ICASSP 2024|字節跳動流媒體音頻團隊創新方案解決丟包補償、通用音質修復問題
在本屆ICASSP 2024 各類音頻國際挑戰賽中,字節跳動流媒體音頻團隊聯合西北工業大學音頻語音與語言處理研究實驗室,在丟包補償(Packet Loss Concealment, PLC)與音質修復(Speech Signal Improvement, SSI)兩個挑戰賽道中,多項指標上表現優秀,分別取得第一和第二的成績,達到國際領先水平。
ICASSP峰會上的音頻挑戰賽由國際音頻頂級會議 ICASSP 和微軟聯合發起,旨在激發各研究構在音頻效果與音質提升上的研究,自第一屆舉辦以來就吸引了亞馬遜、騰訊、阿里巴巴、百度、快手、中科院、西工大等全球諸多知名企業和科研院所的參與。隨著流媒體領域技術的不斷發展,讓聲音聽的清,聽和真,變成音頻技術行業發展必然趨勢。圍繞著如何讓用戶有更優的音頻體驗,多個研究團隊對音頻從采集到轉發進行端到端的優化,這一過程包含了如何對音頻采集缺陷,算法處理缺陷,編解碼缺陷,網絡傳輸缺陷等進行一體化修復。本屆挑戰賽中,字節跳動流媒體音頻團隊結合真實的業務落地場景,參加了丟包補償與通用音質修復這兩個挑戰賽道。
ICASSP PLC 挑戰賽旨在解決網絡IP通話中長間隔數據包丟失和全帶音頻(48k Hz采樣率)處理的問題。該挑戰具有嚴格的時延限制,同時提供了苛刻的數據集來反映不利的網絡條件。主觀評估將使用P.804多維音頻質量評估方法進行,同時WER也被用于評估參賽系統生成語音的可懂度。流媒體音頻技術團隊通過對模型結構進行優化,有效降低了丟包補償模型的復雜度。同時,通過多判別器對抗訓練與多任務學習,使丟包補償模型可以以高質量、高可懂度恢復丟包片段,最終取得第一的成績。
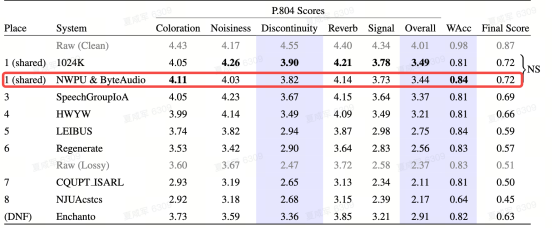
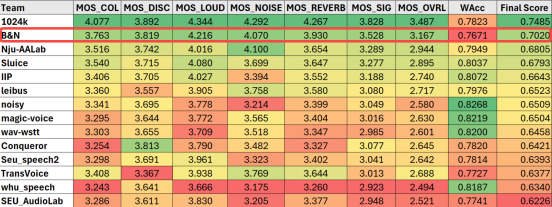
ICASSP SSI 挑戰賽旨在解決通信系統中語音信號面臨的頻率響應失真、不連續失真、響度失真、噪聲和混響這五類問題。該挑戰賽在嚴格設置模型時延以及因果性的前提下,使用ITU-TP.804標準下的主觀意見分和語音識別率綜合評判名次。流媒體技術團隊使用兩階段模型結構將復雜的修復問題簡化為多個子任務,在第一階段主要修復頻率響應失真、不連續失真以及響度失真,并進行初步降噪與去混響;在第二階段進一步去除第一階段生成的偽影以及殘余噪聲。最終,團隊在實時賽道取得第二名的成績。
丟包補償系統
為解決48kHz全帶音頻處理復雜度的問題,在丟包補償系統中使用了頻域模型,并根據頻率將音頻分為0-8kHz,8-24kHz兩個子帶并行處理。將主要計算量集中在對聽感影響更大的0-8kHz頻段,實現了低復雜度、高質量的丟包補償。為了應對長間隔丟包問題,在編解碼器每層后添加了時頻擴張卷積模塊(TFDCM),在保持小尺寸卷積核同時通過時間和頻率維度逐層膨脹的因果擴張卷積捕獲長時歷史信息與頻率相關性。
為了更高質量的補償音頻,結合使用頻域多分辨率判別器、時域多周期判別器與MetricGAN,進行生成對抗訓練,使得生成音頻聽感優秀。對于長間隔丟包以及可懂度的問題,采用多任務學習框架。除了通常的語音信號相似度學習,還引入了基頻預測與基于whisper的語義理解損失函數。模型最長能夠以高質量恢復超過100ms的丟包片段,且恢復音頻可懂度較高,詞正確率(WAcc)指標領先所有參賽隊伍,總體評估得分并列第一。

丟包補償模型結構示意圖
音質修復系統
為了修復同時受多種失真影響的音頻,構建系統中使用了兩階段模型架構,在不同階段著重對不同失真進行處理。一階段模型使用映射(Mapping)的方式直接預測修復后音頻的復數譜,從而使模型同時具備生成音頻缺失成分與消除干擾信號的能力,同時為了提升模型的長時捕獲信息的能力,在編碼器和解碼器中引入了時頻卷積模塊(Time-Frequency Convlution Module,TFCM);由于映射法的不穩定性,可能產生偽影,因此引入使用掩蔽(Mask)方式的二階段模型,并采用子帶-全帶建模的方式對頻帶進行細粒度建模,從而進一步消除一階段模型生成的偽影與殘余噪聲。
為了提升生成的音頻成分的自然度,引入生成式對抗網絡框架,使用多分辨率判別器、分子帶多分辨率判別器輔助模型進行訓練。同時為了多階段模型在訓練時更容易收斂,首先在降噪和去混響任務上對二階段模型進行預訓練,然后凍結已訓練完成的一階段模型的參數,并將其與預訓練的二階段模型級聯進行聯合訓練,從而加快模型收斂。
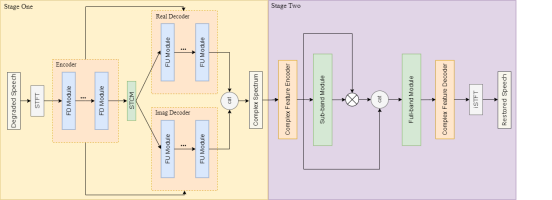
音質修復模型結構示意圖
團隊介紹
字節跳動流媒體音頻團隊,致力于提供全球互聯網范圍內高質量、低延時的實時音視頻通信能力,幫助開發者快速構建語音通話、視頻通話、互動直播、轉推直播等豐富場景功能,目前已覆蓋互娛、教育、會議、游戲、汽車、金融、IoT 等實時音視頻互動場景,服務數億用戶。