













在 2023 年結束的國際學術會議 AIBT 2023 上,Ratidar Technologies LLC 宣讀了一篇基于公平性的排序學習算法,并且獲得了該會議的最佳論文報告獎。該算法的名字是斯奇拉姆排序 (Skellam Rank),充分利用了統計學中的原理,結合 Pairwise Ranking 和矩陣分解,同時解決了推薦系統中的準確率和公平性的問題。因為推薦系統中的排序學習的原創算法很少,外加斯奇拉姆排序算法性能優異,因此在會議上獲得了研究獎項。下面我們來介紹斯奇拉姆算法的基本原理:
我們首先回憶一下泊松分布:
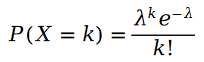
泊松分布的參數 的計算公式如下:
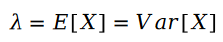
兩個泊松變量的差值是斯奇拉姆分布:
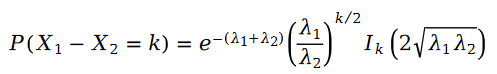
在公式中,我們有:
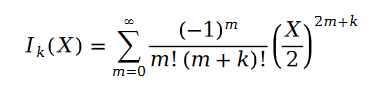
函數 叫做第一類貝塞爾函數。
有了這些最基本的統計學中的概念,下面讓我們來構建一個 Pairwise Ranking 的排序學習推薦系統吧!
我們首先認為用戶給物品的打分是個泊松分布的概念。也就是說,用戶物品評分值服從以下概率分布:
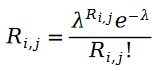
之所以我們可以把用戶給物品打分的過程描述為泊松過程,是因為用戶物品評分存在馬太效應,也就是說評分越高的用戶,打分的人越多,以至于我們可以用某個物品的評分的人的數量來近似該物品的評分的分布。給某個物品打分的人數服從什么隨機過程呢?自然而然的,我們就會想到泊松過程。因為用戶給物品打分的概率和該物品有多少人打分的概率相近,我們自然也就可以用泊松過程來近似用戶給物品打分的這一過程了。
我們下面把泊松過程的參數用樣本數據的統計量替代,得到下面的公式:
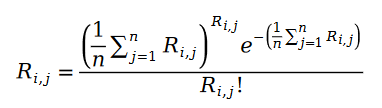
我們下面定義 Pariwise Ranking 的最大似然函數公式。眾所周知,所謂 Pairwise Ranking 指的是我們利用最大似然函數求解模型參數,使得模型能夠最大程度保持數據樣本中已知的排序對的關系:
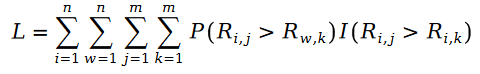
因為公式中的 R 是泊松分布,所以它們的差值,就是斯奇拉姆分布,也就是說:

其中變量 E 是按照如下方式定義的:
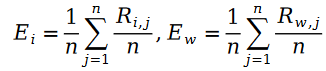
我們把斯奇拉姆分布的公式帶入最大似然函數的損失函數 L ,得到了如下公式:
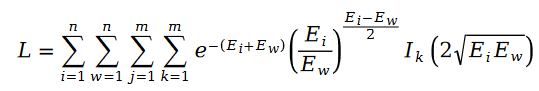
在變量 E 中出現的用戶評分值 R ,我們利用矩陣分解的方式進行求解。將矩陣分解中的參數用戶特征向量 U 和物品特征向量 V 作為待求解變量:
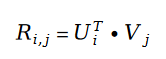
這里我們先回顧一下矩陣分解的概念。矩陣分解的概念是在 2010 年左右的時候提出的推薦系統算法,該算法可以說是歷史上最成功的推薦系統算法之一。時至今日,仍然有大量的推薦系統公司利用矩陣分解算法作為線上系統的 baseline,而時下大熱的經典推薦算法 DeepFM 中的重要組件 Factorization Machine,也是推薦系統算法中的矩陣分解算法后續的改進版本,和矩陣分解有千絲萬縷的聯系。矩陣分解算法有個里程碑論文,是 2007 年的 Probabilistic Matrix Factorization,作者利用統計學習模型對矩陣分解這個線性代數中的概念重新建模,使得矩陣分解第一次有了扎實的數學理論基礎。
矩陣分解的基本概念,是利用向量的點乘,在對用戶評分矩陣進行降維的同時高效的預測未知的用戶評分。矩陣分解的損失函數如下:
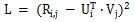
矩陣分解算法有許多的變種,比如上海交大提出的 SVDFeature,把向量 U 和 V 用線性組合的形式進行建模,使得矩陣分解的問題變成了特征工程的問題。SVDFeature 也是矩陣分解領域的里程碑論文。矩陣分解可以被應用在 Pairwise Ranking 中用以取代未知的用戶評分,從而達到建模的目的,經典的應用案例包括 Bayesian Pairwise Ranking 中的 BPR-MF 算法,而斯奇拉姆排序算法就是借鑒了同樣的思路。
我們用隨機梯度下降對斯奇拉姆排序算法進行求解。因為隨機梯度下降在求解過程中,可以對損失函數進行大量的簡化從而達到求解的目的,我們的損失函數變成了下面的公式:
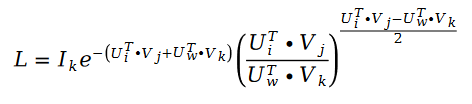
利用隨機梯度下降對未知參數 U 和 V 進行求解,我們得到了迭代公式如下:
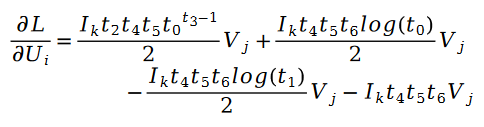
其中:
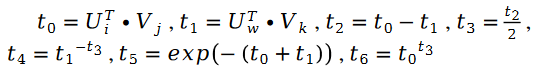
另外有:
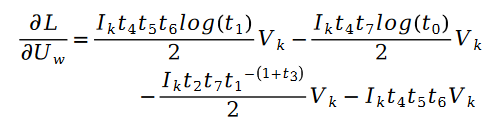
其中:
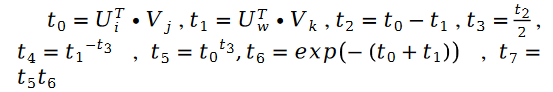
對于未知參數變量 V 的求解類似,我們有如下公式:
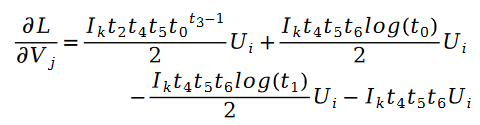
其中:
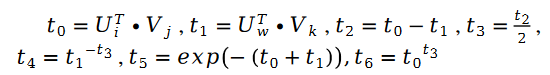
另外有:

其中:
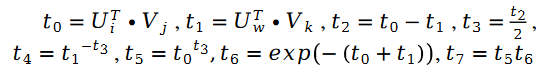
整個算法的流程,我們用如下的偽代碼進行展示:

為了驗證算法的有效性,論文作者在 MovieLens 1 Million Dataset 和 LDOS-CoMoDa Dataset 上進行了測試。第一個數據集包含了 6040 個用戶和 3706 部電影的評分,整個評分數據集大概有 100 萬評分數據,是推薦系統領域最知名的評分數據集合之一。第二個數據集合來自斯洛文尼亞,是網上不多見的基于場景的推薦系統數據集合。該數據集合包含了 121 個用戶和 1232 部電影的評分。作者將斯奇拉姆排序和另外 9 種推薦系統算法進行了對比,主要測評指標為 MAE (Mean Absolute Error,用來測試準確性)和 Degree of Matthew Effect (主要用來測試公平性):
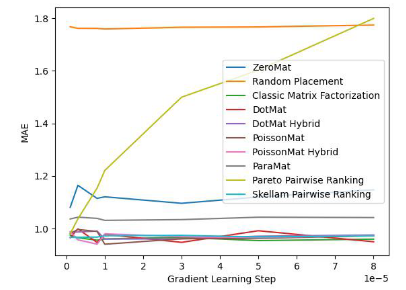
圖 1. MovieLens 1 Million Dataset (MAE 指標)
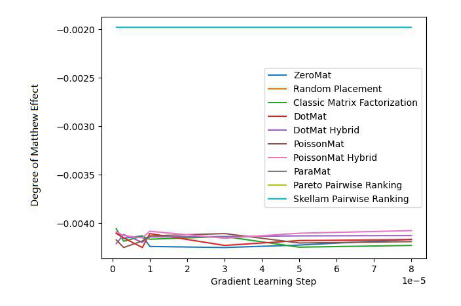
圖 2. MovieLens 1 Million Dataset (Degree of Matthew Effect 指標)
通過圖 1 和圖 2 ,我們發現斯奇拉姆排序在 MAE 這一項指標上表現優異,但在 Grid Search 的整個實驗過程中,無法一直保證性能優于其他算法。但是在圖 2 中,我們發現斯奇拉姆排序在公平性指標上一騎絕塵,遙遙領先于另外 9 種推薦系統算法。
下面我們看一下該算法在 LDOS-CoMoDa 數據集合上的表現:
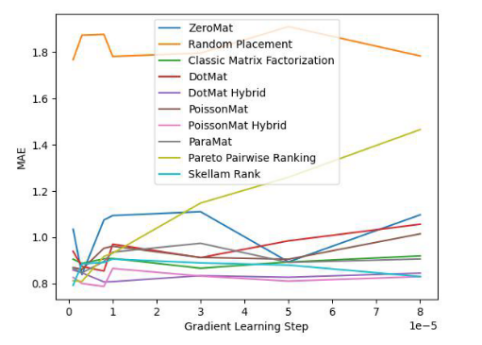
圖 3. LDOS-CoMoDa Dataset (MAE 指標)
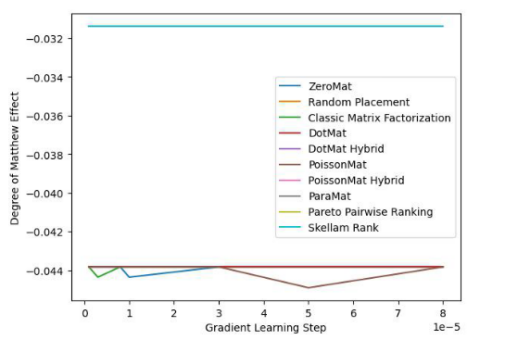
圖 4. LDOS-CoMoDa Dataset (Degree of Matthew Effect 指標)
通過圖3和圖4,我們了解到斯奇拉姆排序在公平性指標上一騎絕塵,在準確性指標上表現優異。結論和上一個實驗類似。
斯奇拉姆排序結合了泊松分布、矩陣分解和 Pairwise Ranking 等概念,是一個不可多得的推薦系統排序學習算法。在技術領域,掌握排序學習技術的人只占掌握深度學習的人的人數的1/6,因此排序學習屬于稀缺技術。而能夠在推薦系統領域發明原創性排序學習的人才更是少之又少。排序學習算法,把人們從評分預測的狹隘視角中解放了出來,讓人們意識到最重要的事情是順序,而不是分值。基于公平性的排序學習,目前在信息檢索領域中大火,特別是 SIGIR 等頂會,非常歡迎基于公平性的推薦系統的論文,希望能夠得到讀者們的關注。
作者簡介
汪昊,前 Funplus 人工智能實驗室負責人。曾在 ThoughtWorks、豆瓣、百度、新浪等公司擔任技術和技術高管職務。在互聯網公司和金融科技、游戲等公司任職 12 年,對于人工智能、計算機圖形學和區塊鏈等領域有著深刻的見解和豐富的經驗。在國際學術會議和期刊發表論文 42 篇,獲得IEEE SMI 2008 最佳論文獎、ICBDT 2020 / IEEE ICISCAE 2021 / AIBT 2023 最佳論文報告獎。




















