NeurIPS 2023精選回顧:大模型最火,清華ToT思維樹上榜
近日,作為美國前十的科技博客,Latent Space對于剛剛過去的NeurIPS 2023大會進行了精選回顧總結。
在NeurIPS會議總共接受的3586篇論文之中,除去6篇獲獎論文,其他論文也同樣優秀和具有潛力,甚至有可能預示著下一個AI領域的新突破。
那就讓我們來一起看看吧!

論文題目:QLoRA: Efficient Finetuning of Quantized LLMs

論文地址:https://openreview.net/pdf?id=OUIFPHEgJU
這篇論文提出了QLoRA,這是LoRA的一種更省內存但速度較慢的版本,它使用了幾種優化技巧來節省內存。
總體而言,QLoRA使得在對大型語言模型進行微調時可以使用更少的GPU內存。
他們訓練了一個新模型,Guanaco,僅在單個GPU上進行了為期24小時的微調,并在Vicuna基準測試中表現優于先前的模型。
與此同時,研究人員還開發了其他方法,如4-bit LoRA量化,其效果相似。

論文題目:DataComp: In search of the next generation of multimodal datasets

論文地址:https://openreview.net/pdf?id=dVaWCDMBof
多模態數據集在最近的突破中扮演著關鍵角色,如CLIP、Stable Diffusion和GPT-4,但與模型架構或訓練算法相比,它們的設計并沒有得到同等的研究關注。
為了解決這一機器學習生態系統中的不足,研究人員引入了DataComp,這是一個圍繞Common Crawl的新候選池中的128億個圖文對進行數據集實驗的測試平臺。
使用者可以通過DataComp進行實驗,設計新的過濾技術或精心策劃新的數據源,并通過運行標準化的CLIP訓練代碼,以及在38個下游測試集上測試生成的模型,來評估他們的新數據集。
結果顯示,最佳基準DataComp-1B,允許從頭開始訓練一個CLIP ViT-L/14模型,其在ImageNet上的零樣本準確度達到了79.2%,比OpenAI的CLIP ViT-L/14模型高出3.7個百分點,以此證明DataComp工作流程可以產生更好的訓練集。

論文題目:Visual Instruction Tuning

論文地址:https://arxiv.org/pdf/2304.08485v1.pdf
在這篇論文中,研究人員提出了首次嘗試使用僅依賴語言的GPT-4生成多模態語言-圖像指令跟隨數據的方法。
通過在這種生成的數據上進行指令調整,引入了LLaVA:Large Language and Vision Assistant,這是一個端到端訓練的大型多模態模型,連接了一個視覺編碼器和LLM,用于通用的視覺和語言理解。
早期實驗證明LLaVA展示了令人印象深刻的多模態聊天能力,有時展現出多模態GPT-4在未見過的圖像/指令上的行為,并在合成的多模態指令跟隨數據集上與GPT-4相比取得了85.1%的相對分數。
在對科學問答進行微調時,LLaVA和GPT-4的協同作用實現了92.53%的新的最先進準確性。

論文題目:Tree of Thoughts: Deliberate Problem Solving with Large Language Models

論文地址:https://arxiv.org/pdf/2305.10601.pdf
語言模型越來越多地被用于廣泛的任務中進行一般性問題解決,但在推理過程中仍受限于標記級別、從左到右的決策過程。這意味著它們在需要探索、戰略前瞻或初始決策起關鍵作用的任務中可能表現不佳。
為了克服這些挑戰,研究人員引入了一種新的語言模型推理框架,Tree of Thoughts(ToT),它在促使語言模型方面推廣了流行的Chain of Thought方法,并允許在一致的文本單元(思想)上進行探索,這些單元作為解決問題的中間步驟。
ToT使語言模型能夠通過考慮多條不同的推理路徑和自我評估選擇來做出刻意的決策,以決定下一步行動,并在必要時展望或回溯以做出全局性的選擇。
實驗證明,ToT顯著提高了語言模型在需要非平凡規劃或搜索的三個新任務上的問題解決能力:24點游戲、創意寫作和迷你填字游戲。例如,在24點游戲中,雖然使用Chain of Thought提示的GPT-4只解決了4%的任務,但ToT實現了74%的成功率。

論文題目:Toolformer: Language Models Can Teach Themselves to Use Tools

論文地址:https://arxiv.org/pdf/2302.04761.pdf
語言模型表現出在從少量示例或文本指令中解決新任務方面的顯著能力,尤其是在大規模情境下。然而,令人矛盾的是,它們在基本功能方面(如算術或事實查找),相較于更簡單且規模較小的專門模型,卻表現出困難。
在這篇論文中,研究人員展示了語言模型可以通過簡單的API自學使用外部工具,并實現兩者的最佳結合。
他們引入了Toolformer,這個模型經過訓練能夠決定調用哪些API、何時調用它們、傳遞什么參數以及如何最佳地將結果合并到未來的token預測中。
這是以自監督的方式完成的,每個API只需要少量演示即可。他們整合了各種工具,包括計算器、問答系統、搜索引擎、翻譯系統和日歷等。
Toolformer在與更大模型競爭的時候,在各種下游任務中取得了明顯改善的零樣本性能,而不會犧牲其核心語言建模能力。
論文題目:Voyager: An Open-Ended Embodied Agent with Large Language Models

論文地址:https://arxiv.org/pdf/2305.16291.pdf
該論文介紹了Voyager,這是第一個由大型語言模型(LLM)驅動的,可以在Minecraft中連續探索世界、獲取多樣化技能并進行獨立發現的learning agent。
Voyager包含三個關鍵組成部分:
自動課程,旨在最大程度地推動探索,
不斷增長的可執行代碼技能庫,用于存儲和檢索復雜行為,
新的迭代提示機制,整合了環境反饋、執行錯誤和自我驗證以改進程序。
Voyager通過黑盒查詢與GPT-4進行交互,避免了對模型參數進行微調的需求。
根據實證研究,Voyager展現出強大的環境上下文中的終身學習能力,并在玩Minecraft方面表現出卓越的熟練度。
它獲得了比先前技術水平高出3.3倍的獨特物品,行進距離更長2.3倍,并且解鎖關鍵技術樹里程碑的速度比先前技術水平快15.3倍。
不過,雖然Voyager能夠在新的Minecraft世界中利用學到的技能庫從零開始解決新穎任務,但其他技術則難以泛化。

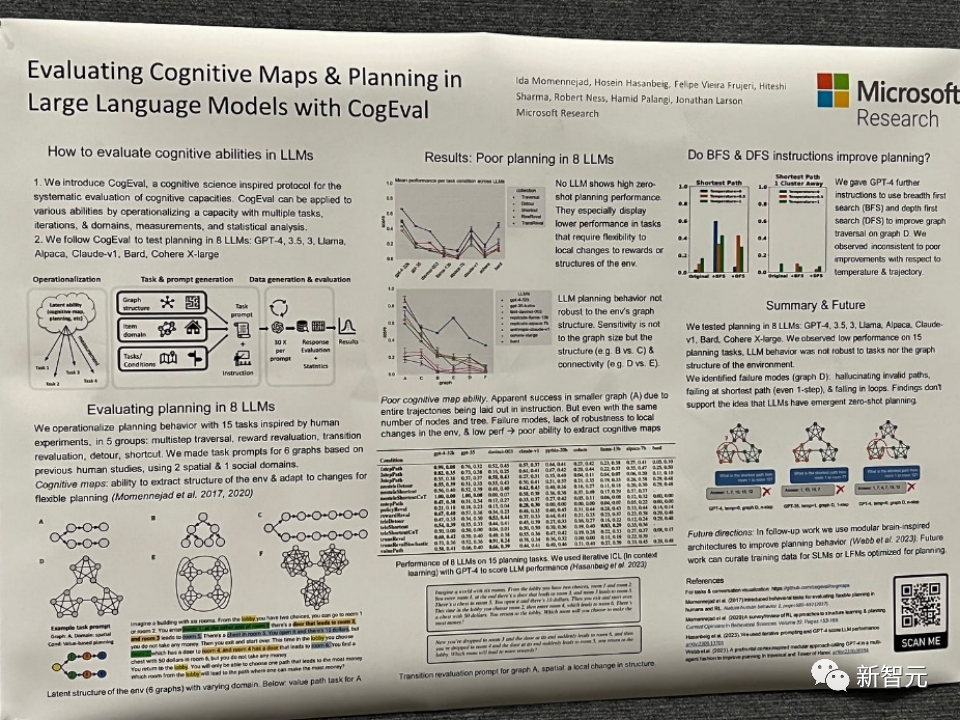
論文題目:Evaluating Cognitive Maps and Planning in Large Language Models with CogEval

論文地址:https://openreview.net/pdf?id=VtkGvGcGe3
該論文首先提出了CogEval,這是一個受認知科學啟發的系統評估大型語言模型認知能力的協議。
其次,論文使用CogEval系統評估了八個LLMs(OpenAI GPT-4、GPT-3.5-turbo-175B、davinci-003-175B、Google Bard、Cohere-xlarge-52.4B、Anthropic Claude-1-52B、LLaMA-13B和Alpaca-7B)的認知地圖和規劃能力。任務提示基于人類實驗,并且不在LLM訓練集中存在。
研究發現,雖然LLMs在一些結構較簡單的規劃任務中顯示出明顯的能力,但一旦任務變得復雜,LLMs就會陷入盲區,包括對無效軌跡的幻覺和陷入循環。
這些發現不支持LLMs具有即插即用的規劃能力的觀點。可能是因為LLMs不理解規劃問題背后的潛在關系結構,即認知地圖,并在根據基礎結構展開目標導向軌跡時出現問題。
論文題目:Mamba: Linear-Time Sequence Modeling with Selective State Spaces

論文地址:https://openreview.net/pdf?id=AL1fq05o7H
作者指出了目前許多次線性時間架構,如線性注意力、門控卷積和循環模型,以及結構化狀態空間模型(SSMs),旨在解決Transformer在處理長序列時的計算效率低下問題。然而,這些模型在重要的語言等領域上并沒有像注意力模型那樣表現出色。作者認為這些
型的一個關鍵弱點是它們無法進行基于內容的推理,并進行了一些改進。
首先,簡單地讓 SSM 參數作為輸入的函數,可以解決其離散模態的弱點,允許模型根據當前標記選擇性地沿序列長度維度傳播或忘記信息。
其次,盡管這種變化阻止了高效卷積的使用,但作者在循環模式下設計了一種硬件感知的并行算法。將這些選擇性 SSM 集成到簡化的端到端神經網絡架構中,無需注意力機制,甚至不需要 MLP 模塊 (Mamba)。
Mamba在推理速度上表現出色(比Transformers高5倍),并且在序列長度上呈線性縮放,在真實數據上的性能提高了,達到了百萬長度序列。
作為一種通用的序列模型骨干,Mamba在語言、音頻和基因組學等多個領域取得了最先進的性能。在語言建模方面,Mamba-1.4B模型在預訓練和下游評估中均優于相同大小的Transformers模型,與其兩倍大小的Transformers模型相匹敵。

雖然這些論文在2023年沒有獲得獎項,但比如Mamba,作為一種能夠革新語言模型架構的技術模型,評估其影響還為時過早。
明年NeurIPS會如何走向,2024的人工智能和神經信息系統領域又會如何發展,雖然目前眾說紛紜,但又有誰能打包票呢?讓我們拭目以待。