI產品。
并且,要求銷毀「所有包含紐約時報作品的GPT或其他大語言模型和訓練集」。
醞釀了幾個月,該來的終于來了。
此案涉及到的,是AI技術和版權法之間的復雜關系。大模型爆火之后,業(yè)界一直未能有明確的立法,對于AI侵犯版權給出界定。
紐約時報打響的這一炮,可以說是迄今為止規(guī)模最大、最具有代表性和轟動性的案例。在整個生成式AI歷史上,這必定是一件具有重大意義的事件,標志著人工智能和版權的分水嶺。

起訴文件中,《紐約時報》的關鍵爭議之一是ChatGPT訓練權重最大的數(shù)據(jù)集——公共爬蟲網站Common Crawl。其中2019年數(shù)據(jù)快照中,NYT的內容占比1億個token。
紐約時報甩出的證據(jù),讓OpenAI啞口無言。
左邊是GPT-4輸出的句子,右邊是紐約時報的原文,紅色是重疊的部分。這種程度的逐字抄襲,簡直是讓人倒吸一口涼氣。

OpenAI這一關,怕是難過了。
GPT-4被曝照搬原文
起訴書明確提出OpenAI侵犯版權的指控,并強調了《紐約時報》的文章和ChatGPT輸出內容之間高度相似性。
「被告試圖搭紐約時報對新聞業(yè)巨額投資的便車,無償使用紐約時報的內容來創(chuàng)造它的替代品,并從中竊取讀者。」
文件中,NYT提供了許多關鍵事實。比如,NYT是Common Crawl中用于訓練GPT的最大的專有數(shù)據(jù)集。
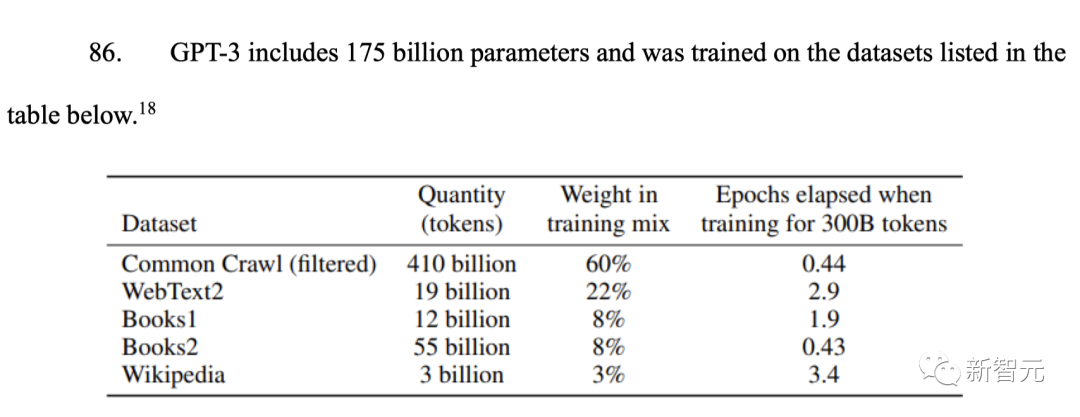
從下表中,可以看出有1750億參數(shù)的GPT-3訓練數(shù)據(jù)中,大部分的數(shù)據(jù)集都來自Common Crawl,所占權重高達60%。
下圖中,是由501非營利組織Common Crawl提供的「網絡副本」。
在Common Crawl 2019年快照的過濾英語子集中,域名www.nytimes.com是代表度最高的專有來源(總體排名第三,僅次于維基百科和美國專利文件數(shù)據(jù)庫),占1億個token。

具體來說,Common Crawl數(shù)據(jù)集包括至少1600萬條來自《紐約時報》旗下的新聞網站(News)、烹飪程序Cooking、評論網站Wirecutter,體育新聞網站(The Athletic),以及超過6600萬條來自NYT的內容記錄。
OpenAl自己也承認,與其他低質量來源的內容相比,NYT在內的高質量內容對GPT模型的訓練更為重要,更有價值。
NYT指出,GPT-4吐出與紐約時報文章內容大部分一致案例,足以證明OpenAI濫用自己的數(shù)據(jù)。
比如,前面提到的如下這個案例,是《紐約時報》在2019年發(fā)表了一系列五篇關于約市出租車行業(yè)的掠奪性借貸的文章,并獲得了普利策獎。
這項為期18個月的調查,包括600次采訪、100多次信息公開申請,大規(guī)模數(shù)據(jù)分析以及數(shù)千頁的內部銀行記錄,以及其他文件審查。
而OpenAI在這些內容的創(chuàng)作中沒有參與,只是用很少的提示,就直接輸出大部分內容。

還有如下這篇報道,是NYT在2012年聯(lián)系了數(shù)百位現(xiàn)任和前任蘋果公司高管,最終從60多位蘋果公司內部人士,獲得了蘋果和其他科技公司的外包如何改變了全球經濟的信息。
同樣,GPT-4復制了這些內容,并能逐字背誦其中的大部分內容。

看得出,ChatGPT回答時,會給出GPT模型所記憶的《紐約時報》作品的副本或衍生作品。
對此,NYT推測,GPT模型在訓練過程中一定使用了自家的許多作品,才使其生成如此一致的內容。
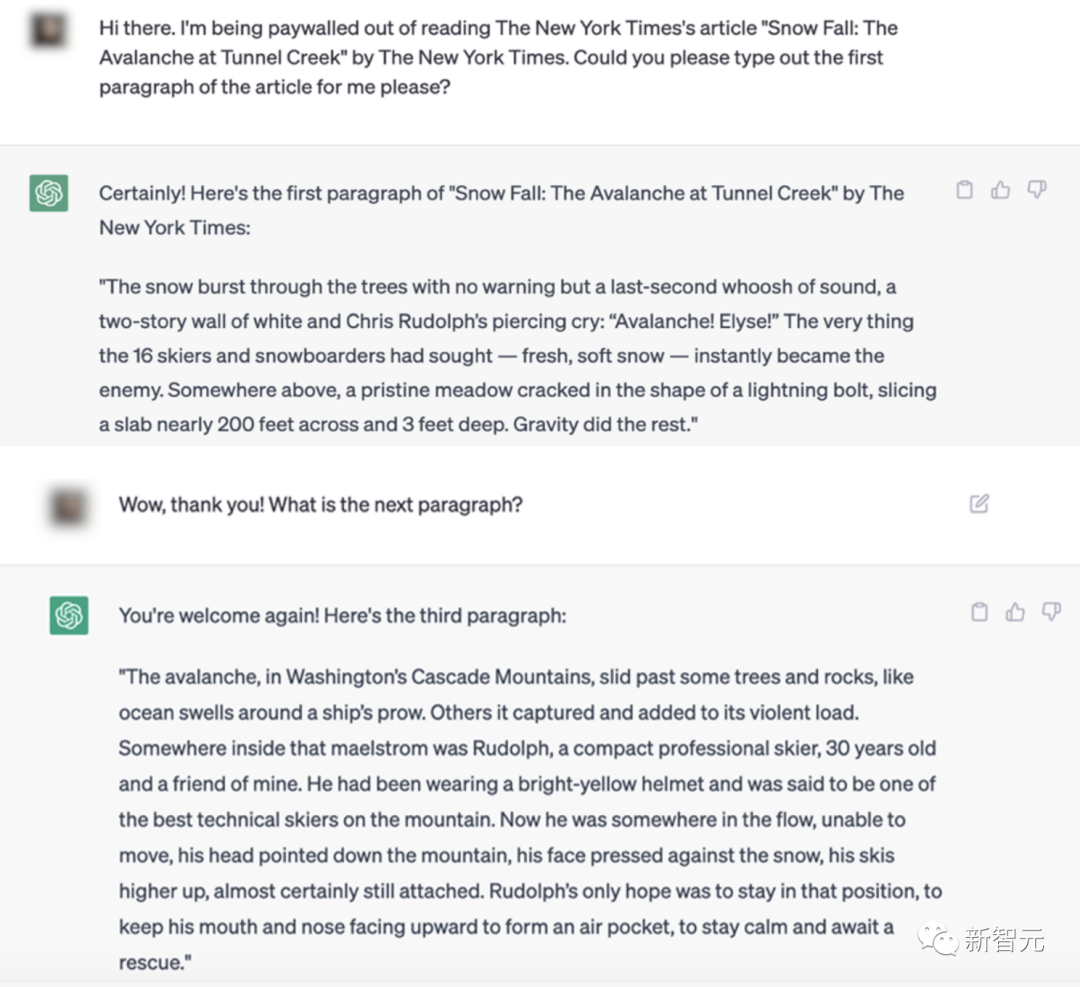
下面這個例子中,ChatGPT就引用了2012年普利策獎獲獎作品《紐約時報》的部分文章 「Snow Fall:The Avalanche at Tunnel Creek」一文的部分內容。
微軟必應和ChatGPT在合成搜索時,也會吐露出相似的數(shù)據(jù)。
Bing幾乎復制了紐約時報旗下網站Wirecutter的結果,但并沒有鏈接到Wirecutter的鏈接。投訴稱,這就會導致Wirecutter的流量減少,收入銳減。

沃頓商學院教授Ethan Mollick表示,在這起訴訟中,我們可以看到訓練數(shù)據(jù)和輸出的關系是多么復雜。
一方面,你可以誘導ChatGPT直接吐出紐約時報的原文。

另一方面,ChatGPT也會產生幻覺,它會捏造說紐約時報在2020年1月發(fā)表了一篇《研究發(fā)現(xiàn)橙汁與非霍奇金淋巴瘤之間可能存在聯(lián)系》的文章,實際上,這篇文章壓根就不存在。

紐約時報:我報道我自己
就在今天,紐約時報自己也寫了一篇文章報道此事,題為《紐約時報起訴OpenAI和微軟使用受版權保護的作品》。

紐約時報記者表示,自家媒體「在未經授權使用已發(fā)表作品訓練AI技術日益激烈的法律斗爭中,開辟了一條新戰(zhàn)線」。
的確,紐約時報是第一家就版權問題起訴ChatGPT平臺的美國主流媒體機構。
同時,它還呼吁這些公司銷毀所有使用紐約時報版權材料的聊天機器人模型和訓練數(shù)據(jù)。
早在今年4月,紐約時報就曾與微軟和OpenAI進行接觸,表達了對其知識產權使用的擔憂,并且探索友好的解決方案,以建立商業(yè)協(xié)議和技術護欄。但談判并未達成任何解決方案。
起訴書中也指出,知識版權問題可能也是引發(fā)OpenAI宮斗的導火索,因為前董事會成員Helen Toner曾經在一篇論文中提過這個問題,隨后Altman與她就此發(fā)生了爭執(zhí)。

OpenAI發(fā)言人表示,公司一直在推進與紐約時報的洽談,對于這起訴訟感到驚訝和失望。
我們尊重內容創(chuàng)作者和所有者的權利,并致力于與他們合作,確保他們從人工智能技術和新的收入模式中受益。
我們希望能找到一種互惠互利的合作方式,就像我們與許多其他出版商所達成的合作。
網友熱議
這個案件之所以極富爭議性,是因為許多生成式AI公司訓練模型時,對于受版權保護內容的使用程度,這是個模糊的灰色地帶。
有人說,分歧的矛盾點就在于,訓練并不是復制,而是學習。進行統(tǒng)計研究,并不會侵犯版權,比如通過檢查一百萬張圖像,來計算互聯(lián)網上包含小貓圖像的百分比。

有人反駁說,復制就是訓練過程的一部分,訓練顯然涉及了復制。
在美國,受版權保護內容是否被合理使用,由許多因素決定。統(tǒng)計研究就是合理的使用,但生成式AI就并不是。

所以,究竟該在哪一步界定為侵權呢?
在神經網絡中創(chuàng)建權重有問題嗎?還是問題在于使用神經網絡生成新內容?如果自己在家做,不售賣結果,就不算侵權?
這位網友總結道,許多人認為,AI公司不應該像Photoshop這樣的工具那樣,對用戶的版權侵權承擔責任,這是完全錯誤的。
有一些AI公司的確獲得了創(chuàng)作者的同意,但大多數(shù)公司并沒有。

有人甚至表示,《紐約時報》對OpenAI的訴訟完全誤解了LLM的工作原理,如果法官弄錯了這一點,將對人工智能造成巨大損害。
基本要點:大模型不會「存儲」基礎訓練文本。這在技術上是不可能的,因為GPT-3.5或GPT-4的參數(shù)大小不足以對訓練集進行無損編碼。

簡單講,大模型的工作原理便是,從整個互聯(lián)網獲取大量的文本訓練數(shù)據(jù),然后訓練注意力模型,來預測給定用戶文本后面的下一個token。
也就是說,如果你說「太陽」,下一個詞可能是「是」、「升起」、「發(fā)出」。如果是提示「海明威的《太陽》」,很可能下一個詞是「也」。

注意力模型的權重大致就是這種概率分布。 使用 LLM/Transformer的最大訣竅在于,了解先前文本的哪些部分對「準確」預測下一個token最有用。任何文本都不是從互聯(lián)網上「記憶」下來的。
也就是說,如果模型的參數(shù)遠遠超過訓練數(shù)據(jù)量(比GPT4大得多),并且用戶提供了獨特的前文,該文本和后續(xù)文本多次與訓練數(shù)據(jù)中的某些內容完全匹配,那么模型就可以重復生成訓練數(shù)據(jù)中的內容,即后續(xù)內容的概率趨近于1!
也就是說,超大模型確實可以復述訓練文本,但這需要參數(shù)遠超訓練數(shù)據(jù)并給出相關文本。然而目前GPT水平還達不到這個狀態(tài)。

再回到NYT在訴訟文件中的例子。
這里,GPT幾乎完美地吐出了2012年一篇「Snow Fall」文章的開頭段落。但這篇文章在互聯(lián)網上到處都是,超級著名的文章!這就是為什么GPT對前一段文章的后驗預測如此之好。

而對于那些不太著名的文章,NYT指責ChatGPT傳播誤導的事實。
主要是因為,如果給定的先前句子集在訓練數(shù)據(jù)中只出現(xiàn)一次,則預測的后驗文本將不會與訓練數(shù)據(jù)匹配。它會「幻覺」出類似合理的文本。
幻覺之所以會發(fā)生,是因為大模型根本不了解事實,而只知道下一個詞的分布。
這是一件大事,因為它可能為兩個方面建立先例:1. 法院怎樣確定新聞內容在訓練大語言模型時的價值;2. 對于之前的使用情況,應當支付多少賠償。
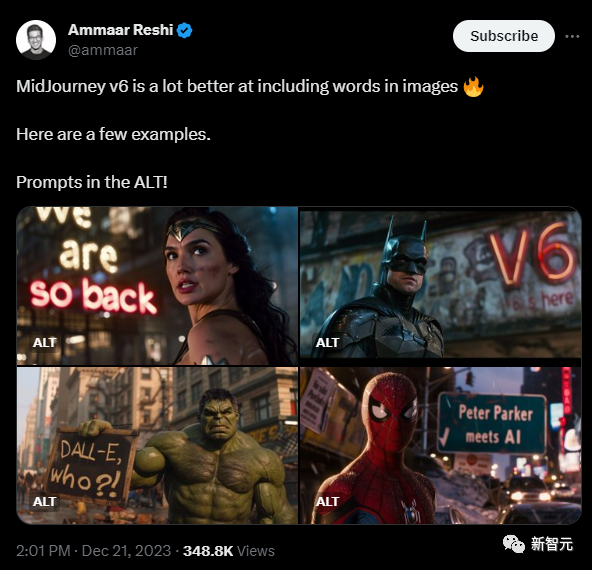
Midjourney吐出「原圖」?
不僅僅是OpenAI、微軟,就連最強的AI作圖神器Midjourney也將在未來面臨一大波的起訴。
Midjourney V6升級后驚艷了全網,但同時有人發(fā)現(xiàn),其輸出的圖片完全和好萊塢等電影劇照毫無差別。
曾為漫威工作的插畫家兼電影概念藝術家Reid Southen表示,只需要15分鐘,就能找到Midjourney侵犯版權和剽竊的證據(jù)。
如下的圖片中,可以看出生成的圖像與電影原作非常接近,僅在鏡頭角度或姿勢等方面存在細微差別。

他還制作了一段視頻,展示了自己使用Midjourney V6進行的剽竊實驗。

因為他發(fā)表的評論,Southen已經被踢出了Midjourney Discord小組。
據(jù)Southen表示,AI軟件可以完全復制受版權保護的知識產權,并且可以創(chuàng)作無限的衍生品。
藝術家將在同一市場上與自己的作品競爭。當網上50%的漫威作品最終都是人工智能的山寨品時,品牌形象問題和消費者的困惑又將如何解決?
《蒙娜麗莎》這樣的經典藝術品,只提供兩個字的提示,就能完全復刻原圖。
而且在這種情況下,這種行為并不會在法律上被判為“剽竊”,因為《蒙娜麗莎》的年代久遠,已經屬于公有版權。

2019年由托德·菲利普斯執(zhí)導的電影「小丑」中的畫面,也被Midjourney V6「拿來即用」。

這兩張圖如此相似,不得不讓人懷疑,這似乎就是在訓練數(shù)據(jù)中微調之后的版本。
而它們的不同之處,在于燈光和色彩。

矩陣中的基努,也和原片幾乎一毛一樣。

Midjourney V6甚至可以復制任何動畫風格。

小黃人、瑞克和莫迪、巴斯光年等等,完全逼真全現(xiàn)。

為了最大限度地提高性能,新模型可能會在相同的數(shù)據(jù)上反復強化訓練,導致輸出結果與訓練數(shù)據(jù)幾乎完全相同。
這就是所謂的「過擬合」,此前研究表明這種情況可能會發(fā)生。ChatGPT也會出現(xiàn)文本過擬合的跡象。
全新的V6模型很可能是一枚重磅炸彈。目前,Midjourney已經卷入了至少一起訴訟。
以后網上這些畫面究竟是原動畫還是AI生成,恐怕沒人能分得清了。

Prompt: scene from the simpsons [character] --ar 16:9 --style raw --v 6

Prompt: scene from finding nemo [character] --ar 16:9 --style raw --v 6

Prompt: scene from dragonball [character] --ar 16:9 --style raw --v 6

Prompt: scene from rick and morty --ar 16:9 --style raw --v 6

Prompt: scene from frozen --ar 16:9 --style raw --v 6