













作者 | 崔皓
審校 | 重樓
開(kāi)篇
在AIGC(人工智能與通用計(jì)算)應(yīng)用中,大型語(yǔ)言模型(LLM)占據(jù)著舉足輕重的地位。這些模型,如GPT和BERT系列,通過(guò)處理和分析龐大的數(shù)據(jù)集,已經(jīng)極大地推動(dòng)了自然語(yǔ)言理解和生成的邊界。它們?cè)诙喾N應(yīng)用中表現(xiàn)出色,如文本生成、語(yǔ)言翻譯、情感分析等,對(duì)提高工作效率和展開(kāi)創(chuàng)新的應(yīng)用場(chǎng)景起著關(guān)鍵作用。

然而,LLM在處理實(shí)時(shí)數(shù)據(jù)方面存在一定的局限性。這些模型主要基于大量歷史數(shù)據(jù)進(jìn)行訓(xùn)練,因此,在理解和分析實(shí)時(shí)或最新信息時(shí)可能不夠靈敏。在應(yīng)對(duì)新興話(huà)題或最新發(fā)展趨勢(shì)時(shí),LLM可能無(wú)法提供最準(zhǔn)確的信息,因?yàn)檫@些內(nèi)容可能尚未包含在其訓(xùn)練數(shù)據(jù)中。此外,LLM在快速處理和反應(yīng)實(shí)時(shí)變化方面也面臨挑戰(zhàn),尤其是在需要分析和反映最新市場(chǎng)動(dòng)態(tài)、政策變化或社會(huì)事件時(shí)。
既然我們已經(jīng)意識(shí)到了大型語(yǔ)言模型(LLM)在處理實(shí)時(shí)數(shù)據(jù)方面的局限性,那么下一步就是探索如何通過(guò)Web Research技術(shù)突破這一限制。下面的內(nèi)容將專(zhuān)注于如何通過(guò)網(wǎng)絡(luò)爬蟲(chóng)技術(shù)結(jié)合LLM,實(shí)現(xiàn)對(duì)實(shí)時(shí)網(wǎng)絡(luò)資源的有效獲取和分析。
整體思路
Web Research 結(jié)合 LLM 的整體思路是復(fù)雜的過(guò)程,旨在利用大型語(yǔ)言模型的自然語(yǔ)言處理能力,實(shí)現(xiàn)對(duì)互聯(lián)網(wǎng)數(shù)據(jù)的高效處理和分析。如下圖所示,我們將整個(gè)過(guò)程進(jìn)行拆解:
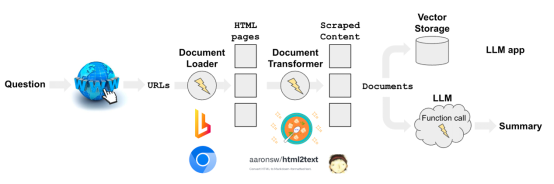
1. 實(shí)時(shí)網(wǎng)絡(luò)請(qǐng)求:首先,對(duì)目標(biāo)網(wǎng)站發(fā)起實(shí)時(shí)請(qǐng)求,以獲取最新的數(shù)據(jù)和內(nèi)容。
2. 獲取HTML頁(yè)面:使用網(wǎng)站的URLs來(lái)訪(fǎng)問(wèn)和加載HTML頁(yè)面,此時(shí),網(wǎng)頁(yè)的數(shù)據(jù)將被加載到內(nèi)存中。
3. 內(nèi)容轉(zhuǎn)換:隨后,將加載的HTML頁(yè)面轉(zhuǎn)換為文本信息,為后續(xù)的處理步驟做準(zhǔn)備。這通常涉及去除HTML標(biāo)記和格式化內(nèi)容,以提取純文本數(shù)據(jù)。
4. 數(shù)據(jù)存儲(chǔ)和分類(lèi):轉(zhuǎn)換后的文本數(shù)據(jù)可以存儲(chǔ)在向量庫(kù)中,以便于進(jìn)行高效的檢索和分析。同時(shí),可以利用LLM對(duì)內(nèi)容進(jìn)行分類(lèi)和組織,以便快速訪(fǎng)問(wèn)相關(guān)信息。
5.生成摘要:最后,利用LLM的功能調(diào)用來(lái)生成文本數(shù)據(jù)的摘要。這不僅包括提取關(guān)鍵信息,還可能涉及對(duì)數(shù)據(jù)進(jìn)行綜合和解釋?zhuān)员阌脩?hù)能夠快速理解內(nèi)容的核心要點(diǎn)。
通過(guò)這樣的流程,我們能夠結(jié)合LLM的強(qiáng)大文本處理功能和網(wǎng)絡(luò)爬蟲(chóng)技術(shù)的實(shí)時(shí)數(shù)據(jù)訪(fǎng)問(wèn)能力,有效地處理和分析大量的在線(xiàn)信息。這種方法不僅提高了信息處理的速度和準(zhǔn)確性,而且通過(guò)摘要和分類(lèi),使得用戶(hù)能夠更容易地獲取和理解需要的數(shù)據(jù)。
關(guān)鍵問(wèn)題
為了驗(yàn)證Web爬蟲(chóng)和大型語(yǔ)言模型結(jié)合的研究思路是否切實(shí)可行,可以以知名新聞網(wǎng)站W(wǎng)all Street Journal(華爾街日?qǐng)?bào))為例進(jìn)行實(shí)證分析。假設(shè)從該網(wǎng)站的首頁(yè),獲取實(shí)時(shí)的新聞信息,并且將這些信息進(jìn)行抽取,最終保存為包括“標(biāo)題”和“摘要”的結(jié)構(gòu)化信息, 以便后續(xù)查找和分析。從過(guò)程描述中發(fā)現(xiàn),將面臨三個(gè)主要的技術(shù)挑戰(zhàn):加載、轉(zhuǎn)換以及通過(guò)LLM進(jìn)行內(nèi)容抽取。
1.加載HTML:我們可以訪(fǎng)問(wèn) https://www.wsj.com,使用網(wǎng)絡(luò)爬蟲(chóng)工具獲取網(wǎng)站的HTML內(nèi)容。這一步涉及發(fā)送HTTP請(qǐng)求并接收返回的網(wǎng)頁(yè)代碼。
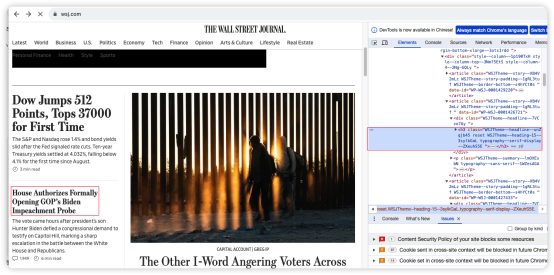
2. 轉(zhuǎn)換為文本:分析該網(wǎng)站的HTML結(jié)構(gòu)表明,文章標(biāo)題和摘要信息通常包含在`<span>`標(biāo)簽中。如下圖所示,文章的標(biāo)題是在`<span>`標(biāo)簽中。
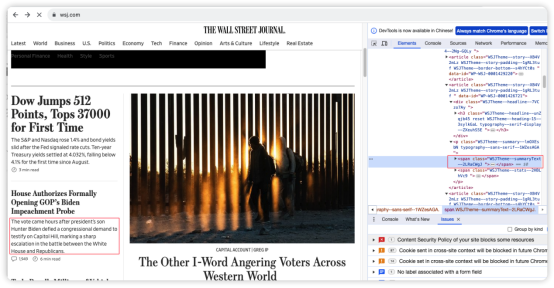
如下圖所示,我們觀察到,文章的摘要也是保存在<span>標(biāo)簽中。
因此需要利用HTML解析庫(kù),如BeautifulSoup,從HTML中提取這些標(biāo)簽的內(nèi)容,并將其轉(zhuǎn)換為純文本格式。
3. LLM處理:有了純文本數(shù)據(jù)后,我們將使用大型語(yǔ)言模型來(lái)進(jìn)一步處理這些文本。這可能包括內(nèi)容分類(lèi)、關(guān)鍵信息提取、摘要生成等。
在這個(gè)例證中,我們將如何確保網(wǎng)絡(luò)爬蟲(chóng)精準(zhǔn)地抓取所需信息,以及如何調(diào)整大型語(yǔ)言模型以精確處理和提取有價(jià)值的內(nèi)容,都是需要解決的問(wèn)題。通過(guò)成功實(shí)施這一流程,我們不僅驗(yàn)證了LLM與Web爬蟲(chóng)結(jié)合的有效性,還進(jìn)一步探索了如何通過(guò)自動(dòng)化工具提高研究和分析的效率。
數(shù)據(jù)加載
通過(guò)上面對(duì)關(guān)鍵問(wèn)題的分析,讓我們先為即將進(jìn)行的技術(shù)旅程做好準(zhǔn)備。從網(wǎng)頁(yè)內(nèi)容的加載到信息的轉(zhuǎn)換,再到利用LLM提取關(guān)鍵數(shù)據(jù),都是構(gòu)建有效網(wǎng)絡(luò)研究工具的關(guān)鍵環(huán)節(jié)。
首先,我們將面對(duì)的挑戰(zhàn)是如何高效地加載網(wǎng)頁(yè)內(nèi)容。異步HTML加載器(AsyncHtmlLoader)扮演著至關(guān)重要的角色。使用aiohttp庫(kù)構(gòu)建的AsyncHtmlLoader能夠進(jìn)行異步HTTP請(qǐng)求,非常適合于簡(jiǎn)單輕量級(jí)的網(wǎng)頁(yè)抓取工作。這意味著它能夠同時(shí)處理多個(gè)URL的請(qǐng)求,提高了數(shù)據(jù)抓取的效率,特別是當(dāng)我們需要從多個(gè)網(wǎng)站快速獲取信息時(shí)。
對(duì)于那些更復(fù)雜的網(wǎng)站,其中的內(nèi)容可能依賴(lài)于JavaScript渲染,我們可能需要更強(qiáng)大的工具,例如AsyncChromiumLoader。這個(gè)加載器利用Playwright來(lái)啟動(dòng)一個(gè)Chromium實(shí)例,它不僅可以處理JavaScript渲染,還可以應(yīng)對(duì)更復(fù)雜的Web交互。Playwright是一個(gè)強(qiáng)大的庫(kù),支持多種瀏覽器自動(dòng)化操作,其中Chromium就是一個(gè)被廣泛支持的瀏覽器。
Chromium可以在無(wú)頭模式下運(yùn)行,即沒(méi)有圖形用戶(hù)界面的瀏覽器,這在網(wǎng)頁(yè)抓取中很常見(jiàn)。在無(wú)頭模式下,瀏覽器后臺(tái)運(yùn)行,執(zhí)行自動(dòng)化任務(wù),而用戶(hù)不會(huì)看到任何的瀏覽器窗口。這樣的操作對(duì)于服務(wù)器端的抓取任務(wù)尤其有用,因?yàn)樗鼈兛梢阅M瀏覽器中的完整用戶(hù)交互過(guò)程,而不需要實(shí)際顯示界面。
無(wú)頭模式,或稱(chēng)為“無(wú)界面模式”,是一種在不打開(kāi)圖形界面的情況下運(yùn)行應(yīng)用程序的方式。想象一下,你的電腦在執(zhí)行一些任務(wù),如下載文件、刷新數(shù)據(jù)或運(yùn)行一個(gè)復(fù)雜的計(jì)算過(guò)程,而這一切都在沒(méi)有打開(kāi)任何窗口的情況下靜靜進(jìn)行。這正是無(wú)頭模式的工作原理。
在Web開(kāi)發(fā)和自動(dòng)化測(cè)試領(lǐng)域,無(wú)頭模式尤為有用。例如,開(kāi)發(fā)者可能需要測(cè)試一個(gè)網(wǎng)頁(yè)在不同瀏覽器中的表現(xiàn),但并不需要真正地視覺(jué)上檢查這些網(wǎng)頁(yè),而是要檢查代碼的運(yùn)行結(jié)果。在這種情況下,他們可以使用無(wú)頭模式的瀏覽器來(lái)模擬用戶(hù)的行為,如點(diǎn)擊鏈接、填寫(xiě)表單等,同時(shí)瀏覽器本身不會(huì)在屏幕上顯示。
實(shí)際上,我們介紹了AsyncHtmlLoader和AsyncChromiumLoader兩種加載器,本例中我們使用前者就足夠了,其示例代碼如下:
from langchain.document_loaders import AsyncHtmlLoader
urls = ["https://www.wsj.com"]
loader = AsyncHtmlLoader(urls)
docs = loader.load()代碼創(chuàng)建一個(gè)加載器實(shí)例并傳入需要抓取的URL列表。隨后,調(diào)用`load`方法就會(huì)異步加載這些頁(yè)面的內(nèi)容。
文本轉(zhuǎn)換
解決了數(shù)據(jù)加載的問(wèn)題,讓我們把目光轉(zhuǎn)向文本轉(zhuǎn)換。文本轉(zhuǎn)換是網(wǎng)絡(luò)爬蟲(chóng)技術(shù)中的一個(gè)重要環(huán)節(jié),它負(fù)責(zé)將抓取的HTML內(nèi)容轉(zhuǎn)換成便于處理的純文本格式。在這一階段,我們可以選用不同的工具,根據(jù)不同的需求來(lái)實(shí)現(xiàn)這一轉(zhuǎn)換。
首先是HTML2Text,這是一個(gè)直接將HTML內(nèi)容轉(zhuǎn)換為純文本的工具,生成的格式類(lèi)似于Markdown。這種轉(zhuǎn)換方法適合于那些目標(biāo)是提取可讀文本而不需要操作特定HTML標(biāo)簽的場(chǎng)景。它簡(jiǎn)化了轉(zhuǎn)換流程,能夠迅速提供一個(gè)干凈的文本版本,適合閱讀和進(jìn)一步分析。
而B(niǎo)eautiful Soup則提供了更細(xì)粒度的控制能力。使用Beautiful Soup,我們可以執(zhí)行特定標(biāo)簽的提取、刪除和內(nèi)容清理,這對(duì)于需要從HTML內(nèi)容中提取特定信息的場(chǎng)景來(lái)說(shuō)非常適合。例如,如果我們需要從一個(gè)新聞網(wǎng)站中提取文章標(biāo)題和摘要,而這些內(nèi)容是通過(guò)`<span>`標(biāo)簽來(lái)標(biāo)識(shí)的,Beautiful Soup就可以精確地定位這些標(biāo)簽并提取它們的內(nèi)容。
在實(shí)際操作中,我們可以先使用AsyncHtmlLoader來(lái)加載目標(biāo)網(wǎng)站的文檔。接著,我們可以使用Html2TextTransformer來(lái)對(duì)加載的HTML文檔進(jìn)行轉(zhuǎn)換。如下代碼所示:
from langchain.document_loaders import AsyncHtmlLoader
from langchain.document_transformers import Html2TextTransformer
urls = ["https://www.wsj.com"]
loader = AsyncHtmlLoader(urls)
docs = loader.load()
html2text = Html2TextTransformer()
docs_transformed = html2text.transform_documents(docs)以上代碼演示了如何將加載的HTML文檔轉(zhuǎn)換為文本。這樣,我們就可以得到一個(gè)文本版本的文檔,其中包含了從原始HTML中提取出來(lái)的文本內(nèi)容。
信息抽取
當(dāng)我們準(zhǔn)備好了數(shù)據(jù)之后,接下來(lái)的重要步驟是數(shù)據(jù)的抽取,這是大型語(yǔ)言模型(LLM)發(fā)揮作用的時(shí)刻。網(wǎng)絡(luò)爬蟲(chóng)面臨的挑戰(zhàn)之一是現(xiàn)代網(wǎng)站布局和內(nèi)容不斷變化,這要求我們不停地修改爬蟲(chóng)腳本以適應(yīng)這些變化。通過(guò)結(jié)合OpenAI的功能調(diào)用(Function)和抽取鏈(Extraction Chain),我們可以避免在網(wǎng)站更新時(shí)不斷更改代碼。
為了確保我們能夠使用OpenAI Functions特性,我們選擇使用`gpt-3.5-turbo-0613`模型。同時(shí),為了降低LLM的隨機(jī)性,我們將溫度參數(shù)(temperature)設(shè)置為0。
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI(temperature=0, model="gpt-3.5-turbo-0613")接下來(lái),我們定義一個(gè)數(shù)據(jù)抽取模式(Schema),以指定我們想要抽取的數(shù)據(jù)類(lèi)型。在這里,關(guān)鍵字的命名非常重要,因?yàn)樗鼈兏嬖VLLM我們想要的信息類(lèi)型。所以,描述時(shí)要盡可能詳細(xì)。
例如,在本例中,我們想要從華爾街日?qǐng)?bào)網(wǎng)站抽取新聞文章的標(biāo)題和摘要。
from langchain.chains import create_extraction_chain
schema = {
"properties": {
"news_article_title": {"type": "string"},
"news_article_summary": {"type": "string"},
},
"required": ["news_article_title", "news_article_summary"],
}然后,我們可以定義一個(gè)抽取函數(shù),它使用定義的模式和LLM來(lái)運(yùn)行內(nèi)容抽取。
def extract(content: str, schema: dict):
return create_extraction_chain(schema=schema, llm=llm).run(content)通過(guò)這種方式,LLM可以從文本中精確地抽取出我們需要的信息,并生成我們需要的結(jié)構(gòu)化數(shù)據(jù)。這種結(jié)合了LLM的抽取鏈的方法,不僅提高了數(shù)據(jù)處理的準(zhǔn)確性,也極大地簡(jiǎn)化了我們處理網(wǎng)站內(nèi)容變化的工作。
代碼實(shí)施
解決三個(gè)關(guān)鍵文字之后,我們將生成整體代碼如下,代碼展示了如何使用Playwright結(jié)合LangChain庫(kù)來(lái)實(shí)現(xiàn)一個(gè)完整的網(wǎng)絡(luò)爬蟲(chóng)和內(nèi)容抽取的工作流。
import pprint
from langchain.text_splitter import RecursiveCharacterTextSplitter
def scrape_with_playwright(urls, schema):
loader = AsyncChromiumLoader(urls)
docs = loader.load()
bs_transformer = BeautifulSoupTransformer()
docs_transformed = bs_transformer.transform_documents(
docs, tags_to_extract=["span"]
)
print("Extracting content with LLM")
# Grab the first 1000 tokens of the site
splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=1000, chunk_overlap=0
)
splits = splitter.split_documents(docs_transformed)
# Process the first split
extracted_content = extract(schema=schema, content=splits[0].page_content)
pprint.pprint(extracted_content)
return extracted_content
urls = ["https://www.wsj.com"]
extracted_content = scrape_with_playwright(urls, schema=schema)下面是代碼解釋?zhuān)?/span>
1. 首先,導(dǎo)入了必要的庫(kù)和工具,包括用于打印的`pprint`和LangChain中的文本拆分器`RecursiveCharacterTextSplitter`。
2. 定義了一個(gè)`scrape_with_playwright`函數(shù),該函數(shù)接收`urls`和`schema`作為參數(shù)。這里的`urls`是想要爬取的網(wǎng)站地址列表,而`schema`定義了想要從這些網(wǎng)頁(yè)中抽取的數(shù)據(jù)結(jié)構(gòu)。
3. 在函數(shù)內(nèi)部,創(chuàng)建了一個(gè)`AsyncChromiumLoader`實(shí)例并傳入了URL列表。這個(gè)加載器負(fù)責(zé)異步獲取每個(gè)URL對(duì)應(yīng)網(wǎng)頁(yè)的HTML內(nèi)容。
4. 接著,使用Beautiful Soup轉(zhuǎn)換器`BeautifulSoupTransformer`來(lái)處理加載的HTML文檔。在這個(gè)例子中,我們特別關(guān)注于`<span>`標(biāo)簽,因?yàn)槲覀兗僭O(shè)這些標(biāo)簽包含了新聞文章的標(biāo)題和摘要信息。
5. 使用`RecursiveCharacterTextSplitter`創(chuàng)建一個(gè)分割器實(shí)例,它基于給定的`chunk_size`(這里是1000個(gè)字符)來(lái)拆分文檔內(nèi)容。這是為了處理大型文檔時(shí),能夠?qū)⑵浞指畛尚K以適應(yīng)LLM處理的限制。
6. 處理拆分后的第一部分內(nèi)容,并通過(guò)`extract`函數(shù)(需要定義)來(lái)抽取出符合`schema`定義的數(shù)據(jù)。
7. 最后,使用`pprint`打印出抽取的內(nèi)容,并將其作為函數(shù)的返回值。
這個(gè)流程從頭到尾將網(wǎng)頁(yè)爬取、內(nèi)容轉(zhuǎn)換和數(shù)據(jù)抽取整合在一起,形成了一個(gè)端到端的解決方案,可以在不需要人工干預(yù)的情況下從網(wǎng)頁(yè)中提取有結(jié)構(gòu)的數(shù)據(jù)。
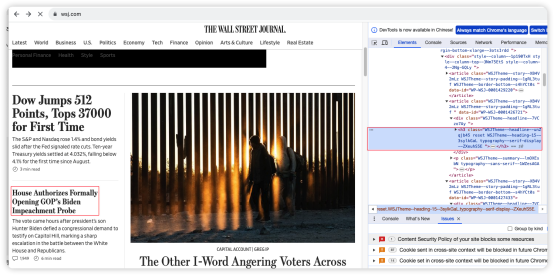
查看結(jié)果如下圖所示,由于網(wǎng)頁(yè)內(nèi)容比較多,我們選取其中一組數(shù)據(jù)來(lái)觀察,這里將新聞的標(biāo)題和摘要進(jìn)行了分割。

同時(shí),結(jié)合之前研究網(wǎng)站頁(yè)面的截圖進(jìn)行參考如下,“House Authorizes Formally Opening GOP’s Biden Impeachment Probe”這篇文章被我們通過(guò)網(wǎng)頁(yè)加載、文本轉(zhuǎn)換,大模型抽取的方式獲得了。
總結(jié)
本文詳細(xì)說(shuō)明了利用網(wǎng)絡(luò)爬蟲(chóng)技術(shù)和LLM結(jié)合的流程,通過(guò)案例分析驗(yàn)證了這一思路的可行性。從實(shí)時(shí)獲取華爾街日?qǐng)?bào)網(wǎng)站的數(shù)據(jù)開(kāi)始,文章闡述了如何通過(guò)異步HTML加載器、文本轉(zhuǎn)換工具、以及LLM進(jìn)行精準(zhǔn)的內(nèi)容抽取,最終形成一個(gè)自動(dòng)化、高效的網(wǎng)絡(luò)研究工具。這不僅展示了LLM與網(wǎng)絡(luò)爬蟲(chóng)技術(shù)結(jié)合的強(qiáng)大潛力,還探討了如何提高研究和分析效率。
作者介紹
崔皓,51CTO社區(qū)編輯,資深架構(gòu)師,擁有18年的軟件開(kāi)發(fā)和架構(gòu)經(jīng)驗(yàn),10年分布式架構(gòu)經(jīng)驗(yàn)。















