兩億參數時序模型替代LLM?谷歌突破性研究被批「犯新手錯誤」
最近,谷歌的一篇論文在 X 等社交媒體平臺上引發了一些爭議。
這篇論文的標題是「A decoder-only foundation model for time-series forecasting(用于時間序列預測的僅解碼器基礎模型)」。

簡而言之,時間序列預測就是通過分析歷史數據的變化趨勢和模式,來預測未來的數據變化。這類技術在氣象預報、交通流量預測、商業銷售等領域有著廣泛的應用。例如,在零售業中,提高需求預測的準確性可以有效降低庫存成本并增加收入。
近年來,深度學習模型已成為預測豐富的多變量時間序列數據的流行方法,因為它們已被證明在各種環境中表現出色。
但是,這些模型也面臨一些挑戰:大多數深度學習架構需要漫長而復雜的訓練和驗證周期,急需一個開箱即用的基礎模型來縮短這一周期。
谷歌的新論文就是為了解決這一問題而誕生的。在論文中,他們提出了一個用于時間序列預測的僅解碼器基礎模型 ——TimesFM。這是一個在 1000 億個真實世界時間點的大型時間序列語料庫上預訓練的單一預測模型。與最新的大型語言模型相比,TimesFM 要小得多(僅 200M 參數)。但他們發現,即使在這樣的規模下,它在不同領域和時間粒度的各種未見數據集上的零樣本性能也接近于在這些數據集上顯式訓練的 SOTA 監督方法。
這個想法看起來很有前景,有人評價說,「TimesFM 證明了預訓練大型時間序列語料庫的力量。它在各種公開的基準測試中展示的零樣本性能真的令人稱奇」。

但也有人對其采用的評估方法和基準產生了質疑,畢業于倫敦大學皇家霍洛威學院的 Valery Manokhin 博士指出,論文作者犯了一些「新手錯誤」,還采用了一些「欺騙性」的基準。

事情到底是怎么回事?我們先來看看谷歌的這篇論文寫了什么。
被質疑的論文寫了什么?
上周五,谷歌 AI 專門用博客介紹了這一研究。

我們目前常見的大語言模型(LLM)通常在訓練時僅用解碼器,過程涉及三個步驟。首先,文本被分解為稱為標記的子詞 ——token。然后,token 被輸入到堆疊的因果 transformer 層中,這些層會生成與每個輸入 token 相對應的輸出。最后,第 i 個 token 對應的輸出總結了之前 token 的所有信息并預測第 (i+1) 個 token。
在推理過程中,LLM 一次生成一個 token 的輸出。例如,當提示「What is the capital of France?」時,它可能會生成 token「The」,然后以「What is the capital of France? The」為條件。生成下一個標記「capital」,依此類推,直到生成完整的答案:「The capital of France is Paris」。
谷歌認為,時間序列預測的基礎模型可以適應可變的上下文(我們觀察到的內容)和范圍(我們查詢模型預測的內容)長度,同時具有足夠的能力對大型預訓練數據集中的所有模式進行編碼。
與 LLM 類似,我們可以使用堆疊 transformer 層(自注意力層和前饋層)作為 TimesFM 模型的主要構建塊。在時間序列預測的背景下,將 patch(一組連續的時間點)視為最近長期預測工作的 token。隨后,任務是根據堆疊 transformer 層末尾的第 i 個輸出來預測第 (i+1) 個時間點 patch。
在論文《A decoder-only foundation model for time-series forecasting》中,谷歌研究人員嘗試設計了一個時間序列基礎模型,在零樣本(zero-shot)任務上取得了不錯的效果:

論文鏈接:https://arxiv.org/abs/2310.10688
該研究中,研究者設計了一種用于預測的時間序列基礎模型 TimesFM,其在各種公共數據集上的 zero-shot 能力都接近于目前業內的頂尖水平。此模型是一種在包含真實世界和合成數據的大型時間序列語料庫上進行預訓練的,修補解碼器式注意力模型,參數只有兩億。
谷歌表示,對于首次遇見的各種預測數據集進行的實驗表明,該模型可以在不同領域、預測范圍和時間粒度上產生準確的零樣本預測。
時間序列的基礎模型可以大幅減少訓練數據和計算需求,為應用端帶來很多好處。不過,時間序列推理的基礎模型是否是一種可行的思路,人們還未有定論,首先與 NLP 不同,時間序列沒有明確定義的詞匯或語法。此外,新模型需要支持具有不同歷史長度(上下文)、預測長度(范圍)和時間粒度的預測。此外,與用于預訓練語言模型的大量公共文本數據不同,大型時間序列數據集并不容易構建。
谷歌表示,盡管存在這些問題,他們還是提供了證據來肯定地回答上述問題。

圖 1:訓練過程中的模型架構。其中顯示了可以分解為輸入補丁的特定長度的輸入時間序列。
它與常規的語言模型有幾個關鍵的區別。首先,我們需要一個具有殘差連接的多層感知器塊,將時間序列 patch 轉換為可以與位置編碼(PE)一起輸入到 Transformer 層的 token。為此,谷歌使用了與他們之前的長期預測工作類似的殘差塊。其次,在另一端,來自堆疊 Transformer 的輸出 token 可用于預測比輸入 patch 長度更長的后續時間點的長度,即輸出 patch 長度可以大于輸入 patch 長度。
谷歌研究者認為,即使基線針對每個特定任務進行了專門訓練或調整,TimesFM 的單個預訓練模型也可以在基準測試中接近或超過基線模型的性能。

圖 2:新方法與常規方法在三組數據集上的平均性能對比,指標越低越好。谷歌表示,在基線測試中,只有 TimesFM 和 llmtime 是零樣本。
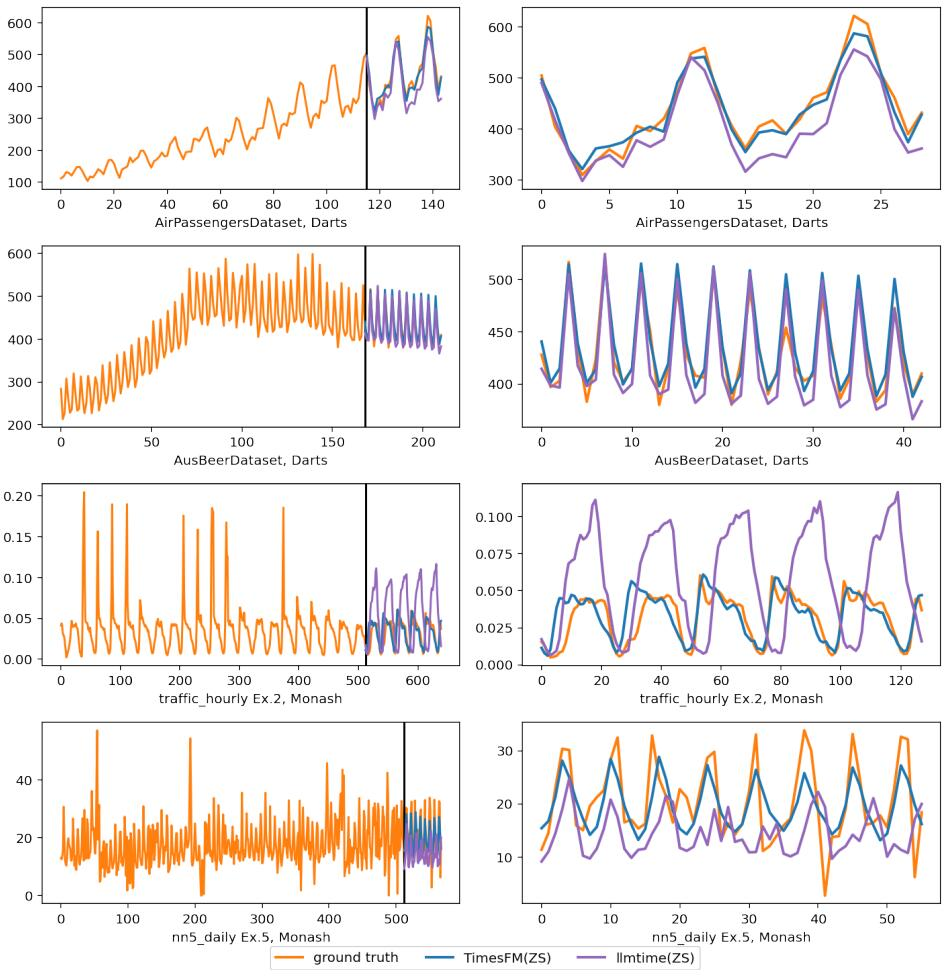
圖 6:在 Darts 和 Monash 數據集上的推理可視化。右側的圖放大了左側的預測部分。
看起來,從背景到思路,方法到測試的一套流程都已走完,事情就順理成章了,谷歌還計劃在今年內通過 Google Cloud Vertex AI 向外部客戶提供此模型。
哪知道論文竟引起了爭議。
Valery Manokhin 提出了哪些質疑?
對論文評估方法和所選基準提出質疑的是機器學習博士 Valery Manokhin。他的研究領域包括概率預測、符合預測、機器學習、深度學習、人工神經網絡、人工智能和數據挖掘等。
他指出,首先,論文中使用圖表(特別是圖 6)以視覺方式展示模型性能是一個初學者的錯誤。Christoph Bergmeir 和 Hansika Hewamalage 在其教程《數據科學家的預測評估:常見陷阱和最佳實踐(Forecast Evaluation for Data Scientists: Common Pitfalls and Best Practices)》中明確指出,生成預測的視覺吸引力或其可能性不是評價預測的好標準。

接下來,Valery Manokhin 提到,谷歌的作者使用了一種標準策略來美化他們的「基礎模型」性能,即選擇那些可以被傳統模型非常容易且幾乎完美地擬合的經典數據集(如非常老的航空乘客數據)。而且,谷歌的作者沒有選擇傳統模型作為基準進行比較,而是選擇了另一個表現不佳的模型(llmtime)作為對照。


針對 Valery 提出的質疑,谷歌研究院的 Rajat Sen(論文作者之一)在帖子下面給出了回應。首先,他指出,批評者僅關注了論文中一個關于航空乘客數據集的示例,并錯誤地認為這是他們唯一展示的性能數據。作者澄清說他們實際上在多個數據集(Monash、Darts 和 ETT)上報告了模型的性能。

而且,作者強調,他們并沒有通過視覺方式來評估模型性能。圖 6 僅僅是為了示例目的,而綜合性能是在圖 2 中報告的。


作者明確指出,他們沒有選擇性挑選結果來美化模型性能。在圖 2 中,他們公正地展示了一些監督學習模型可能比他們的模型表現得更好,但他們的模型是一個零樣本模型,這是一個重要的優勢。
但 Valery Manokhin 隨后又指出,在 Monash 數據集上,谷歌的 TimesFM 落后于其他模型。

對此,Rajat Sen 指出,Valery Manokhin 忽略了一個很重要的點:TimesFM 的表現優于 Monash 上的很多既有基線,但最重要的是,這些基線是單獨在這些數據集上「訓練」的,而 TimesFM 是「零樣本」預測的。

隨后,二人的爭論又集中到了文中的一句話上。作者在論文的引入部分寫道,「在一些預測競賽,如 M5 競賽(M5 “Accuracy” competition)和 IARAI Traffic4cast 競賽中,幾乎所有獲勝的解決方案都是基于深度神經網絡的。」Valery Manokhin 認為這句話具有誤導性。


對此,Rajat Sen 表示,這不是文章的核心論點,還有進一步討論的空間。

如今,二人的爭論還在 X 平臺上持續更新,感興趣的讀者可以前去觀戰。