













精確率提升7.8%!首個多模態開放世界檢測大模型MQ-Det登NeurIPS 2023
目前的開放世界目標檢測模型大多遵循文本查詢的模式,即利用類別文本描述在目標圖像中查詢潛在目標,但這種方式往往會面臨「廣而不精」的問題。

論文鏈接:https://arxiv.org/abs/2305.18980
代碼地址:https://github.com/YifanXu74/MQ-Det
為此,中科院自動化等機構的研究人員提出了基于多模態查詢的目標檢測MQ-Det,以及首個同時支持文本描述和視覺示例查詢的開放世界檢測大模型。
MQ-Det在已有基于文本查詢的檢測大模型基礎上,加入了視覺示例查詢功能。通過引入即插即用的門控感知結構,以及以視覺為條件的掩碼語言預測訓練機制,使得檢測器在保持高泛化性的同時支持細粒度的多模態查詢,為用戶提供更靈活的選擇來適應不同的場景。
其簡單有效的設計與現有主流的檢測大模型均兼容,適用范圍非常廣泛。
實驗表明,多模態查詢能夠大幅度推動主流檢測大模型的開放世界目標檢測能力,例如在基準檢測數據集LVIS上,無需下游任務模型微調,提升主流檢測大模型GLIP精度約7.8%AP,在13個基準小樣本下游任務上平均提高了6.3% AP。
從文本查詢到多模態查詢
一圖勝千言
隨著圖文預訓練的興起,借助文本的開放語義,目標檢測逐漸步入了開放世界感知的階段。
為此,許多檢測大模型都遵循了文本查詢的模式,即利用類別文本描述在目標圖像中查詢潛在目標。
然而,這種方式往往會面臨「廣而不精」的問題。
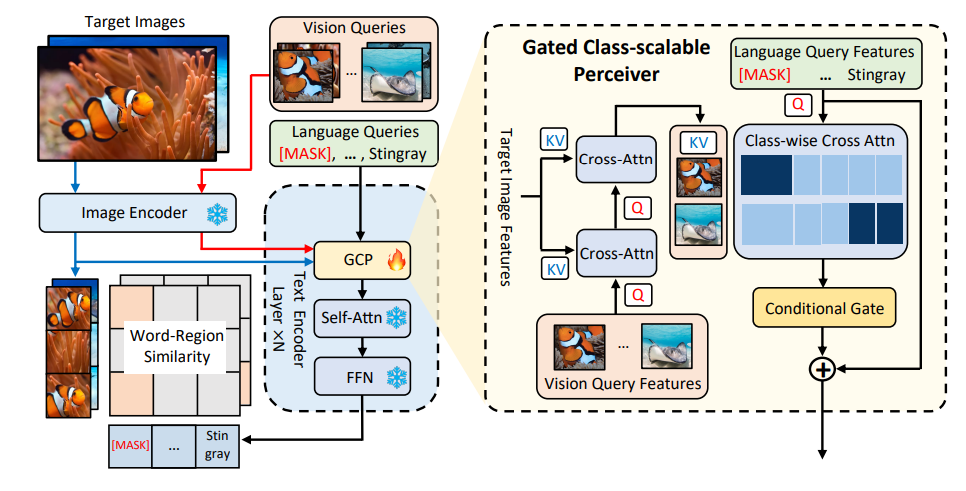
圖1 MQ-Det方法架構圖
例如,圖1中的細粒度物體(魚種)檢測,往往很難用有限的文本來描述各種細粒度的魚種;類別歧義,bat既可指蝙蝠又可指拍子。
然而,以上的問題均可通過圖像示例來解決,相比文本,圖像能夠提供目標物體更豐富的特征線索,但同時文本又具備強大的泛化性。
由此,如何能夠有機地結合兩種查詢方式,成為了一個很自然地想法。
獲取多模態查詢能力的難點:如何得到這樣一個具備多模態查詢的模型,存在三個挑戰:
1. 直接用有限的圖像示例進行微調很容易造成災難性遺忘;
2. 從頭訓練一個檢測大模型會具備較好的泛化性但是消耗巨大,例如,單卡訓練GLIP[1]需要利用3000萬數據量訓練480 天。
多模態查詢目標檢測:基于以上考慮,作者提出了一種簡單有效的模型設計和訓練策略——MQ-Det
MQ-Det在已有凍結的文本查詢檢測大模型基礎上插入少量門控感知模塊(GCP)來接收視覺示例的輸入,同時設計了視覺條件掩碼語言預測訓練策略高效地得到高性能多模態查詢的檢測器。
MQ-Det:即插即用的多模態查詢模型架構
門控感知模塊
如圖1所示,作者在已有凍結的文本查詢檢測大模型的文本編碼器端逐層插入了門控感知模塊(GCP),GCP的工作模式可以用下面公式簡潔地表示:
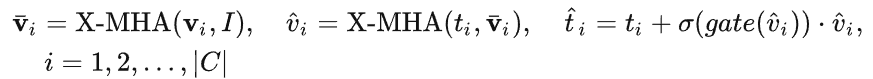
對于第i個類別,輸入視覺示例 v_i,其首先和目標圖像  進行交叉注意力( X-MHA)得到
進行交叉注意力( X-MHA)得到 以增廣其表示能力,而后每個類別文本 t_i 會和對應類別的視覺示例
以增廣其表示能力,而后每個類別文本 t_i 會和對應類別的視覺示例  進行交叉注意力得到
進行交叉注意力得到  ,之后通過一個門控模塊gate 將原始文本 t_i 和視覺增廣后文本
,之后通過一個門控模塊gate 將原始文本 t_i 和視覺增廣后文本  融合,得到當前層的輸出
融合,得到當前層的輸出
這樣的簡單設計遵循了三點原則:(1)類別可擴展性;(2)語義補全性;(3)抗遺忘性,具體討論可見原文。
MQ-Det高效訓練策略
基于凍結語言查詢檢測器的調制訓練
由于目前文本查詢的預訓練檢測大模型本身就具備較好的泛化性,作者認為,只需要在原先文本特征基礎上用視覺細節進行輕微地調整即可。
在文章中也有具體的實驗論證發現,打開原始預訓練模型參數后進行微調很容易帶來災難性遺忘的問題,反而失去了開放世界檢測的能力。
由此,MQ-Det在凍結文本查詢的預訓練檢測器基礎上,僅調制訓練插入的GCP模塊,就可以高效地將視覺信息插入到現有文本查詢的檢測器中。
在文章中,作者分別將MQ-Det的結構設計和訓練技術應用于目前的SOTA模型GLIP[1]和GroundingDINO[2],來驗證方法的通用性。
以視覺為條件的掩碼語言預測訓練策略
作者還提出了一種視覺為條件的掩碼語言預測訓練策略,來解決凍結預訓練模型帶來的學習惰性的問題。
所謂學習惰性,即指檢測器在訓練過程中傾向于保持原始文本查詢的特征,從而忽視新加入的視覺查詢特征。
為此,MQ-Det在訓練時隨機地用[MASK] token來替代文本token,迫使模型向視覺查詢特征側學習,即:

這個策略雖然簡單,但是卻十分有效,從實驗結果來看這個策略帶來了顯著的性能提升。
實驗結果
Finetuning-free
相比傳統零樣本(zero-shot)評估僅利用類別文本進行測試,MQ-Det提出了一種更貼近實際的評估策略:finetuning-free
其定義為:在不進行任何下游微調的條件下,用戶可以利用類別文本、圖像示例、或者兩者結合來進行目標檢測。
在finetuning-free的設定下,MQ-Det對每個類別選用了5個視覺示例,同時結合類別文本進行目標檢測,而現有的其他模型不支持視覺查詢,只能用純文本描述進行目標檢測。
下表展示了在LVIS MiniVal和LVIS v1.0上的檢測結果。可以發現,多模態查詢的引入大幅度提升了開放世界目標檢測能力。
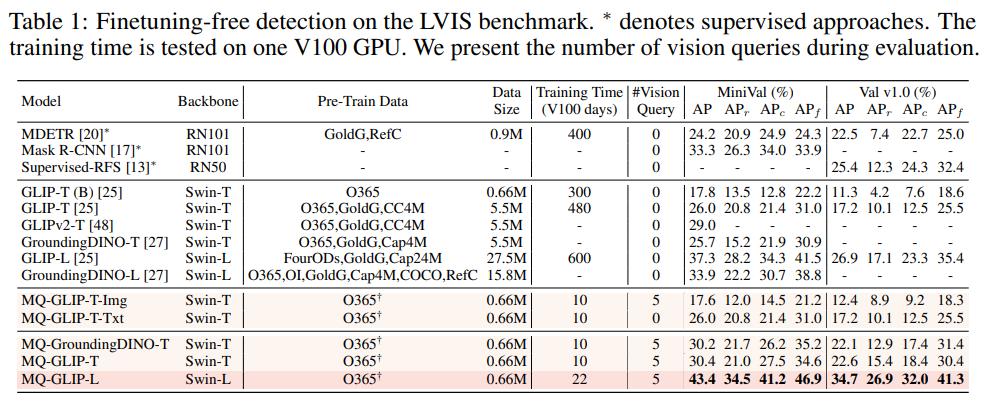
表1 各個檢測模型在LVIS基準數據集下的finetuning-free表現
從表1可以看到,MQ-GLIP-L在GLIP-L基礎上提升了超過7%AP,效果十分顯著!
Few-shot評估
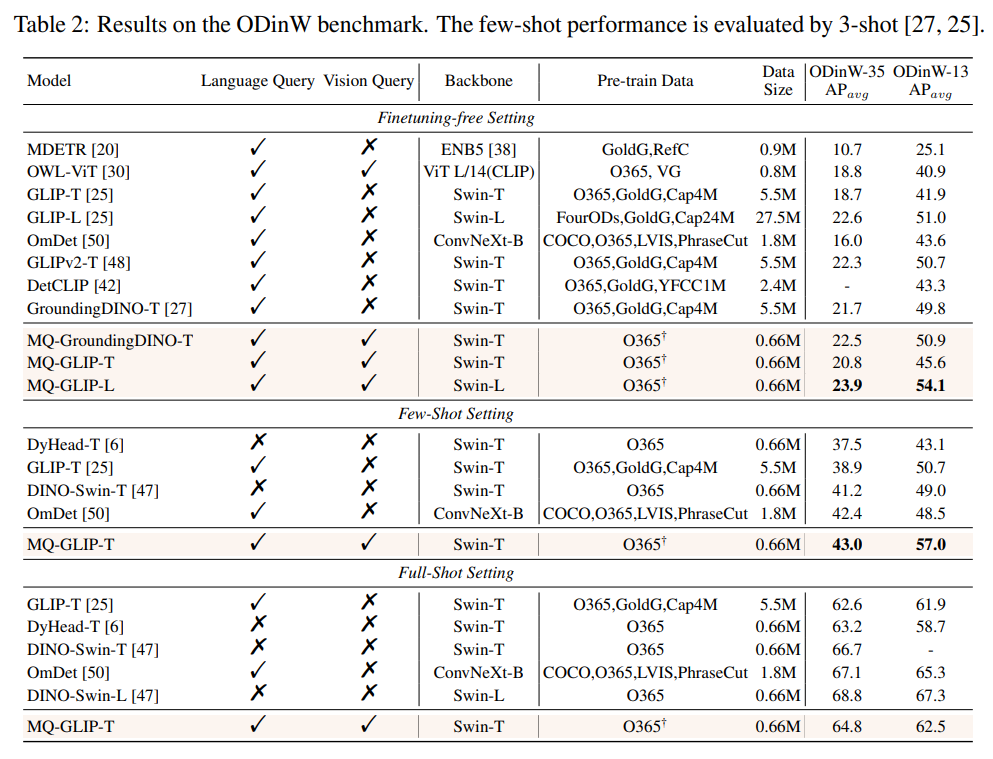
表2 各個模型在35個檢測任務ODinW-35以及其13個子集ODinW-13中的表現
作者還進一步在下游35個檢測任務ODinW-35中進行了全面的實驗。由表2可以看到,MQ-Det除了強大的finetuning-free表現,還具備良好的小樣本檢測能力,進一步印證了多模態查詢的潛力。圖2也展示了MQ-Det對于GLIP的顯著提升。

圖2 數據利用效率對比;橫軸:訓練樣本數量,縱軸:OdinW-13上的平均AP
多模態查詢目標檢測的前景
目標檢測作為一個以實際應用為基礎的研究領域,非常注重算法的落地。
盡管以往的純文本查詢目標檢測模型展現出了良好的泛化性,但是在實際的開放世界檢測中文本很難涵蓋細粒度的信息,而圖像中豐富的信息粒度完美地補全了這一環。
至此我們能夠發現,文本泛而不精,圖像精而不泛,如果能夠有效地結合兩者,即多模態查詢,將會推動開放世界目標檢測進一步向前邁進。
MQ-Det在多模態查詢上邁出了第一步嘗試,其顯著的性能提升也昭示著多模態查詢目標檢測的巨大潛力。
同時,文本描述和視覺示例的引入為用戶提供了更多的選擇,使得目標檢測更加靈活和用戶友好。




























