作者 | 崔皓
審校 | 重樓
摘要

本文介紹了一種基于LangChain的新技術LangGraph,它通過循環圖協調大模型和外部工具,解決復雜任務。首先,介紹了LangChain的DAG模型處理簡單任務,以及LangGraph使用循環圖處理復雜任務的原理。然后,詳細闡述了LangGraph的三個核心組成部分:狀態圖StateGraph、節點Nodes和邊Edges。最后,通過一個實例演示了如何使用LangGraph查詢北京2024年春節的旅游情況,包括創建代理、定義圖狀態、節點和邊,以及執行工作流。
開篇
在當今的技術領域,大型語言模型(Large Language Models, LLMs)已經逐漸成為我們日常生活和工作中的得力助手。無論是寫作輔助、編程調試,還是簡單的問答系統,LLMs都能夠提供快速且準確的服務。然而,當面對一些更為復雜的任務時,LLMs可能就顯得力不從心。為了解決這些挑戰,我們引入了LangGraph,這是一種結合了人工智能代理(AI Agents)的新技術,旨在處理更為復雜的任務和交互。
LangGraph是建立在LangChain之上,與其生態系統完全兼容的新庫。它通過引入循環圖的方法,協調大模型和外部工具,從而解決應用場景中的復雜問題。
在本篇文章中,我們將通過一個簡單的例子——詢問北京2024年春節期間的旅游情況——來展示如何創建一個屬于自己的LangGraph應用。我們將一步步地引導您了解LangGraph的概念、組成部分,以及如何將其應用于實際場景中。通過這個例子,您將能夠直觀地看到LangGraph如何提高工作效率,解決復雜問題。
什么需要使用LangGraph
使用過LangChain的朋友都知道,LangChain的核心優勢在于其能夠輕松構建自定義鏈,這些鏈通常是線性的,類似于有向無環圖(DAG)。DAG是一種數據結構,其中任務按照一定的順序執行,每個任務只有一個輸出和一個后續任務,形成一個沒有循環的線性流程。例如,當我們從向量庫中搜索內容時,我們首先輸入提示詞,然后通過向量比對進行搜索,并返回結果,這個過程就是一個典型的DAG,每個步驟都嚴格按順序執行。
有向無環圖(DAG)是數據編排和工作流管理系統中的一個基本概念。它代表了一組具有依賴關系和關聯關系的任務,指明了執行的順序。在DAG中,任務被視為節點,節點之間的有向邊表示了它們之間的依賴關系,確保了一個任務只有在它的前驅任務成功完成后才會運行。
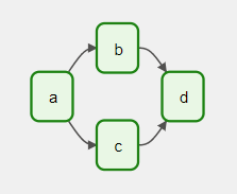
例如,一個基本的有向無環圖可能會定義任務A、B、C和D,并明確指出它們的執行順序和依賴關系。這種結構不僅指出了哪些任務必須先于其他任務執行,而且還指定了調度參數,比如從明天開始每5分鐘運行一次DAG,或者從2024年1月1日開始每天運行一次。
DAG的主要關注點并不是任務內部的運作機制,而是它們應該如何執行,包括執行的順序、重試邏輯、超時以及其他操作方面的問題。這種抽象使得創建復雜的工作流變得容易管理和監控。
然而,并非所有任務都如此簡單。在遇到復雜任務時,比如第一次搜索沒有找到想要的內容,我們可能需要進行第二次、第三次搜索,甚至可能需要調用網絡搜索來完成。在這種情況下,順序執行的任務(DAG)顯然無法滿足需求。此時,請求方和搜索方之間需要經歷多次來回溝通,請求方可能會要求搜索方根據反饋調整搜索策略,這種多次的循環溝通才能逐步逼近最終答案。
這種情況下,我們需要的不再是DAG,而是一個循環圖,它能夠描述多個參與者之間的多輪對話和互動,以確認最終的答案。這種循環圖能夠處理更模糊、更復雜的用例,因為它允許系統根據反饋進行調整和迭代。那么,在循環圖的運行模式就是智能代理,也就是AI Agent。
AI Agent,即人工智能代理,是一種基于強化學習理論設計的系統。如下圖所示,強化學習是一種機器學習方法,它使智能體(Agent)能夠根據環境的不同狀態(State)采取行動(Action),目的是獲取最大程度的獎勵(Reward)。這種學習過程涉及到智能體與環境的不斷互動,通過嘗試和錯誤來學習哪種行動策略能夠帶來最佳的結果。
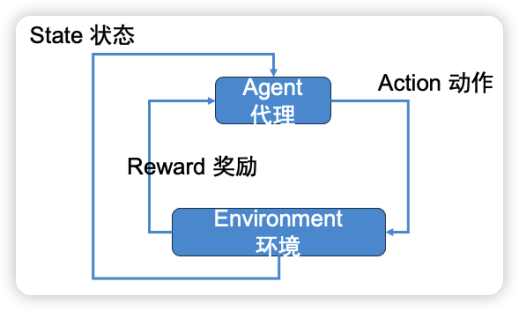
例如,在微信的跳一跳游戲中,智能體每次成功跳上平臺都會獲得獎勵,而未能跳上平臺則會受到懲罰。通過這種獎勵和懲罰機制,智能體能夠學習如何調整跳躍的力量和方向,以獲得更高的分數。這個過程就是強化學習的一個簡單體現,智能體通過不斷的互動來優化其行動策略。
在LangGraph中,AI Agent的工作原理類似。LLM(大型語言模型)用于確定要采取的行動和向用戶提供的響應,然后執行這些行動,并返回到第一步。這個過程會重復進行,直到生成最終的響應。這就是LangChain中核心AgentExecutor的工作循環原理。
然而,在實際應用過程中,我們發現需要對智能代理進行更多的控制。例如,我們可能希望智能代理始終首先調用特定工具,或者我們可能希望對工具的調用方式有更多的控制,甚至可能希望根據智能代理的狀態使用不同的提示。為了解決這些問題,LangGraph提出了“狀態機”的概念。通過狀態機為圖創建對應的狀態機,這種方法可以更好地控制智能代理的行動流程,使其更加靈活和有效地處理復雜任務。
LangGraph的組成部分
在介紹LangGraph如何通過應用“狀態機”來實現AI Agent功能時,有幾個重要的概念我們需要理解,它們也是LangGraph的重要組成部分。
StateGraph(狀態圖)
首先,需要理解StateGraph這個核心概念。StateGraph是一個類,它負責表示整個圖的結構。我們通過傳入一個狀態定義來初始化這個類,這個狀態定義代表了一個中心狀態對象,它會在執行過程中不斷更新。這個狀態對象由圖中的節點更新,節點會以鍵值對的形式,返回對狀態屬性的操作。
狀態對象的屬性可以通過兩種方式更新:
1. 覆蓋更新:如果一個屬性需要被新的值替換,我們可以讓節點返回這個新值。
2. 增量更新:如果一個屬性是一個動作列表(或類似的操作),我們可以在原有的列表上添加新的動作。
在創建狀態定義時,我們需要指定屬性的更新方式,是覆蓋還是增量。
如果StateGraph的概念不好理解,可以想象一下你正在組織一次旅行。你設定了旅行的一些基本信息,比如確定目的地、預定航班和預定酒店。這些信息就像是一個中心狀態對象,隨著你計劃的進展,它會不斷更新。比如,你可能會添加新的活動到你的行程中,或者修改你的預算。這些更新就像是圖中的節點,它們對你的旅行計劃狀態對象進行操作。
在LangGraph中,StateGraph類就是這樣的旅行計劃,而節點就像是規劃旅行的不同步驟,比如確定目的地、預定航班和預定酒店。每個步驟都會更新你的旅行計劃,可能是完全替換舊的計劃,也可能是添加新的信息到現有的計劃中。
Nodes(節點)
說完了StateGraph,我們來關注圖的節點部分。在創建了StateGraph之后,我們需要向其中添加Nodes(節點)。添加節點是通過`graph.add_node(name, value)`語法來完成的。
其中,`name`參數是一個字符串,用于在添加邊時引用這個節點。`value`參數應該可以是函數或者LCEL(LangChain Expression Language)可運行的實例,它們將在節點被調用時執行。它們可以接受一個字典作為輸入,這個字典的格式應該與State對象相同,在執行完畢之后也會輸出一個字典,字典中的鍵是State對象中要更新的屬性。說白了,Nodes(節點)的責任是“執行”,在執行完畢之后會更新StateGraph的狀態。
接著,上面旅行計劃的例子,Nodes(節點)就好像旅行計劃中需要完成的任務,例如:預定航班、預訂酒店。Nodes(節點)接受旅行計劃(State對象)作為輸入,并輸出一個更新后的任務狀態,例如:完成酒店的預訂。
換句話說為了完成復雜任務,我們會在StateGraph中添加很多Nodes(節點)。每個節點都代表一個任務,它們執行的結果會影響StateGraph的狀態。這些節點通過邊相互連接,形成了一個有向無環圖(DAG),確保了任務的正確執行順序。
Edges(邊)
說了StateGraph之后就不得不提到Edge(邊)了。在LangGraph中,Edges(邊)是連接Nodes(節點)并定義StateGraph(狀態圖)中節點執行順序的關鍵部分。添加節點后,我們可以添加邊來構建整個圖。邊有幾種類型:
- 起始邊(Starting Edge):這個邊確定了圖的開始,比如在旅行計劃中,起始邊就是確定你的目的地。一旦目的地被確定,你的旅行計劃就可以開始執行了。
- 普通邊(Normal Edges):這些邊表示一個節點總是要在另一個節點之后被調用。在旅行計劃中,普通邊就像是確定了任務執行的順序。例如,在找到合適的航班之后,你可能會決定預訂酒店。這個順序確保了任務的有序執行。
- 條件邊(Conditional Edges):使用函數(通常由LLM提供)來確定首先調用哪個節點。在旅行計劃中,條件邊就像是根據你的喜好或者天氣情況來決定你的下一步行動。比如,如果你發現沒有合適的航班,你可能會選擇推遲預訂酒店,而去查找火車車票。條件邊提供了靈活性,使得系統可以根據不同的情況來調整執行的順序。
在LangGraph中,邊(Edges)是連接節點(Nodes)并定義圖(Graph)中節點執行順序的關鍵部分。邊可以看作是對節點的控制和鏈接,它們確保了圖中的任務按照預定的順序執行。
在LangGraph中,邊定義了節點之間的依賴關系和執行順序。起始邊確定了圖的開始,普通邊確保了任務的正確執行順序,而條件邊則根據特定的條件來決定下一步的操作。
LangGraph 實戰
前面對LangGraph的設計原理以及基本組成部分有了簡單的了解, 接下來,我們通過一個例子來感受一下,如何實際使用LangGraph查詢北京2024年春節的旅游情況。熟悉大模型的朋友可能知道,大模型的短板就是對實時的信息一無所知,如果要攝入新的知識必須經過新數據集的訓練才行。因此,我們會使用LangGraph調用網絡搜索功能獲取實時信息。
創建LangChain 代理
在LangChain中代理是利用大模型作為推理引擎來確定采取的行動序列,與在鏈中硬編碼的一系列行動不同。說白了,就是執行這次任務的“關鍵人物”, 他作為“查詢北京2024年春節的旅游情況”任務的總負責,最后給用戶提供結果。
# 從langchain包中導入hub對象,該對象用于內容管理和檢索
from langchain import hub
# 從langchain包中導入創建OpenAI函數代理的函數
from langchain.agents import create_openai_functions_agent
# 從langchain_openai包中導入ChatOpenAI類,用于與OpenAI聊天模型交互
from langchain_openai.chat_models import ChatOpenAI
# 從langchain_community包中導入TavilySearchResults類,提供搜索功能
from langchain_community.tools.tavily_search import TavilySearchResults
# 創建一個工具列表,其中包含TavilySearchResults實例,限制最大搜索結果為1
tools = [TavilySearchResults(max_results=1)]
# 通過hub對象的pull方法檢索語句提示,langchain hub 維護了很多prompt,這些prompt 是針對不同應用場景而創建的
# 作為用戶,你也可以在hub中上傳你構建的prompt
prompt = hub.pull("hwchase17/openai-functions-agent")
# 打印獲取的提示
print(prompt)
# 初始化一個Large Language Model(LLM)聊天實例,使用GPT-3.5 Turbo模型,并啟用流模式和自定義API基礎URL
llm = ChatOpenAI(model="gpt-3.5-turbo-1106", streaming=True)
# 使用LLM,工具和提示信息創建OpenAI函數代理,形成一個可運行的代理
agent_runnable = create_openai_functions_agent(llm, tools, prompt)針對上述代碼進行解釋如下:
1. `from langchain import hub` - 從`langchain`包中導入`hub`對象,langchain hub 維護了很多prompt,這些prompt 是針對不同應用場景而創建的。作為用戶,你也可以在hub中上傳你構建的prompt。
2. `from langchain.agents import create_openai_functions_agent` - 從`langchain`包中導入`create_openai_functions_agent`函數,這個函數用來創建基于OpenAI函數的代理(agent)。
3. `from langchain_openai.chat_models import ChatOpenAI` - 從`langchain_openai`包中導入`ChatOpenAI`類,這個類用于與OpenAI聊天模型進行交互。
4. `from langchain_community.tools.tavily_search import TavilySearchResults` - 從`langchain_community`包中導入`TavilySearchResults`類,該類用于提供搜索結果的功能。
5. `tools = [TavilySearchResults(max_results=1)]` - 創建一個列表`tools`,其中包含一個`TavilySearchResults`實例,這個實例限制搜索結果的數量為最多1個。這里我們需要通過Tavily的工具實現互聯網搜索。
6. `prompt = hub.pull("hwchase17/openai-functions-agent")` - 通過`hub`對象的`pull`方法檢索一個名為`hwchase17/openai-functions-agent`的語句提示。
7. `print(prompt)` - 打印出獲取的提示內容。
8. `llm = ChatOpenAI(model="gpt-3.5-turbo-1106", streaming=True)` - 初始化一個Large Language Model(LLM)的聊天實例,指定使用`gpt-3.5-turbo-1106`模型,并啟用流模式。
9. `agent_runnable = create_openai_functions_agent(llm, tools, prompt)` - 創建一個OpenAI函數代理,它能夠根據給定的LLM實例、工具列表以及提示信息運行。
這段代碼的目的是初始化并配置一個與OpenAI 聊天模型進行交互的環境。首先,它導入了所需的模塊和類,包括內容管理的`hub`對象、創建OpenAI 函數代理的`create_openai_functions_agent`函數、與OpenAI 聊天模型交互的`ChatOpenAI`類和提供搜索功能的`TavilySearchResults`類。然后,代碼創建了工具列表,并從`langchain hub`中拉取了一個預先定義的提示。
這里我們將prompt 的打印結果,貼圖如下:
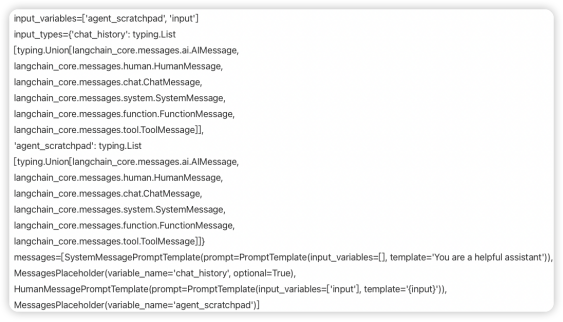
這個prompt來自于LangChain hub,用于發現、分享不同的大模型提示詞。這里我們使用的就是別人定義好的提示詞模版。它定義了用于生成代理(agent)操作的輸入變量和信息類型(messages)。下面逐個解釋顯示的`prompt`內容:
1. `input_variables=['agent_scratchpad', 'input']` - 這里指定了輸入變量列表,包括`agent_scratchpad`和`input`。
2. `input_types` - 這是一個定義了不同輸入類型的字典,包括以下鍵和對應的類型:
- chat_history: 表述聊天歷史記錄的類型,是一個包含各種消息類型的列表。這些消息類型可能包括AI消息、人類發送的消息、聊天消息、系統消息、函數消息和工具消息。
- `agent_scratchpad`: 代表代理的“草稿本”,用來記錄過程中的信息,類型與`chat_history`相同,包含多種可能的消息類型。
3. `messages` - 這是一個包含多個不同類型模板的列表:
- `SystemMessagePromptTemplate` - 包含一個`SystemMessage`類型模板,用于定義系統消息。這里的``You are a helpful assistant``是指示agent的角色和期望行為的提醒。
- `MessagesPlaceholder` - 是一個占位符,與 `chat_history` 變量相關聯,并且它是可選的,這意味著在輸入中不一定需要提供聊天歷史。
- `HumanMessagePromptTemplate` - 包含一個`HumanMessage`類型的模板,用來定義來自用戶的輸入。這里的模板`{input}`將會被用戶輸入的實際文本替換。
- `MessagesPlaceholder` - 另一個占位符,與 `agent_scratchpad` 變量相關聯。
它定義了代理(agent)如何處理消息和交互。當使用代理執行任務時,這個模板將被用來生成符合預設格式的輸入,從而促進代理的正確響應和操作。
而當你使用`langchain hub.pull("hwchase17/openai-functions-agent")`從`langchain hub`中拉取這個prompt template時,你可以使用這個模板來配置你的代理(agent),使其理解并處理定義好的輸入類型和消息格式,以充當一個有效和有用的助手。用戶也可以根據自己的需求創造新的prompt并上傳至`hub`,以適應不同的場景。
創建圖狀態
在創建完代理之后,接著就是定義圖狀態。傳統LangChain代理的狀態具有如下屬性:
- 輸入:這是代表用戶主要請求的輸入字符串,作為輸入傳遞。
- 聊天歷史:這是任何先前的對話消息,也作為輸入傳遞。
- 中間步驟:代理采取的行動和相應的觀察。每次代理迭代時都會更新這個列表。
- 代理結果:代理的響應,可以是AgentAction或AgentFinish。當這是AgentFinish時,AgentExecutor應該結束,否則應該調用請求的工具。
代碼如下:
from typing import TypedDict, Annotated, List, Union
from langchain_core.agents import AgentAction, AgentFinish
from langchain_core.messages import BaseMessage
import operator
# 定義一個類型字典,用于表示代理的狀態信息
class AgentState(TypedDict):
# 輸入字符串
input: str
# 對話中之前消息的列表
chat_history: list[BaseMessage]
# 代理調用產生的結果,可能為None表示開始時沒有結果
agent_outcome: Union[AgentAction, AgentFinish, None]
# 動作和對應觀察結果的列表,使用operator.add注釋說明這些狀態應該被添加到現有值上
intermediate_steps: Annotated[list[tuple[AgentAction, str]], operator.add]上面代碼需要說明的是:
- agent_outcome: Union[AgentAction, AgentFinish, None]:這個字段存儲代理在某次調用后的結果狀態。說明我們需要關注AgentAction對象(代表代理執行了某個動作)和AgentFinish對象(表明代理完成了其任務),以及None(表示代理尚未開始處理任務或沒有需要返回的結果)。
- intermediate_steps: Annotated[list[tuple[AgentAction, str]], operator.add]:這是動作和觀察結果組成的元組列表,通過Annotated和operator.add進行了注釋。這表明要更新intermediate_steps這個字段時,應該是將新的動作和觀察結果加到列表中,而不是覆蓋現有的列表。operator.add用于提示這個字段的更新操作是添加性質的。
定義節點
在介紹了如何創建圖狀態之后,接下來要關注的是如何定義節點。在LangGraph中,節點可以是函數或可運行實體。針對我們的任務,我們需要定義兩個主要節點:
- 代理節點:負責決定要采取什么行動。
- 調用工具的函數:如果代理決定采取行動,那么這個節點將執行該行動。這里的行動可以理解為通過Tavily進行網絡搜索,獲取“北京2024年春節的旅游情況”。
除了定義節點,我們還需要定義一些邊。其中一些邊可能是有條件的。這些邊之所以有條件,是因為根據節點的輸出,可能會采取幾條不同的路徑。而具體路徑需要在運行節點時由大模型來確定。
有條件邊:確定在調用代理后,如何動作。如果代理需要行動,那么應該調用工具;如果代理認為已經完成任務,那么它就應該結束。
普通邊:在調用工具后,它應該始終返回到代理,以決定接下來要做什么。
現在,讓我們定義節點,以及函數來決定采取哪種有條件邊。函數將根據代理節點的輸出,決定是調用工具還是結束流程。通過這種方式,可以構建一個靈活的圖,能夠根據不同的情況選擇合適的路徑。
# 導入AgentFinish類,用于標識代理執行完成狀態
from langchain_core.agents import AgentFinish
# 導入ToolExecutor類,用于執行工具和處理代理動作
from langgraph.prebuilt.tool_executor import ToolExecutor
# 實例化ToolExecutor,它是一個輔助類,能夠基于代理動作調用相應的工具并返回結果
tool_executor = ToolExecutor(tools)
# 定義代理執行邏輯的函數
def run_agent(data):
# 調用代理的可執行對象,傳入數據data,執行代理邏輯并得到結果
agent_outcome = agent_runnable.invoke(data)
# 將代理的執行結果封裝成字典形式返回
return {"agent_outcome": agent_outcome}
# 定義執行工具的函數
def execute_tools(data):
# 從數據中獲取最新的代理執行結果(agent_outcome)
agent_action = data["agent_outcome"]
# 調用工具執行器,并基于代理動作執行工具,得到輸出結果
output = tool_executor.invoke(agent_action)
# 將執行的工具及其輸出結果作為中間步驟打包成元組,然后封裝成字典格式返回
return {"intermediate_steps": [(agent_action, str(output))]}
# 定義邏輯函數,用于根據數據決定流程是否繼續或結束
def should_continue(data):
# 如果代理的執行結果是AgentFinish,表示結果滿意,代表流程結束
if isinstance(data["agent_outcome"], AgentFinish):
# 返回字符串'end',在設置流程圖時用于標識流程的終點
return "end"
# 如果代理的執行結果不是AgentFinish類的實例,則代表代理流程應繼續執行
else:
# 返回字符串'continue',在設置流程圖時用于標識流程的繼續點
return "continue"從上面的代碼可以看出,定義了三個函數。
- run_agent:用來接收數據并且執行代理。
- execute_tools:接收數據執行具體操作,在本例中用來通過搜索引擎搜索2024年春節與北京旅游相關的信息。同時,還通過intermediate_steps 記錄執行的結果。由于在實際工作環境中,agent 都是發號施令的一方,而具體干活的是tools。每次tools 完成工作(本例是網絡搜索)之后,都會返回信息,此時agent都會對返回的信息進行判斷,如果不滿意tools還要繼續“工作”。基于這樣的情況,每次tools 工作完畢都將結果記錄到intermediate_steps中,做為存檔或者是依據。
- should_continue:用來判斷工作流是否繼續,如果得到了結果data["agent_outcome"],那么就結束工作,否則繼續工作,直到拿到結果。
定義工作流(圖和邊)
到這里我們有了代理、圖狀態、節點等信息了。為了把上述信息串聯起來,需要構建一個基于狀態的工作流(workflow)。工作流中包含的是有條件的和線性的節點轉換,用于根據某些條件決定程序的下一步執行哪個操作。這個過程模擬了一個基于事件的系統,其中不同的狀態(或稱為節點)可以根據特定邏輯進行轉換。代碼如下:
from langgraph.graph import END, StateGraph
#通過stategraph 初始化工作流
workflow = StateGraph(AgentState)
# 定義兩個節點,在實際場景中agent下命令,action完成任務返回結果。
# 結果如果不滿意,agent 會繼續要action完成新任務。
# 看上去它們的交互式不斷循環切換的
workflow.add_node("agent", run_agent) # 添加節點"agent",其運行函數為 run_agent
workflow.add_node("action", execute_tools) # 添加節點"action",其運行函數為 execute_tools
# 設置入口節點為 `agent`
# 這意味著首先調用的節點是`agent`
workflow.set_entry_point("agent")
# 接下來添加有條件的邊
workflow.add_conditional_edges(
# 定義起始節點,這里使用`agent`
"agent",
# 判斷是否繼續的函數節點,用于決定下一個節點是哪個的函數
should_continue,
# 定義映射字典
# 鍵為字符串,值為其他節點
# END 是結束節點
# 調用`should_continue`后,輸出將根據這個映射找到匹配的鍵
# 根據匹配結果,接下來會調用相應的節點
{
# 如果是`continue`,則調用工具節點`action`
"continue": "action",
# 否則結束流程
"end": END,
},
)
# 添加普通邊從`action`到`agent`
# 這意味著在`action`被調用后,下一個調用的節點是`agent`
workflow.add_edge("action", "agent")
# 對工作流進行編譯
# 編譯成 LangChain 可運行對象
# 可以這個對象
app = workflow.compile()代碼比較長,我們對其進行拆解并解釋如下:
- 定義工作流:使用StateGraph創建了一個名為workflow的新工作流實例,這個工作流將要基于一種名為AgentState的狀態。
- 添加節點:向工作流中添加了兩個節點("agent"和"action"),它們分別關聯了各自的處理函數run_agent和execute_tools。
- 設置入口點:"agent"被設置為工作流的入口點,這意味著它是工作流開始執行時第一個被調用的節點。
- 添加有條件的邊:通過add_conditional_edges方法,為從"agent"節點出發的邊添加了條件。
- 使用should_continue函數來評估條件,根據返回值決定下一個執行哪個節點。
- 如果should_continue返回"continue",流程將移動到"action"節點;如果返回"end",則工作流將結束。
- 添加普通邊:通過add_edge方法添加了一個從"action"到"agent"的單向邊。這個邊代表在"action"節點執行后,下一步將回到"agent"節點繼續執行。
- 編譯工作流:最后,通過調用compile方法,將之前定義的工作流編譯成一個可執行的對象app。
這段代碼定義了工作流,加入了節點,并且設計了邊,我們通過下面這張圖來理解其原理。Agent作為整個工作流進入的節點,在最左側。Agent和Action組成了一個普通邊,這個很好理解,由Agent發起搜索任務,而Action是來完成這個任務的。接著,Agent 與should_continue 函數,通過設置條件創建了一個條件邊。Should_continue函數本身不是節點,只是一個判斷條件,從函數內容中可以看出,如果Action得到結果就結束工作流(End),否則就繼續執行搜索任務(continue)。為了便于理解,我們用棱形來表示,當Action執行之后通過should_continue 進行判斷,然后選擇正確的分支。如果選擇continue這條,就意味著整個工作流形成了一個環,如果Action的工作一直無法should_cointnue ,也就是一直不能讓Agent滿意的話,就需要不斷重復執行搜索工作,直到超過執行次數從而退出。
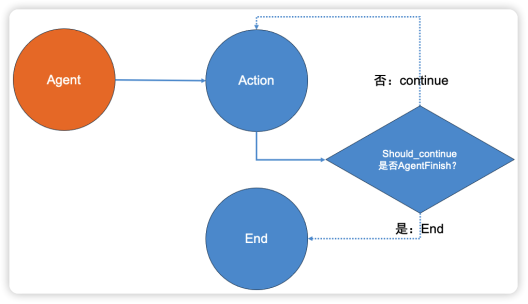
執行搜索任務
通過上面一頓操作,工作流已經創建完畢,接著就可以執行它了。上代碼:
inputs = {"input": "2024年春節北京的旅游情況如何", "chat_history": []}
for s in app.stream(inputs):
print(list(s.values())[0])
print("----")我們詢問“2024年春節北京的旅游情況如何”,通過工作流實例輸出結果如下圖所示:
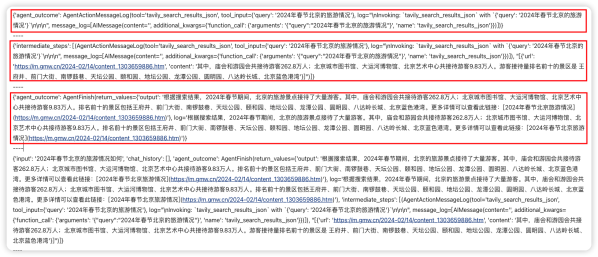
第一個agent_outcome,很明顯在agent發出命令的時候,tavily搜索工具開始工作。
接著,tavily 搜索工具記錄搜索的中間步驟,包括從什么網站地址獲取了相關信息。此時第二個agent_outcome 的內容標志為AgentFinish,意思是Agent對結果是滿意的,因此可以結束任務了,同時給出了搜索的最終結果,和我們的預期保持一致。
總結
LangGraph技術在處理復雜任務方面具有明顯優勢,通過循環圖的方式,使大模型和外部工具協同工作,實現多輪對話和調整,從而更好地逼近最終答案。該技術具有廣闊的應用前景,能夠顯著提高工作效率和解決問題的能力。不過,創建LangGraph應用也需要一定的技術門檻,需要理解狀態圖、節點和邊的概念,并編寫相應的代碼實現。未來,LangGraph有望成為處理復雜任務的重要技術手段。
作者介紹
崔皓,51CTO社區編輯,資深架構師,擁有18年的軟件開發和架構經驗,10年分布式架構經驗。