突破Pytorch核心點,優化器 !!
嗨,我是小壯!
今兒咱們聊聊Pytorch中的優化器。
優化器在深度學習中的選擇直接影響模型的訓練效果和速度。不同的優化器適用于不同的問題,其性能的差異可能導致模型更快、更穩定地收斂,或者在某些任務上表現更好。
因此,選擇合適的優化器是深度學習模型調優中的一個關鍵決策,能夠顯著影響模型的性能和訓練效率。
PyTorch本身提供了許多優化器,用于訓練神經網絡時更新模型的權重。

常見優化器
咱們先列舉PyTorch中常用的優化器,以及簡單介紹:
(1) SGD (Stochastic Gradient Descent)
隨機梯度下降是最基本的優化算法之一。它通過計算損失函數關于權重的梯度,并沿著梯度的負方向更新權重。
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)(2) Adam
Adam是一種自適應學習率的優化算法,結合了AdaGrad和RMSProp的思想。它能夠自適應地為每個參數計算不同的學習率。
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)(3) Adagrad
Adagrad是一種自適應學習率的優化算法,根據參數的歷史梯度調整學習率。但由于學習率逐漸減小,可能導致訓練過早停止。
optimizer = torch.optim.Adagrad(model.parameters(), lr=learning_rate)(4) RMSProp
RMSProp也是一種自適應學習率的算法,通過考慮梯度的滑動平均來調整學習率。
optimizer = torch.optim.RMSprop(model.parameters(), lr=learning_rate)(5) Adadelta
Adadelta是一種自適應學習率的優化算法,是RMSProp的改進版本,通過考慮梯度的移動平均和參數的移動平均來動態調整學習率。
optimizer = torch.optim.Adadelta(model.parameters(), lr=learning_rate)一個完整案例
在這里,咱們聊聊如何使用PyTorch訓練一個簡單的卷積神經網絡(CNN)來進行手寫數字識別。
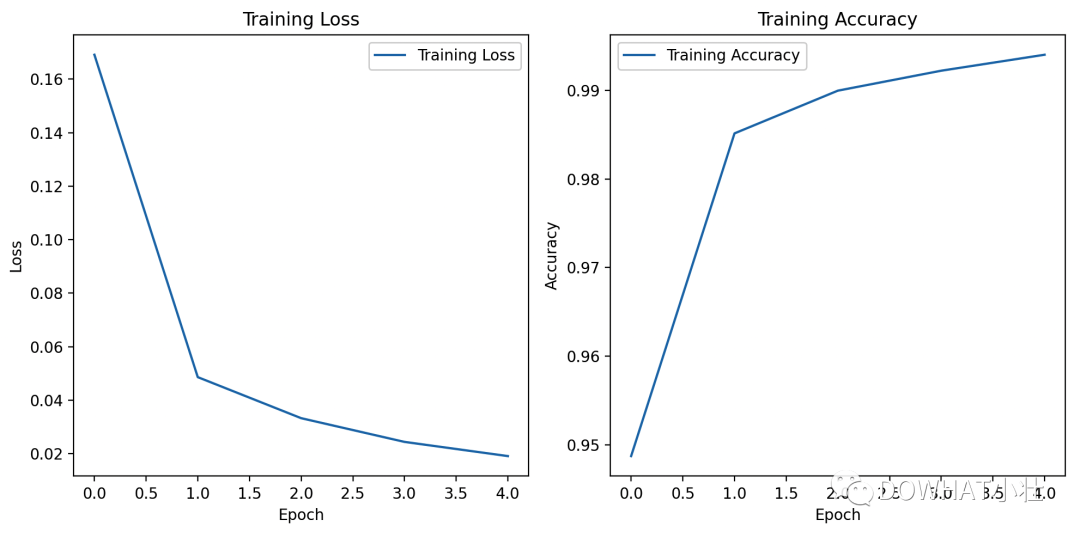
這個案例使用的是MNIST數據集,并使用Matplotlib庫繪制了損失曲線和準確率曲線。
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
# 設置隨機種子
torch.manual_seed(42)
# 定義數據轉換
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])
# 下載和加載MNIST數據集
train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
test_dataset = datasets.MNIST(root='./data', train=False, download=True, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=1000, shuffle=False)
# 定義簡單的卷積神經網絡模型
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Conv2d(1, 32, kernel_size=3, stride=1, padding=1)
self.relu = nn.ReLU()
self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1)
self.fc1 = nn.Linear(64 * 7 * 7, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.conv1(x)
x = self.relu(x)
x = self.pool(x)
x = self.conv2(x)
x = self.relu(x)
x = self.pool(x)
x = x.view(-1, 64 * 7 * 7)
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
return x
# 創建模型、損失函數和優化器
model = CNN()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 訓練模型
num_epochs = 5
train_losses = []
train_accuracies = []
for epoch in range(num_epochs):
model.train()
total_loss = 0.0
correct = 0
total = 0
for inputs, labels in train_loader:
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
total_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
accuracy = correct / total
train_losses.append(total_loss / len(train_loader))
train_accuracies.append(accuracy)
print(f"Epoch {epoch+1}/{num_epochs}, Loss: {train_losses[-1]:.4f}, Accuracy: {accuracy:.4f}")
# 繪制損失曲線和準確率曲線
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
plt.plot(train_losses, label='Training Loss')
plt.title('Training Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(train_accuracies, label='Training Accuracy')
plt.title('Training Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
plt.tight_layout()
plt.show()
# 在測試集上評估模型
model.eval()
correct = 0
total = 0
with torch.no_grad():
for inputs, labels in test_loader:
outputs = model(inputs)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
accuracy = correct / total
print(f"Accuracy on test set: {accuracy * 100:.2f}%")上述代碼中,我們定義了一個簡單的卷積神經網絡(CNN),使用交叉熵損失和Adam優化器進行訓練。
在訓練過程中,我們記錄了每個epoch的損失和準確率,并使用Matplotlib庫繪制了損失曲線和準確率曲線。
我是小壯,下期見!