模糊搜索c1 like '%a%'真的都不能走索引么

某DBA:like '%a%'肯定走不了索引的。。。
在MySQL數據庫使用規范或優化建議中都明確說類似 like '%a%'的寫法不走索引。那么,真的是在任何條件下這種寫法都不能走索引么?
1、不走索引的情況
創建一個測試表并插入測試數據
CREATE TABLE test_tb1(
id INT PRIMARY KEY ,
c1 VARCHAR(10),
c2 VARCHAR(20),
KEY idx_c1(c1)
);
INSERT INTO test_tb1
VALUES
(1,'abc','dwdwdwd'),
(2,'cadw','kklll'),
(3,'rtyu','093jx'),
(4,'sfgh','pl;,efdsf'),
(5,'l,mi','45223sda'),
(6,'rty',',ngykmb'),
(7,'mju','wedffd'),
(8,'tyuo','yuxx'),
(9,'oiuyr','qwert'),
(10,'ytuion','wwwwww');進行測試 c1 LIKE '%a%'的寫法是否走索引。
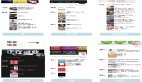
EXPLAIN SELECT * FROM test_tb1 WHERE c1 LIKE '%a%';結果如下:

從執行計劃來看,符合我們一貫的認知。
2、走索引的情況
重新創建一個表,并插入數據
# 創建表
CREATE TABLE test_tb2(
id INT PRIMARY KEY ,
c1 VARCHAR(10),
KEY idx_c1(c1)
);
# 插入數據
INSERT INTO test_tb2
VALUES
(1,'abc'),
(2,'cadw'),
(3,'rtyu'),
(4,'sfgh'),
(5,'l,mi'),
(6,'rty'),
(7,'mju'),
(8,'tyuo'),
(9,'oiuyr'),
(10,'ytuion');此時使用上述相同的SQL來看一下執行計劃。
EXPLAIN SELECT * FROM test_tb2 WHERE c1 LIKE '%a%';
此時結果與之前不同了,可以走索引了。
3、簡述原因
(1)索引內容
上述2例中的差別在于test_tb1比test_tb2多了一個c2字段,這導致在進行c1 like '%a%'查詢時,一級索引(主鍵索引)primary key 及二級索引(輔助索引)idx_c1的執行代價不同。
在MySQL中,主鍵索引存儲的是主鍵字段及對應的整條記錄的數據,即所有的數據都是按照主鍵進行排序組織在主鍵索引上的。而二級索引存儲的數據是按照對應的字段排序后的數據,包含索引字段+主鍵字段。
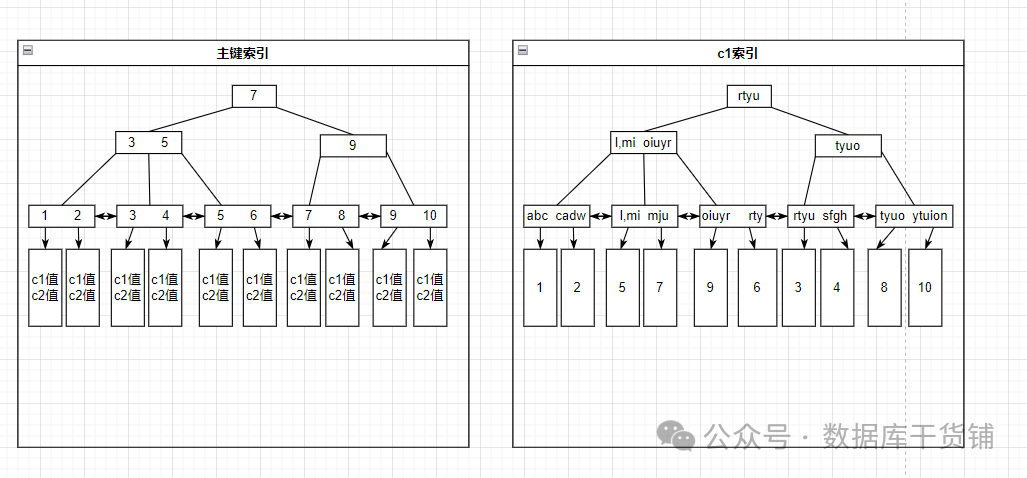
以上兩例中,一級索引與二級索引的內容如下:
例1
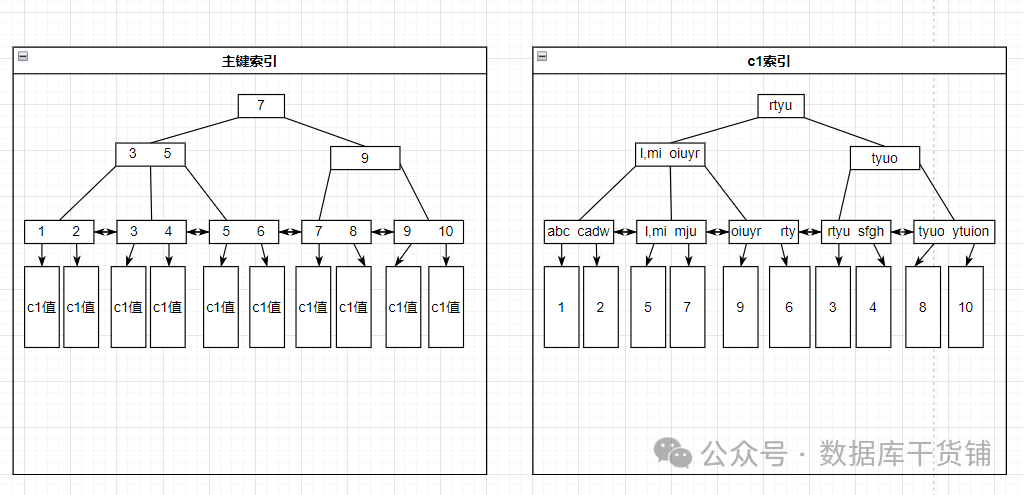
例2:
如果例1中使用c1索引,則過程是,先在c1索引上進行整個索引的掃描,然后找到主鍵字段,因為找到的內容還缺少c2的值,因此需要再回到主鍵索引上進行檢索,拿到所有字段的內容,這個代價相對較高
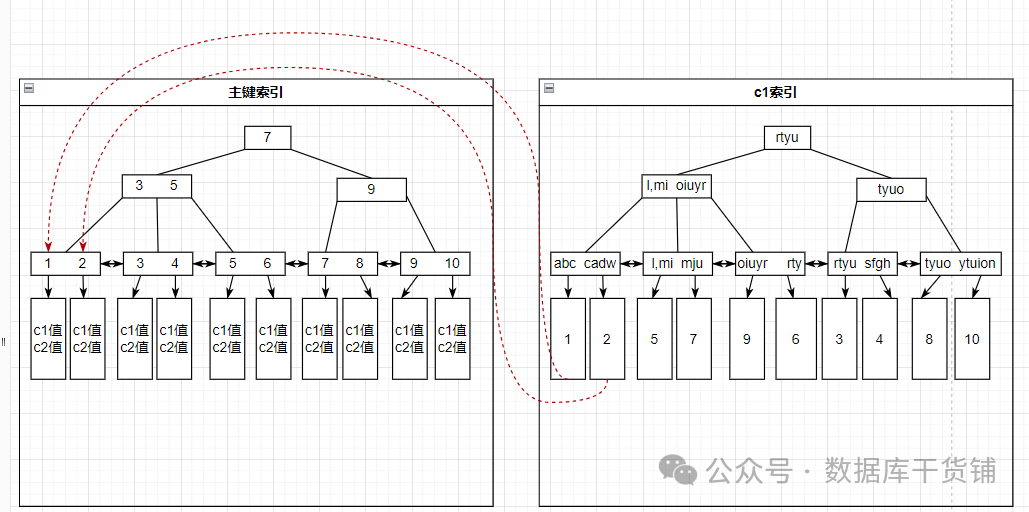
而例2中,掃描c1索引后,便得到了所有需要返回的值,而不需要再回主鍵索引上取其他內容(因為c1索引上已經有主鍵字段),因此可以選擇走c1索引。
PS:成本計算當然不止這些內容,還有一套公式,本次不贅述。
(2)例1的改寫
通過上面的對比,如果想例1中也走索引,可以只查詢c1字段或c1及主鍵id字段,此時也是可以走索引的,例如:
EXPLAIN SELECT id,c1 FROM test_tb1 WHERE c1 LIKE '%a%';
EXPLAIN SELECT c1 FROM test_tb1 WHERE c1 LIKE '%a%';
EXPLAIN SELECT id FROM test_tb1 WHERE c1 LIKE '%a%';
PS:全模糊搜索還有其他的方式解決,另外也可以使用ES等來解決。
4、小結
在數據庫學習的過程中,不可只記結論而忽視其原理。另外還有很多所謂的規范都是需要區別對待的,你知道的還有什么需要區別處理的數據庫規范么?