告別逐一標(biāo)注,一個提示實(shí)現(xiàn)批量圖片分割,高效又準(zhǔn)確
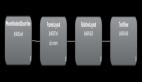
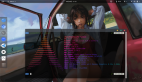
Segment Anything Model (SAM) 的提出在圖像分割領(lǐng)域引起了巨大的關(guān)注,其卓越的泛化性能引發(fā)了廣泛的興趣。然而,盡管如此,SAM 仍然面臨一個無法回避的問題:為了使 SAM 能夠準(zhǔn)確地分割出目標(biāo)物體的位置,每張圖片都需要手動提供一個獨(dú)特的視覺提示。如下圖所示,即使點(diǎn)擊的是同一物體(圖 (b)-(d)),微小位置變化都會導(dǎo)致分割結(jié)果的顯著差異。這是因?yàn)橐曈X提示缺乏語義信息,即使提示在想要分割的目標(biāo)物體上,仍然可能引發(fā)歧義。框提示和涂鴉提示(圖 (e)(f))雖然提供了更具體的位置信息,但由于機(jī)器和人類對目標(biāo)分割物的理解存在偏差,效果常常與期望有所出入。

目前的一些方法,如 SEEM 和 AV-SAM,通過提供更多模態(tài)的輸入信息來引導(dǎo)模型更好地理解要分割的物體是什么。然而,盡管輸入信息變得更加具體和多樣化,但在實(shí)際場景中,每個無標(biāo)注樣本仍然需要一個獨(dú)特的提示來作為指導(dǎo),這是一種不切實(shí)際的需求。理想情況下,作者希望告知機(jī)器當(dāng)前的無標(biāo)注數(shù)據(jù)都是采集自于什么任務(wù),然后期望機(jī)器能夠批量地按照作者的要求對這些同一任務(wù)下的樣本進(jìn)行分割。然而,當(dāng)前的 SAM 模型及其變體受到必須為每幅圖手動提供提示這一要求的限制,因此很難實(shí)現(xiàn)這一點(diǎn)。

來自倫敦大學(xué)瑪麗女王學(xué)院的研究者們提出了一種無需訓(xùn)練的分割方法 GenSAM ,能夠在只提供一個任務(wù)通用的文本提示的條件下,將任務(wù)下的所有無標(biāo)注樣本進(jìn)行有效地分割。

- 論文鏈接:https://arxiv.org/pdf/2312.07374.pdf
- 項(xiàng)目鏈接:https://lwpyh.github.io/GenSAM/
- 代碼鏈接:https://github.com/jyLin8100/GenSAM/
問題設(shè)置
對于給定的分割任務(wù),例如偽裝樣本分割,對于該任務(wù)下來自各個數(shù)據(jù)集的所有無標(biāo)注樣本,只提供一個任務(wù)描述:“the camouflaged animal” 作為這些圖片的唯一提示  。對于該任務(wù)下的任意一張圖像
。對于該任務(wù)下的任意一張圖像  ,需要利用
,需要利用  來有針對性地完成與任務(wù)相關(guān)的目標(biāo)的分割。在這種情況下,目標(biāo)是根據(jù)任務(wù)描述準(zhǔn)確地分割圖像中偽裝的動物。模型需要理解并利用提供的任務(wù)描述來執(zhí)行分割,而不依賴于手動提供每個圖像的特定提示。
來有針對性地完成與任務(wù)相關(guān)的目標(biāo)的分割。在這種情況下,目標(biāo)是根據(jù)任務(wù)描述準(zhǔn)確地分割圖像中偽裝的動物。模型需要理解并利用提供的任務(wù)描述來執(zhí)行分割,而不依賴于手動提供每個圖像的特定提示。
這種方法的優(yōu)勢在于,通過提供通用任務(wù)描述,可以批量地處理所有相關(guān)任務(wù)的無標(biāo)注圖片,而無需為每個圖片手動提供具體的提示。這對于涉及大量數(shù)據(jù)的實(shí)際場景來說是一種更加高效和可擴(kuò)展的方法。
GenSAM 的流程圖如下所示:

方法介紹
為了解決這一問題,作者提出了 Generalizable SAM(GenSAM)模型,旨在擺脫像 SAM 這類提示分割方法對樣本特定提示的依賴。具體而言,作者提出了一個跨模態(tài)思維鏈(Cross-modal Chains of Thought Prompting,CCTP)的概念,將一個任務(wù)通用的文本提示映射到該任務(wù)下的所有圖片上,生成個性化的感興趣物體和其背景的共識熱力圖,從而獲得可靠的視覺提示來引導(dǎo)分割。此外,為了實(shí)現(xiàn)測試時自適應(yīng),作者進(jìn)一步提出了一個漸進(jìn)掩膜生成(Progressive Mask Generation,PMG)框架,通過迭代地將生成的熱力圖重新加權(quán)到原圖上,引導(dǎo)模型對可能的目標(biāo)區(qū)域進(jìn)行從粗到細(xì)的聚焦。值得注意的是,GenSAM 無需訓(xùn)練,所有的優(yōu)化都是在實(shí)時推理時實(shí)現(xiàn)的。
跨模態(tài)思維鏈
Cross-modal Chains of Thought Prompting (CCTP)
隨著大規(guī)模數(shù)據(jù)上訓(xùn)練的 Vision Language Model (VLM) 的發(fā)展,如 BLIP2 和 LLaVA 等模型具備了強(qiáng)大的推理能力。然而,在面對復(fù)雜場景,如偽裝樣本分割時,這些模型很難準(zhǔn)確推理出復(fù)雜背景下任務(wù)相關(guān)物體的身份,而且微小提示變化可能導(dǎo)致結(jié)果顯著差異。同時,目前的 VLM 只能推理出可能的目標(biāo)描述,而不能將其定位到圖像中。為了解決這一問題,作者以現(xiàn)有任務(wù)描述  為基礎(chǔ)構(gòu)建了多個思維鏈,希望通過從多個角度獲得共識來推理第 j 個鏈上前景物體的關(guān)鍵詞
為基礎(chǔ)構(gòu)建了多個思維鏈,希望通過從多個角度獲得共識來推理第 j 個鏈上前景物體的關(guān)鍵詞  和背景的關(guān)鍵詞
和背景的關(guān)鍵詞  。
。
然而,當(dāng)前大多數(shù)求取共識的方法基于一個假設(shè):VLM 的輸出結(jié)果是有限的,可以通過多數(shù)表決來確定正確答案。在作者的場景中,鏈路數(shù)量是有限的,而輸出結(jié)果是無法預(yù)測的。過去的多數(shù)表決方法在這里難以應(yīng)用。此外,VLM 只能推理出可能目標(biāo)的關(guān)鍵詞,而不能將其準(zhǔn)確定位于圖像中。
為了克服這一問題,受到 CLIP Surgery 的啟發(fā),作者提出了一個 spatial CLIP 模塊,在傳統(tǒng)的 CLIP Transformer 基礎(chǔ)上添加了一個由 K-K-V 自注意力機(jī)制構(gòu)成的 Transformer 結(jié)構(gòu),將 VLM 在不同鏈路上推理得到的不可預(yù)測的關(guān)鍵詞映射到同一張熱力圖上。這樣,無法在語言層面求取共識的問題可以在視覺層面上得到解決。具體而言,作者通過 Spatial CLIP 的共識特征  和
和  分別獲取不同鏈路上的前景和背景關(guān)鍵詞。由于復(fù)雜場景中背景物體可能對結(jié)果產(chǎn)生干擾,作者通過用
分別獲取不同鏈路上的前景和背景關(guān)鍵詞。由于復(fù)雜場景中背景物體可能對結(jié)果產(chǎn)生干擾,作者通過用  減去
減去  來排除這種干擾,得到最終的相似度熱力圖
來排除這種干擾,得到最終的相似度熱力圖  。$SI$ 通過上采樣到原有圖片的大小,即獲得了定位任務(wù)相關(guān)目標(biāo)位置的熱力圖 H 。其中,具有很高和很低置信度的點(diǎn)分別被視為正和負(fù)提示點(diǎn),它們被篩選出來用于引導(dǎo) SAM 進(jìn)行分割。
。$SI$ 通過上采樣到原有圖片的大小,即獲得了定位任務(wù)相關(guān)目標(biāo)位置的熱力圖 H 。其中,具有很高和很低置信度的點(diǎn)分別被視為正和負(fù)提示點(diǎn),它們被篩選出來用于引導(dǎo) SAM 進(jìn)行分割。
漸進(jìn)掩膜生成
Progressive Mask Generation (PMG)
然而,單一的推斷可能無法提供令人滿意的分割結(jié)果。對于具有復(fù)雜背景的圖像,熱圖中某些背景對象可能也會在很大程度上被激活,導(dǎo)致在推斷點(diǎn)提示時出現(xiàn)一些噪聲。為了獲得更強(qiáng)大的提示,作者使用熱圖作為視覺提示,對原始圖像進(jìn)行重新加權(quán),并在測試時引導(dǎo)模型進(jìn)行適應(yīng)。加權(quán)圖像  可以通過下面的公式獲得:
可以通過下面的公式獲得:

這里 X 是輸入圖片,$w_{pic}$ 是權(quán)重,$H$ 是熱力圖。此外,在隨后的迭代中,作者使用前一次迭代的掩碼通過繪制邊界框來引導(dǎo)分割,作為后處理步驟。作者選擇與掩碼具有最高 IoU(交并比)值的框作為作者的選擇。這優(yōu)化了當(dāng)前迭代并提高了分割結(jié)果的一致性。第 i 次迭代獲得的掩碼被定義為  ,其中 i ∈ 1,...,Iter。Iter 被設(shè)定為 6。為了消除由每次迭代中不一致提示引起的歧義的影響,每次迭代中獲得的掩碼被平均。最后,通過選擇在所有迭代中最接近平均掩碼的迭代結(jié)果來確定所選迭代
,其中 i ∈ 1,...,Iter。Iter 被設(shè)定為 6。為了消除由每次迭代中不一致提示引起的歧義的影響,每次迭代中獲得的掩碼被平均。最后,通過選擇在所有迭代中最接近平均掩碼的迭代結(jié)果來確定所選迭代  :
:

 就是 X 的最終分割結(jié)果。
就是 X 的最終分割結(jié)果。
實(shí)驗(yàn)

作者在偽裝樣本分割任務(wù)上的三個不同數(shù)據(jù)集上進(jìn)行了實(shí)驗(yàn),并分別與點(diǎn)監(jiān)督和涂鴉 (scribble) 監(jiān)督下進(jìn)行訓(xùn)練后的方法進(jìn)行了比較。GenSAM 不僅比基線方法相比取得了長足的進(jìn)步,還再更好的監(jiān)督信號和完全沒有訓(xùn)練的情況下,取得了比弱監(jiān)督方法類似甚至更好的性能。
作者還進(jìn)一步進(jìn)行了可視化實(shí)驗(yàn),分析不同 iter 下的分割結(jié)果,首先是在 SAM 處理不佳的偽裝樣本分割任務(wù)上進(jìn)行了評估:

此外,為了驗(yàn)證 GenSAM 的泛化性,還在陰影分割和透明物體分割上進(jìn)行了可視化實(shí)驗(yàn),均取得了出色的性能。

總結(jié)
總的來說,GenSAM 的提出使得像 SAM 這類提示分割方法能夠擺脫對樣本特定提示的依賴,這一能力為 SAM 的實(shí)際應(yīng)用邁出了重要的一步。