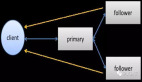
提升Raft以加速分布式鍵值存儲
介紹
Raft是當前廣泛使用的共識算法。流行的系統,如Kafka、Cockroach DB、MongoDB、Neo4j、Splunk等,都使用Raft來實現共識。系統要么是最終一致性的,要么是強一致性的。線性一致性是一致性模型中最強大的,但實現它可能很耗時。鍵值數據庫出現在市場上,以避免SQL數據庫的復雜性并提供橫向擴展性。這些數據庫主要提供兩種操作:get(key)和put(key, value)。

在我對Raft相關論文的探索中,我找到了一篇有趣的文章,標題為‘Rethink the Linearizability Constraints of Raft for Distributed Key-Value Stores’。本文詳細介紹了在類似鍵值數據庫中減少讀寫線性操作延遲以提高吞吐量的技術。本文提供了對這篇論文的簡要概述。
Raft如何處理寫請求?
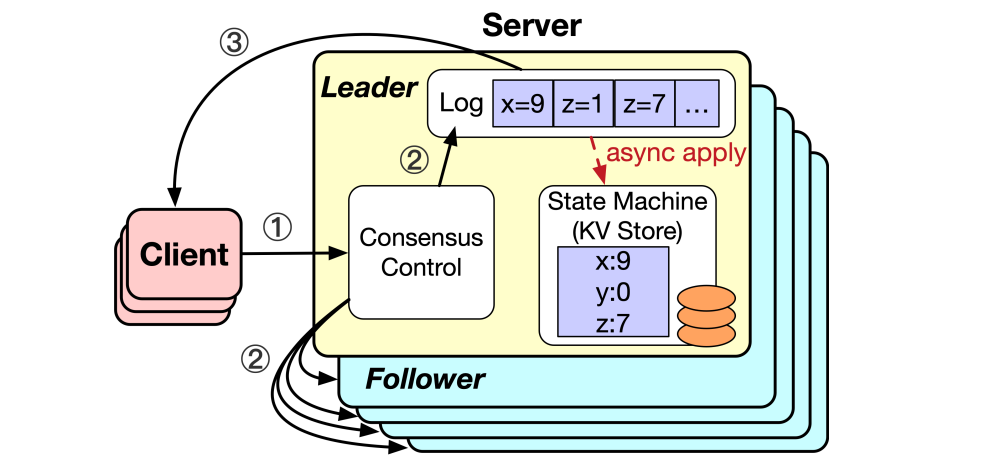
Raft處理寫請求涉及三個關鍵操作:追加(Append)、提交(Commit)和應用(Apply),因此引入了一系列用于讀寫請求處理的索引,以確保線性一致性。這些索引包括日志索引、提交索引和應用索引。
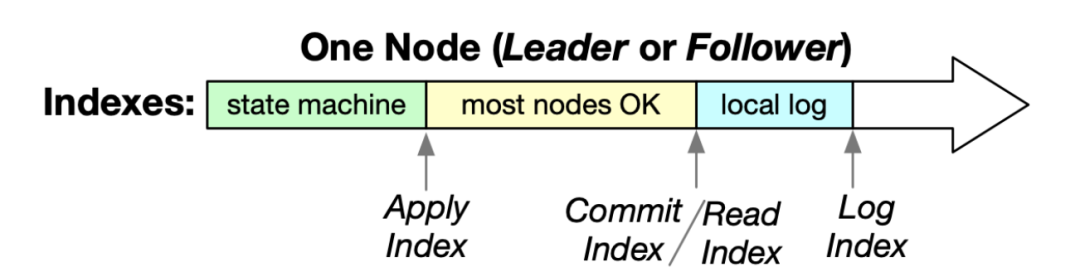
圖片來源:Paper 9458806
1.追加
當客戶端向領導者發送寫請求時,請求中的日志將被分配一個唯一遞增的索引號。領導者將日志附加到本地日志存儲,并向跟隨者發送用于復制的附加條目請求。領導者收到來自大多數跟隨者的附加條目請求的響應后,將日志設置為已提交,即新寫入的數據在系統中是安全的。
2.提交
當領導者收到附加條目請求的大多數跟隨者的響應時,日志被設置為已提交,即新寫入的數據在系統中是安全的。
3.應用
領導者開始將已提交的日志應用到其本地狀態機,并并行通知跟隨者執行相同的操作。每個節點在應用操作成功后將更新其應用索引。只有在領導者將日志應用到狀態機之后,領導者才能向客戶端返回響應。
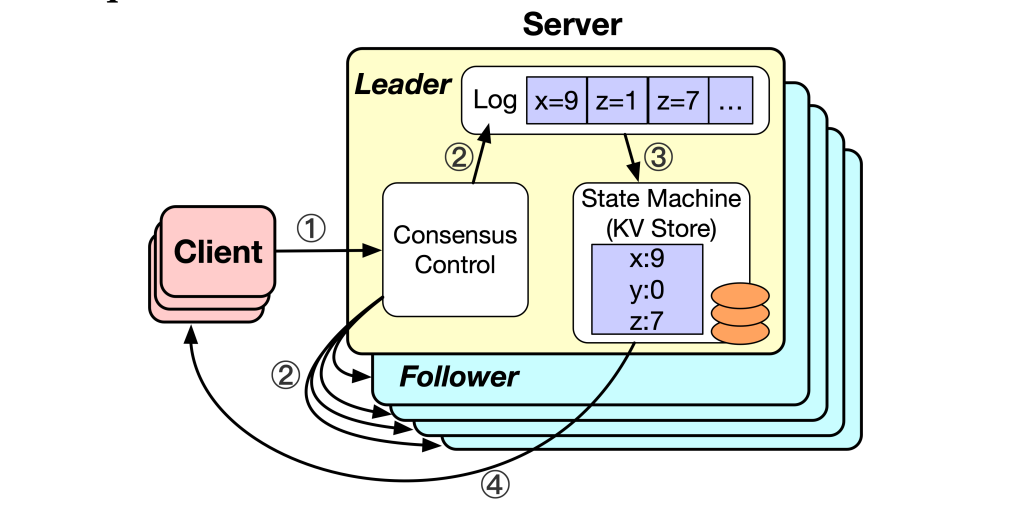
寫請求序列
Raft如何處理讀請求?
為了實現線性一致性,所有讀請求都由領導者自身處理。Raft還為此引入了讀索引。當領導者收到讀請求時,請求的讀索引設置為當前提交索引。只有當領導者的應用索引不小于讀索引時,領導者才能執行讀請求并將結果返回給客戶端。在這種情況下,我們可以確保客戶端不會獲取到陳舊的數據。
對這些操作的評估
文章討論了所有這些操作的時間消耗評估,如復制、提交和應用。根據評估,應用操作是最耗時的。對于帶有高速網絡的系統,網絡開銷較低。日志的結構簡單,日志附加通常是一個具有較高速度的順序I/O操作。因此,更新復雜的狀態機最可能成為性能瓶頸。
下圖顯示了值大小從1KB到1MB時,應用操作和所有其他操作的時間消耗百分比。它顯示應用實際上是慢的,占寫請求總時間的近40%。
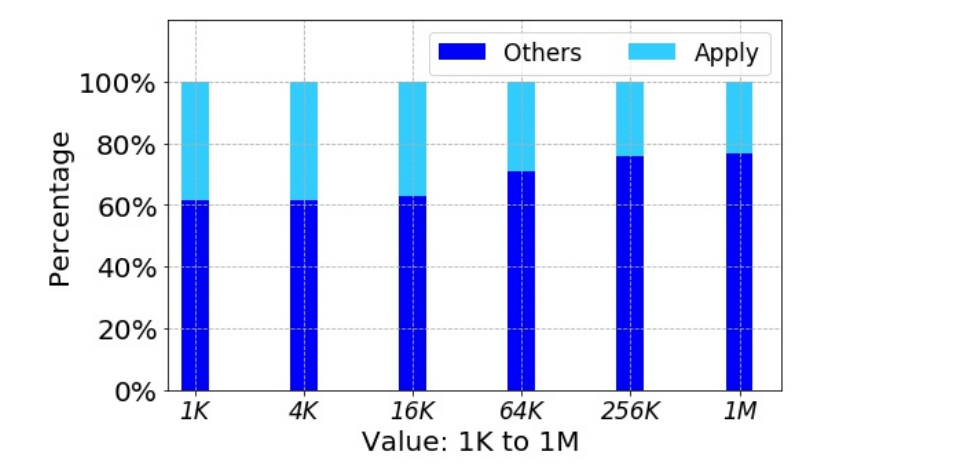
如何改進這個?
與其他類型的數據庫相比,鍵值存儲是一個簡單的數據庫。寫操作只是將鍵和值插入或更新到數據庫,而讀操作只是為給定的鍵讀取相應的值。文章證明,去除請求處理中的應用階段可能會減少延遲。應用操作可以異步執行。讀和寫操作不需要等待應用完成。為此,文章引入了兩種新方法:
- 提交返回(用于寫操作)
- 立即讀(用于讀操作)
1.提交返回
這個想法是一旦請求中的日志被提交,直接向客戶端返回成功響應,而不必等待將日志應用到狀態機。因此,這個方法被稱為提交返回。提交返回不會破壞KV存儲的正確性和線性一致性。
提交返回
2.立即讀
在Raft中,讀操作在查詢狀態機之前等待應用索引追上讀索引。當實施提交返回時,應用索引和讀索引之間的差距會比傳統Raft方法中的差距更大。因此,提交返回可以提升寫處理但可能降低讀處理。然而,如果
我們能夠消除由于應用索引和讀索引之間的差距而引起的等待時間,讀性能將得到顯著改善。
由于鍵值對的讀操作簡單,我們可以直接根據位于讀索引和應用索引之間的日志數據副本執行讀請求,而不必查詢狀態機。如果日志中存在鍵的值,則立即返回,否則查詢狀態機并返回結果。通過這種方式,讀性能將大大提高。
例子:立即讀
采用這種方法,平均寫入延遲將減少36.4% ~ 39.9%,平均讀取延遲將減少5.8% ~ 16.2%,與Raft相比。有關詳細信息,請參閱實際論文,文章中提供了論文鏈接。