讓數據庫和緩存數據保持一致的三種策略
一、背景
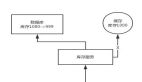
目前隨著緩存架構方案越來越成熟化,通常做法是引入「緩存」來提高讀性能,架構模型就變成了這樣:
 圖片
圖片
先來看一下什么時候創建緩存,前端請求的讀操作先從緩存中查詢數據,如果沒有命中數據,則查詢數據庫,從數據庫查詢成功后,返回結果,同時更新緩存,方便下次操作。
在數據不發生變更的情況下,這種方式沒有問題,如果數據發生了更新操作,就必須要考慮如何操作緩存,保證一致性。
如何保證緩存和數據庫的一致性,這算得上是個老生常談的話題啦,看到好多技術新人在寫更新緩存數據代碼,采用了非常復雜甚至“詭異”的方案,甚為不解。
今天就一起花點兒時間來聊聊吧~
二、緩存和數據庫數據一致性問題
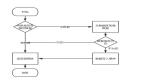
(1)先更新緩存,后更新數據庫
如果緩存更新成功了,但數據庫更新失敗,那么此時緩存中是最新值,但數據庫中是「舊值」。
雖然此時讀請求可以命中緩存,拿到正確的值,但是,一旦緩存「失效」,就會從數據庫中讀取到「舊值」,重建緩存也是這個舊值。
這時用戶會發現自己之前修改的數據又「變回去」了,對業務造成影響。
(2)先更新數據庫,后更新緩存
如果數據庫更新成功了,但緩存更新失敗,那么此時數據庫中是最新值,緩存中是「舊值」。
之后的讀請求讀到的都是舊數據,只有當緩存「失效」后,才能從數據庫中得到正確的值。
這時用戶會發現,自己剛剛修改了數據,但卻看不到變更,一段時間過后,數據才變更過來,對業務也會有影響。
可見,上面兩種情況,無論誰先誰后,但凡后者發生異常,就會對業務造成影響。那怎么解決這個問題呢?
三、緩存更新Design Pattern
介紹幾個也許有效的套路給大家吧~ 希望有幫助。
(1)Cache Aside Pattern
 圖片
圖片
 圖片
圖片
如上圖所示,一個是查詢操作,一個是更新操作的并發。
首先,沒有了刪除cache數據的操作了,而是先更新了數據庫中的數據,此時,緩存依然有效,所以,并發的查詢操作拿的是沒有更新的數據,但是,更新操作馬上讓緩存的失效了,后續的查詢操作再把數據從數據庫中拉出來。而不會像文章開頭的那個邏輯產生的問題,后續的查詢操作一直都在取舊數據。
那么,是不是Cache Aside這個就不會有并發問題了?
不是的。
比如,一個是讀操作,但是沒有命中緩存,然后就到數據庫中取數據,此時來了一個寫操作,寫完數據庫后,讓緩存失效,然后,之前的那個讀操作再把老的數據放進去,所以,會造成臟數據。
(2)Read/Write Through Pattern
- Read Through
Read Through 套路就是在查詢操作中更新緩存,也就是說,當緩存失效的時候(過期或LRU換出),Cache Aside是由調用方負責把數據加載入緩存,而Read Through則用緩存服務自己來加載,從而對應用方是透明的。
- Write Through
Write Through 套路和Read Through相仿,不過是在更新數據時發生。當有數據更新的時候,如果沒有命中緩存,直接更新數據庫,然后返回。如果命中了緩存,則更新緩存,然后再由Cache自己更新數據庫(這是一個同步操作)
操作邏輯如下圖所示:
 圖片
圖片
(3)Write Behind Caching Pattern
基本邏輯如下:
 圖片
圖片
Write Behind 又叫 Write Back。
簡單說就是,在更新數據的時候,只更新緩存,不更新數據庫,而我們的緩存會異步地批量更新數據庫。這個設計的好處就是讓數據的I/O操作飛快無比(直接操作內存的嘛 ),因為異步,write backg還可以合并對同一個數據的多次操作,所以性能的提高是相當可觀的。
但是,其帶來的問題是,數據不是強一致性的,而且可能會丟失(我們知道Unix/Linux非正常關機會導致數據丟失,類似這種情況)。
另外,Write Back實現邏輯比較復雜,因為他需要track有哪些數據是被更新了的,需要刷到持久層上。操作系統的write back會在僅當這個cache需要失效的時候,才會被真正持久起來,比如,內存不夠了,或是進程退出了等情況,這又叫lazy write。
四、總結
對于這個老生常談的問題,分析起來其實并不簡單。
額外分享幾點自己心得給你:
1、性能和一致性不能同時滿足,為了性能考慮,通常會采用「最終一致性」的方案;
2、掌握緩存和數據庫一致性問題,核心問題有 3 點:緩存利用率、并發、緩存 + 數據庫一起成功問題;
3、失敗場景下要保證一致性,常見手段就是「重試」,同步重試會影響吞吐量,所以通常會采用異步重試的方案;
4、訂閱變更日志的思想,本質是把權威數據源(例如 MySQL)當做 leader 副本,讓其它異質系統(例如 Redis / Elasticsearch)成為它的 follower 副本,通過同步變更日志的方式,保證 leader 和 follower 之間保持一致。
面講到的幾種緩存更新的設計方式,都是前人總結出來的經驗,這些方式或多或少都有一些弊端,并不完美,實際上也很難有完美的設計。大家在做系統設計的時候,也不要去追求完美,要有一些取舍,找到一種最適合自己業務場景的方式就行。
 圖片
圖片